 jodator
commented
4 years ago
jodator
commented
4 years ago Hey, @loagit - thanks for that detailed explanation of why our docs are confusing to you. We know that the conversion process is probably the hardest to understand (and to explain) in the CKEditor 5 architecture. We know that writing converters are very tricky and that we need to update the docs.
Below are my thoughts on those things, so if you ask somebody else from the team you might get slightly different answer ;)
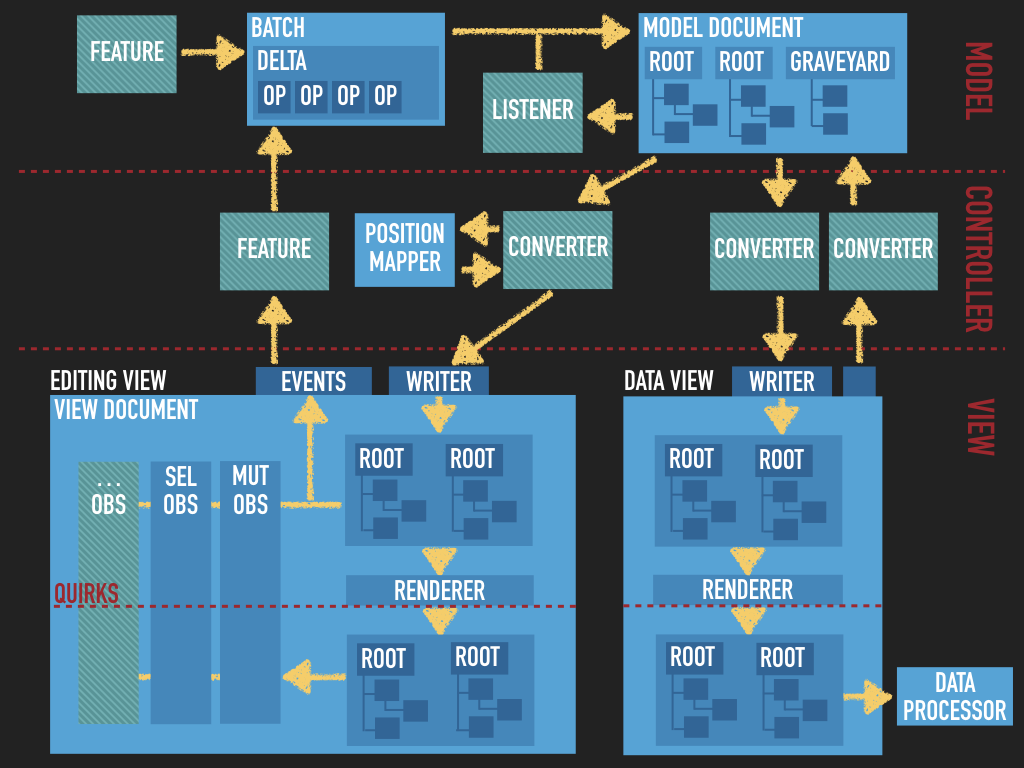
From my perspective you can think about that whole process as below:
-
The
Modelrepresents the content in a way that is easier to process, implement collaboration features, etc. It also detaches the structure of the document from the DOM/HTML. All the changes in the document are done on the Model. -
The
Viewis the part that is used to present theModeland is also used to interact with it. -
The
EditingViewis used in the editing area of the editor. It is used to render the model to the view (during theeditingDowncast) and to reflect user interaction with the content (inside the DOM contenteditable area) back to the model. -
The
DataViewis used when you set (most commonlyeditor.setData( '<p>foo</p>' ) )or get data from the editor (ie, wheneditor.getData()to store the editor content in a DB). -
The conversion process happens when you transform
Modelrepresentation to theViewor vice versa. Taking the above you can have:5a. The
upcastconversion which happens when you transform your data (View) (ie HTML but can be XML if using different data processor) toModelstructure5b. The
editingDowncastconversion is done to representModelstructure in theeditingView5c. The
dataDonwcastconversion happens when you want to take theModelstructure for your application (most commonly you want to get HTML but you can also want Markdown)5d. If your feature content (
Model) is represented the same way in the data (the content used in your application) and in the editing area you don't have to define separate conversion utilities for them and you can usedowncastalias for both. -
Two-way vs One-way: One way is either
ModeltoVieworViewtoModelwhile Two way is a single definition used for bothModeltoViewandViewtoModel(mostly used for straight forward representations):// Two-way converter: conversion.elementToElement( { model: 'paragraph', view: 'p' } ); // is the same as: conversion.for( 'downcast' ).elementToElement( { model: 'paragraph', view: 'p' } ); conversion.for( 'upcast' ).elementToElement( { model: 'paragraph', view: 'p' } ); // and is also the same as: conversion.for( 'editingDowncast' ).elementToElement( { model: 'paragraph', view: 'p' } ); conversion.for( 'dataDowncast' ).elementToElement( { model: 'paragraph', view: 'p' } ); conversion.for( 'upcast' ).elementToElement( { model: 'paragraph', view: 'p' } ); -
Why there's different
editingDowncastanddataDowncast- because we know from previous projects that you might need to represent some editing feature (likeWidget) a bit different in the editing area - where the user interacts it while creating the content - and a bit different in the data you get from the editor. Most commonly we add some additional markup for widgets in the editing area used to style the wiget (all these fancy borders) which aren't need in the data you get from the editor.
@loagit As a bottom line - I'm curious if those remarks are helpful? Do you have a better/worse understanding of what happens there? Can you write how do you see those aspects? Also, did you see various conversion examples?
I'm asking because maybe we could learn something to improve the docs and help others better understand the whole idea behind it.
 loagit
loagit

 scofalik
scofalik
{kind=link}
Hi. I am trying to properly understand how the conversion process between the CKEditor 5 MVC architecture layers happens. In particular, it is a little difficult to know exactly the differences between One-Way Converters and Two-Way Converters.
By reading more about the Editing Engine, you can understand that there are two tree data structures present in CKEditor 5. One represents the "master" data, referred to as Model. This type of structure is organized in a special way (unlike the standard DOM structure) to allow its manipulation to be easier, more viable.
Source
The other tree structure represents the content present in the CKEditor 5 editor, and closely resembles (is) much the familiar DOM. It is in the view layer, and can be called Editing View.
Still according to the documentation (and here I start to get a little lost, probably), there is a third model called Data View. I imagine there is no such model, but a way to represent the data structure present in Editing View as HTML, Markdown, JSON, and so on, and vice versa.
I know that when we are creating new elements for the editor (a custom plugin, for example), we need to perform an upcasting and downcasting process between Model and Editing View. As I understand it, this must be done through the Conversion utility class. In the documentation, two approaches are presented for performing conversions:
Using Two-Way Converters, the conversion process between Model and Editing View is quite simple. With One-Way Converters, on the other hand, it is defined that the conversion must happen through the use of something called Groups of Dispatcher, which can be:
The for method documentation demonstrates the use of only two of the Groups of Dispatcher, and only feature the upcast and downcast process.
That's exactly where I start to get confused, and I know the problem is that I just still don't fully understand how the thing works. What are the differences between Groups of Dispatchers? I say, clearly, simply and practically. In the documentation it is said that they represent conversion directions. Shouldn't there be a conversion only between upcast and downcast? What does dataDowncast mean? And editingDowncast?
I believe upcast is from Editing View to Model, and editingDowncast is from Model to Editing View, the editor's content. dataDowncast... What?
For example, why are 3 converters declared for each of the 3 elements in Implementing a block widget:
Where is the downcast process? Are there two? Something similar can be seen on Implementing a inline widget.
If this kind of information is present somewhere, I apologize, I probably haven't found it yet, I'm new to CKEditor 5. Can anyone help me to better understand all this, please? :(