 jserrano-rebold
commented
5 years ago
jserrano-rebold
commented
5 years ago Hi. I've wrote in pyPDF3 Repo : I am interested in this topic. I have been researching a lot of time and the only way to solve it is to regenerate the PDF using pdftocairo or ghostscript (gs) before merging
 canedha
canedha
This issue has been cross-posted as mstamy2/PyPDF3#11, since it affects both projects.
Note: All PDF described here are available for download at the end of this message.
I have a two-pages PDF file looking like that:
What is not visible here is that I crafted this PDF so that the shapes go over the edges: half the circles and half the squares are not visible (outside the edges). Now, if I run the following script (to put the two pages side by side on a single, bigger page):
I get the following result, which is wrong, because the shapes overflow on the other page.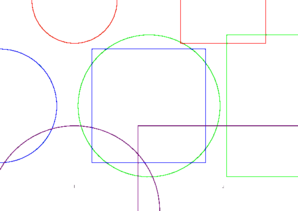
I would like to have the following result, where the source pages are cropped before being merged.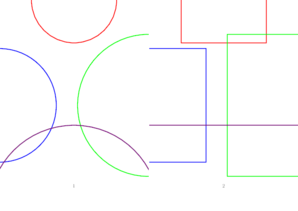
I tried playing with the *boxes (trimBox, bleedBox, cropBox, etc.) but:
Is there a way to get the expected result, that is: crop the source pages, then merge them?
Thanks, -- Louis
Downloads: