 Midqiu
commented
3 years ago
Midqiu
commented
3 years ago 我测试的结果是: 从http页面访问https接口,同samesite下,但协议不一样,用Chrome和Edge测试, Chrome 91 (91.0.4472.101)协议不一样好像也算跨站点,Edge 91 (91.0.864.41)Cookie能正常设置。
Open closertb opened 3 years ago
Midqiu
commented
3 years ago 我测试的结果是: 从http页面访问https接口,同samesite下,但协议不一样,用Chrome和Edge测试, Chrome 91 (91.0.4472.101)协议不一样好像也算跨站点,Edge 91 (91.0.864.41)Cookie能正常设置。
Midqiu
commented
3 years ago 原因找到了,Chrome 改了 samesite 的定义,协议不同也算 跨 site 了。
 closertb
commented
3 years ago
closertb
commented
3 years ago 原因找到了,Chrome 改了 samesite 的定义,协议不同也算 跨 site 了。
学习了,good job
什么样的知识,最好吃?入口即化的
啰里吧嗦的开头
SameSite cookie 推出已一年有余,自己看了不少文章,也撞了不少南墙,所以还是那句好记性不如烂笔头。你可能觉得自己懂了,但试着讲出来,才能知道自己是否真的懂了。
列一列自己看过的文章:
走进SameSite
和新冠一起火了的SameSite
SameSite Cookie行为更新去年就开始被提上日程,2020年2月随着Chrome 80的推出,这个属性开始正式生效,但因为3月份正是全球新冠肆虐的时候,当时的维护者都还活在新冠的恐惧之下,网站没法及时更新,这项政策导致很多网站瘫痪,chrome官方又在4月进行了回滚,暂时终止了这项策略。直到2020年7月14日Chrome 84稳定版开始,重新恢复SameSite cookie策略,并且会逐步部署到Chrome 80以及以上的版本中。
如果你知道CSRF,那你就知道这项攻击真正的核心就是利用 cookie 自动携带的行为(进一步讲就是跨站携带cookie)。
之所以会跨站携带,是因为起初 cookie 的规范中并没有 SameSite 这个属性;直到2016年first-party-cookies草案的推出,但并有多少人真正去用,而浏览器这边的实现也默认是SameSite=None,所以对开发者并没有什么影响,自然就没有引起多大的关注,至少不如这次,而提案初衷:
改善安全和隐私泄露的问题。效果自然就不是很理想。为了解决这些问题,一个新的草案:Incrementally Better Cookies,在草案的开头,就直接说道:
翻译成中文就是两个
改进:first-party-cookies 草案规定了什么
草案那么长,我就关(kan)注(dong)了一段话:
可以简单理解为同站 和 跨站的定义,中文大白话翻译就是:
<script src="/static/index.js"></script>标签,那最后浏览器发出的请求就是:closertb.site/static/index.js,这没得说,肯定是同站;匹配(注意是匹配,不是相等),也是同站;好家伙,感觉说了和没说一样;然后定义了SameSite语义:
但在接下来的几节,并没有出现
Strict、Lax、None这些语义,我猜主要还是这只是一份草稿,还不涉及到具体实现。在最新的RFC6265 替代草案draft-ietf-httpbis-rfc6265bis-05, 提及了这三个属性值,并做了介绍,但貌似还是落后现在浏览器的实现,因为草案中SameSite=None仍然是默认属性;
SameSite 的属性值及其区别
我觉得这部分再讲就是蛋炒饭了,毕竟今年太多人讲过了,没啥意义。
你可以看:阮一峰老师
但更推荐MDN官方的:SameSite cookies
你可以通过:https://samesite-sandbox.glitch.me/ 网站来了解你的浏览器是否开启Incrementally Better Cookies(IBC)
用实例说话,到底限制的是什么?
直到现在,其实很多前端开发者对这个变化是无感的,主要两个原因:
同站的影响是不大的
大多数公司cookie都是用来做单点登录身份鉴权的,这种多数存在同站;比如:
当用户初次打开crm服务网站时,会首先调用鉴权服务查询该用户是否已授权或授权有效?如果无效,就会重定向到sso.closertb.site网站让用户登录授权,授权完成后,服务会在
closertb.site种下几个cookie,用于识别用户身份,然后就重定向回crm.closertb.site网站;当用户再次打开crm服务或其他同站网站时,也会先调用鉴权服务,由于cookie还有效,所以用户就不用再去登录了,可以继续在网站浏览。以上就是一个非常典型的单点登录设计,都是利用浏览器在同站请求会自动携带cookie来做身份识别的方式;
跨站才是重点
但还有一种稍微复杂的情况,跨站单点登录,举个典型的例子:天猫和淘宝
这个情况复杂就复杂在淘宝和天猫是跨站的,当淘宝登录了时,你再去访问天猫,会有一系列的鉴权操作:
但今天不是主讲淘宝天猫的单点登录设计,主要是讲cookie,这里有一个设计,就是跨站cookie的使用;在用户登录了淘宝后,用户再去打开天猫,因为天猫淘宝是一套用户体系,所以他们做了免登,就是截图所示,先是调用了了
top-tmm.taobao.com/login_api.do, 这个请求会携带*.taobao.com域下的cookie, 从而服务端就能知道这个用户登录过。由于请求是在 tmall.com 站点下发出的,所以这是一个跨站请求,这也是这次新规重点照顾的场景。为了在新版本浏览器下,能继续让单点登录有效,所以淘宝的开发也就做点改变来适应,
cookie 都打上了samesite=None与secure标识, 利用改进第二条规则。由于Secure的限制,要携带的跨站点请求必须在带有安全标识站点下发出请求
所以当你输入http://tmall.com,站点302必会重定向到https://tmall.com 安全域名下。
除了上面这种故意设计的跨站,还有很多其他形式,已经有高手总结过,我就发一个我个人觉得比较全的,来自知乎
对开发的影响
虽然我们大多数开发开发的站点都是同站,但在本地调试时,基本都是在
http://localhost:port站点下进行,要拿到登陆态,面临的情况都是跨站。所以为了应对这次更新,一般有两种方法来解决:修改安全限制和修改调试站点域名。修改安全限制就像 关闭跨域限制一样,只需要打开
chrome://flag站点进行设置,如下图所示:上面那种改动粗暴,虽然有效,但不适合我们文化人,文化人就得干点文化人该干的事,修改调试站点地址, 比如:
一些前端要懂的服务端知识
同源 VS 同站 或 跨域 VS 跨站
同源,基本上懂行的前端都知道,只有请求的地址与站点是同协议、同域名、通端口,才能称为同源,除此以外,都是跨域;
而同站就没这么严格,简单看看同站定义:只要两个 URL 的 eTLD + 1 相同即可,不需要考虑协议和端口。
其中,eTLD 表示有效顶级域名,注册于 Mozilla 维护的公共后缀列表(Public Suffix List)中,例如,.com、.co.uk、.
github.io等。eTLD+1 则表示,有效顶级域名+二级域名,例如taobao.com等。举几个例子,www.taobao.com和www.baidu.com是跨站,www.a.taobao.com和www.b.taobao.com是同站,a.github.io和b.github.io是跨站(注意是跨站)。
为什么a.github.io和b.github.io是跨站,因为
github.io是有效顶级域名再来些零碎的
1.虽然同站可以携带cookie,但跨了域的同站请求不会主动携带,fetch需要设置
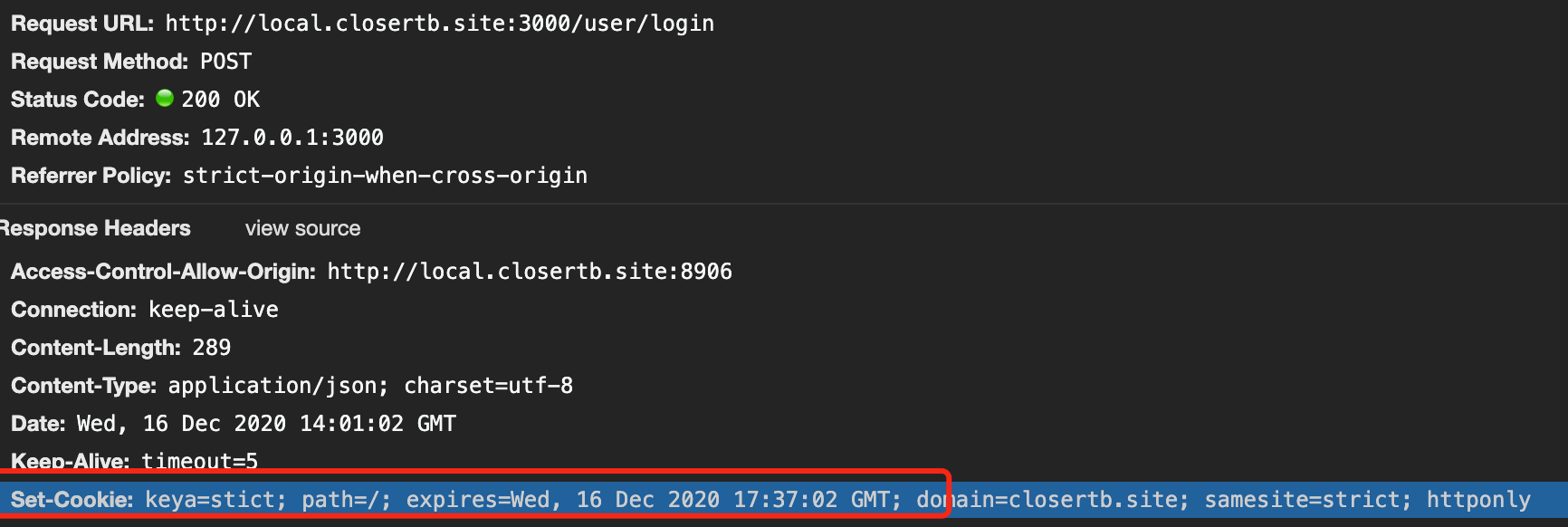
 2.服务端 set-cookie 也需要遵循同站规则,否则不生效;eg: 当前网站域名local.closertb.site, 登录发送请求/user/login,但该请求向admin.closertb.site种了一个cookie, 这个玩法就是非法的(管太宽),这个请求仅可种domai为'local.closertb.site' 或 'closertb.site';为无效时,浏览器会标黄提醒
2.服务端 set-cookie 也需要遵循同站规则,否则不生效;eg: 当前网站域名local.closertb.site, 登录发送请求/user/login,但该请求向admin.closertb.site种了一个cookie, 这个玩法就是非法的(管太宽),这个请求仅可种domai为'local.closertb.site' 或 'closertb.site';为无效时,浏览器会标黄提醒

credentials属性为include(ajax有相似设置), 但这只是开始,因为设置了这个属性携带了cookie后,这个请求就变成了非简单请求,服务端需要针对请求的站点设置Access-control-Allow-Credentials,如图下;3.cookie 的path 是针对于请求地址的,和当时浏览器地址无关;path 常用于多个服务通过一个网关来给前端提供接口,为尽量区分各个服务的cookie,所以有这个path属性设置,这样可以减少请求携带的cookie数量;图下所示的cookie,就只会在请求地址是以/rule 开头时才携带,其他地址就会忽略;

4.ajax 和 fetch 请求,响应302, 是不能直接改变浏览器地址进行跳转的,除非前端手动去操作;这就是为什么我们会说ajax 和 fetch 是前后端分离的开始,因为以前很多jsp 或 php页面,如果用户没有权限,就302重定向到登录页;而前后端分离后,更常见的做法是响应401,然后前端再手动跳转到登录页;
阿里本地生活成都、杭州、上海三地招前端、测试、后端,有意的可以发简历到我邮箱,也可以加我微信咨询。