 petermattis
commented
9 years ago
petermattis
commented
9 years ago @maximecaron CockroachDB uses MVCC for transactions. Shadow paging, as defined by wikipedia, is a different technique. Perhaps you have a different definition of shadow paging in mind.
CockroachDB has builtin replication. There are no current plans to support a logical stream of database modifications. Perhaps if you describe what you'd like to do with this stream (the high level goal) we can figure out what the equivalent in CockroachDB would be.
 maximecaron
maximecaron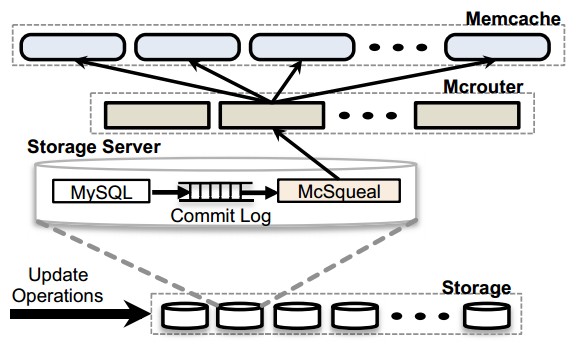
 spencerkimball
spencerkimball bdarnell
bdarnell rhauch
rhauch glerchundi
glerchundi dianasaur323
dianasaur323 csdigi
csdigi andrew-bickerton
andrew-bickerton wingedpig
wingedpig rhzs
rhzs skunkwerk
skunkwerk lukesteensen
lukesteensen awwx
awwx msample
msample ligustah
ligustah
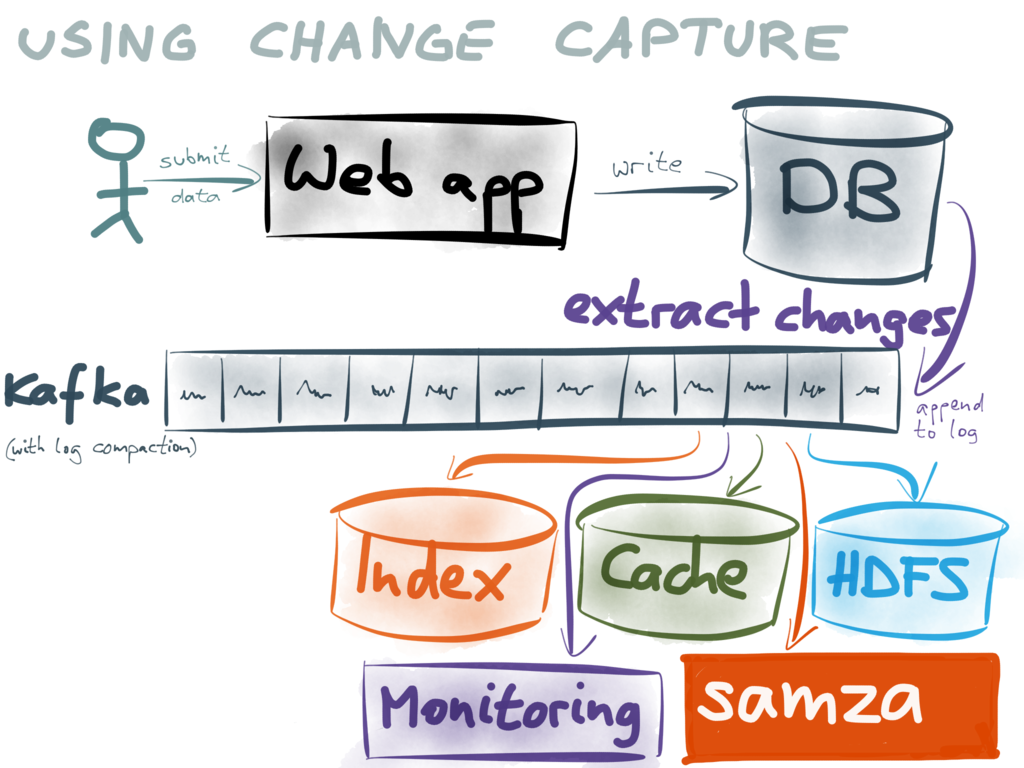
My understanding is that CockroachDB is currently using Shadow paging for transaction. Postgresql have a feature called Logical Decoding http://www.postgresql.org/docs/9.4/static/logicaldecoding.html . But this feature is using the write-ahead log. Would it be possible for CockroachDB to also support logical replication without using a write-ahead log?