 blathers-crl[bot]
commented
2 years ago
blathers-crl[bot]
commented
2 years ago Hello, I am Blathers. I am here to help you get the issue triaged.
It looks like you have not filled out the issue in the format of any of our templates. To best assist you, we advise you to use one of these templates.
I have CC'd a few people who may be able to assist you:
- @cockroachdb/kv (found keywords: raft)
If we have not gotten back to your issue within a few business days, you can try the following:
- Join our community slack channel and ask on #cockroachdb.
- Try find someone from here if you know they worked closely on the area and CC them.
:owl: Hoot! I am a Blathers, a bot for CockroachDB. My owner is otan.
 github-actions[bot]
github-actions[bot] mgartner
mgartner
Summary
This is a proposal for encoding inverted index integer sequences using a number system based on binomial coefficients. This number system is chosen because the minimum number of bits needed to encode a list of strictly increasing integers is given by the equation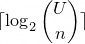 where
where  is largest number in the list and
is largest number in the list and  is the number of elements in the list.
For example to encode the sequence 1,2,3,4,10,11 we need at least 9 bits:
is the number of elements in the list.
For example to encode the sequence 1,2,3,4,10,11 we need at least 9 bits: 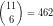 and
and
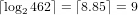 .
Binary interpolative coding, one of the best methods for inverted list compression takes at least 20 bits to represent the example sequence. You can confirm this here.
However, if we represent the same sequence as a sum of binomial coefficients, it takes 10 bits to encode the list, and an extra 3 bits to store the length of the list. The total is 13 bits. You can confirm this here.
.
Binary interpolative coding, one of the best methods for inverted list compression takes at least 20 bits to represent the example sequence. You can confirm this here.
However, if we represent the same sequence as a sum of binomial coefficients, it takes 10 bits to encode the list, and an extra 3 bits to store the length of the list. The total is 13 bits. You can confirm this here.
Motivation
Compression is a solved problem. The best compressors work by changing radixes, or number bases to find the most concise representation of data. For instance, arithmetic coding is a generalized change of radix for coding at the information theoretic entropy bound. This bound is a measure of redundancy - how many duplicates are in your data. Strictly increasing integer sequences have no duplicates, therefore, cannot be compressed according to the information theoretic bound. This means huffman coding and arithmetic coding methods are inefficient with non-repetitive integer sequences.
This rfc proposes the use of the combinatorial number system to encode inverted index integer sequences at the combinatorial information theoretic entropy bound. Just like arithmetic coding, this change in number systems allows us to encode integer sequences with the least number of bits. \ I am a Math major in my junior year and if this RFC succeeds I would love to take a gap year and work on this library full time. The library has sample code for converting between binary and the combinatorial number system using a greedy algorithm, or by generating a lookup table.
Masha Schneider and Jordan Lewis are the authors of CockroachDB's inverted index rfc
Technical design
\
Overview of Combinatorial Number System
Any natural number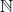 can be uniquely written as a sum of binomial coefficients
using this greedy algorithm.
can be uniquely written as a sum of binomial coefficients
using this greedy algorithm.
\
Example: Find the combinatorial representation of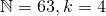
Comparison to Binary Interpolative Coding
In the example above, it can be seen that the sequence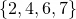 can be encoded in
can be encoded in 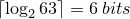 using the combinatorial number system with an extra 3 bits to store the length of the sequence. This is a total of 9 bits to encode this sequence.
\
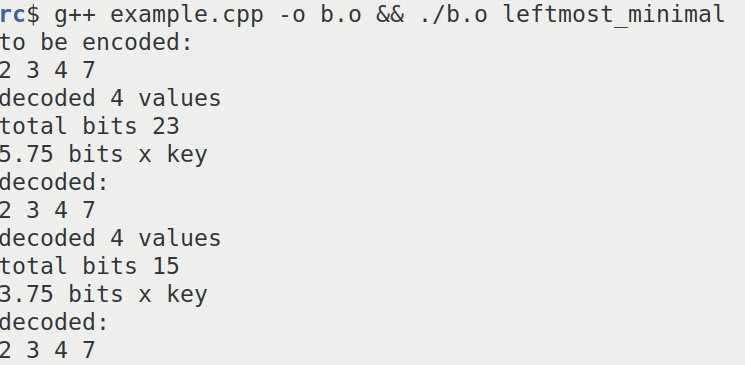
Using this library it can be confirmed that binary interpolative coding takes between 15 to 23 bits to encode the same sequence.
\
This is a screenshot of the result of binary interpolative coding.
using the combinatorial number system with an extra 3 bits to store the length of the sequence. This is a total of 9 bits to encode this sequence.
\
Using this library it can be confirmed that binary interpolative coding takes between 15 to 23 bits to encode the same sequence.
\
This is a screenshot of the result of binary interpolative coding.
 \
The combinatorial number systems always encodes integer sequences at the entropy limit.
\
The combinatorial number systems always encodes integer sequences at the entropy limit.
Drawbacks
Calculating a binomial coefficent is quite expensive. The calculation involves a lot of divisions.
...
Rationale and Alternatives
Alternatives to the combinatorial number system are Rice-Golomb coding and Binary Interpolative Coding. They are simple and run fast.
...
Explain it to folk outside of your team
Unresolved questions
Audience: all participants to the RFC review.
Jira issue: CRDB-11711