 czgdp1807
commented
4 years ago
czgdp1807
commented
4 years ago Could you test your code using this example?
Closed Tanvi141 closed 4 years ago
 Tanvi141
commented
4 years ago
Tanvi141
commented
4 years ago Tested the particular example, working properly.
[==========] Running 3 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 3 tests from Cuda
[ RUN ] Cuda.VectorGPU
[ OK ] Cuda.VectorGPU (62 ms)
[ RUN ] Cuda.MatrixGPU
[ OK ] Cuda.MatrixGPU (39 ms)
[ RUN ] Cuda.MatricesGPU
83.000000 63.000000 37.000000 75.000000 [ OK ] Cuda.MatricesGPU (312 ms)
[----------] 3 tests from Cuda (413 ms total)
[----------] Global test environment tear-down
[==========] 3 tests from 1 test case ran. (413 ms total)
[ PASSED ] 3 tests.Also updated required changed suggested above
Tanvi141
commented
4 years ago Hi, made required changes. Please see test_cuda reports;
[==========] Running 3 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 3 tests from Cuda
[ RUN ] Cuda.VectorGPU
[ OK ] Cuda.VectorGPU (252 ms)
[ RUN ] Cuda.MatrixGPU
[ OK ] Cuda.MatrixGPU (40 ms)
[ RUN ] Cuda.MatricesGPU
[ OK ] Cuda.MatricesGPU (342 ms)
[----------] 3 tests from Cuda (634 ms total)
[----------] Global test environment tear-down
[==========] 3 tests from 1 test case ran. (634 ms total)
[ PASSED ] 3 tests.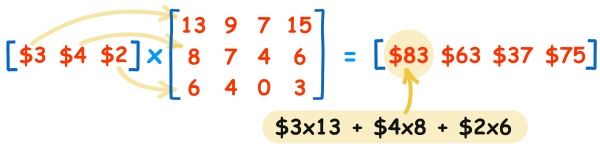{kind=link}
References to other Issues or PRs or Relevant literature
Fixes #8
Brief description of what is fixed or changed
Made changes to
multiply_gpumethod to implement logic of tiling using shared memory. Corner conditions included in case matrix size does not exactly match size of tile.