 mhowlett
commented
4 years ago
mhowlett
commented
4 years ago The default configuration properties for the consumer are tuned for very high throughput, and when something is wrong, they aren't forgiving in terms of the amount of bandwidth you can use... you could start by tweaking the following properties to prevent the consumer aggressively caching messages, which will give you a safety-net:
QueuedMinMessages
QueuedMaxMessagesKbytes
FetchMessageMaxBytes
FetchMaxBytes
(corresponding librdkafka property names)
queued.min.messages
queued.max.messages.kbytes
fetch.message.max.bytes
fetch.max.bytesThere shouldn't be a lot of overhead on top of the actual payload data. I'm not sure what is wrong from the information given - it could be that you're using the consumer in a way that isn't intended or a network related problem. If you provide your consumer code and/or output from setting the Debug config property to all, we can comment further.
 cculver
cculver It's really ridiculous if you ask me.
It's really ridiculous if you ask me.
Description
We are using Confluent Cloud with a testing environment with 17 topics, each with 6 partitions. Each topic has very few messages in it (<100 @ 1k per message). We noticed that our billing statement included an extremely excessive amount of bandwidth for how we were using it, to the point that our testing environment was almost exceeding our free allotment. It amounted to 4GB/day. For a very small environment, this made no sense to me. Using Wireshark, I decided to look at the network traffic for a single topic coming from my local environment going to Confluent Cloud over port 9092, to any of the 12 ip addresses for these hostnames: pkc-epwny.eastus.azure.confluent.cloud b0-pkc-epwny.eastus.azure.confluent.cloud b1-pkc-epwny.eastus.azure.confluent.cloud ... b11-pkc-epwny.eastus.azure.confluent.cloud
Each time we start up the single consumer for that single topic, we are seeing an inordinate amount of bandwidth being used by the consumer - approximately 40KB/sec for the first 240 seconds followed by some periods of lower activity, around 16KB/sec, and then back up and down and up again.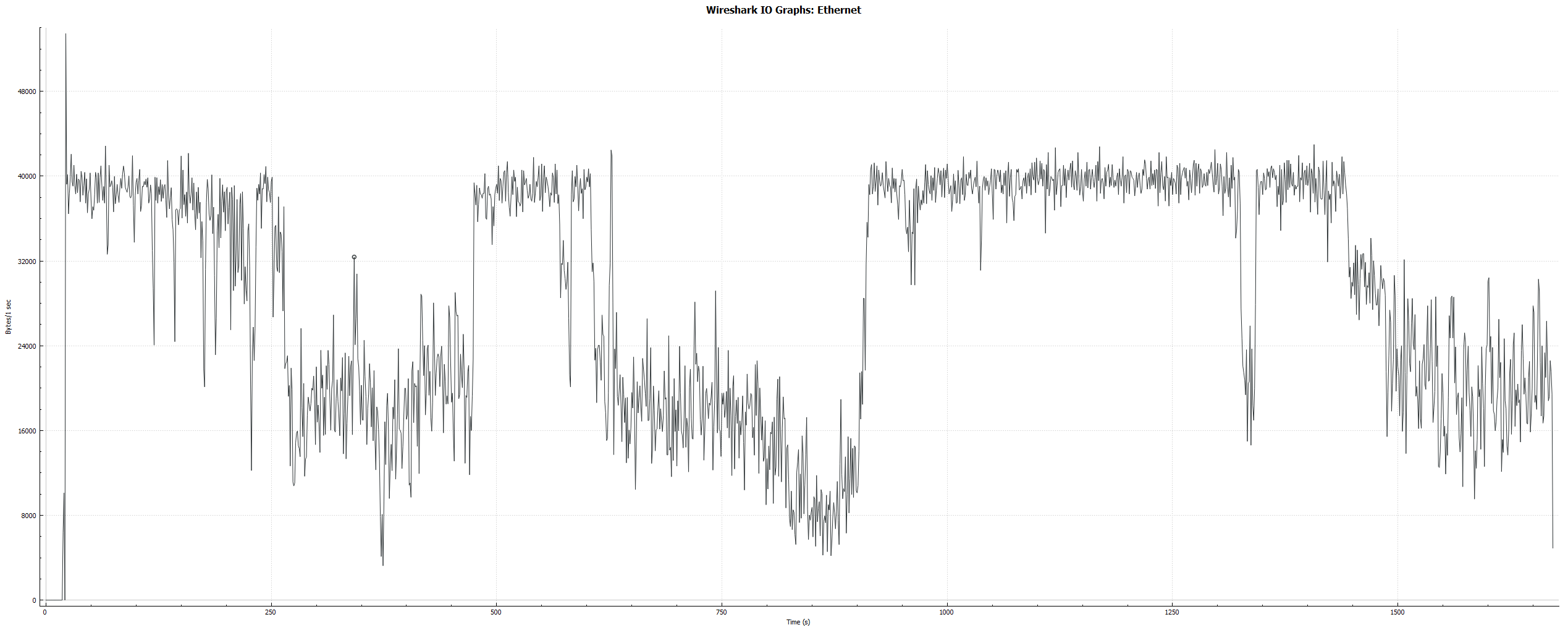
Outside of the connection/bootstrap settings, our consumer configuration is very simple, specifying our Group Id, Client Id, AutoOffsetReset=1, and EnableAutoOffsetStore=false. Am I doing something wrong here? Is there any explanation for the bandwidth issues we're seeing?
Edit: I also need to note that during this period, no messages are being produced to the topic. Because it's a testing environment, it's all very static. I should also note that I hooked up the confluent-kafka-dotnet git repo to the project so I could debug into it. All of this traffic is happening inside the call to the outside library function Librdkafka.consumer_poll().