nefta-kanilmaz-by
commented
2 years ago
nefta-kanilmaz-by
commented
2 years ago Any thoughts on this, is this a bug on our side? Do you have any hints/tips how we could debug further?
Open nefta-kanilmaz-by opened 2 years ago
nefta-kanilmaz-by
commented
2 years ago Any thoughts on this, is this a bug on our side? Do you have any hints/tips how we could debug further?
 fjetter
commented
2 years ago
fjetter
commented
2 years ago Well, ironically, the dataframe one should perform much better than the bag in most cases. The reason for this is that the dataframe computation performs a tree reduction when calculating the mean (see also https://docs.dask.org/en/latest/generated/dask.dataframe.groupby.Aggregation.html). It does not require an all-to-all communication pattern. Quite the opposite is happening for the bag. We do not know any structure for the bag and need to groupby a generic function. The only way we can do this is to perform a generic all-to-all shuffle. That's typically very expensive for a lot of reasons. That is, however, not the reason why you are running out of memory but the Bag computation is not equivalent.
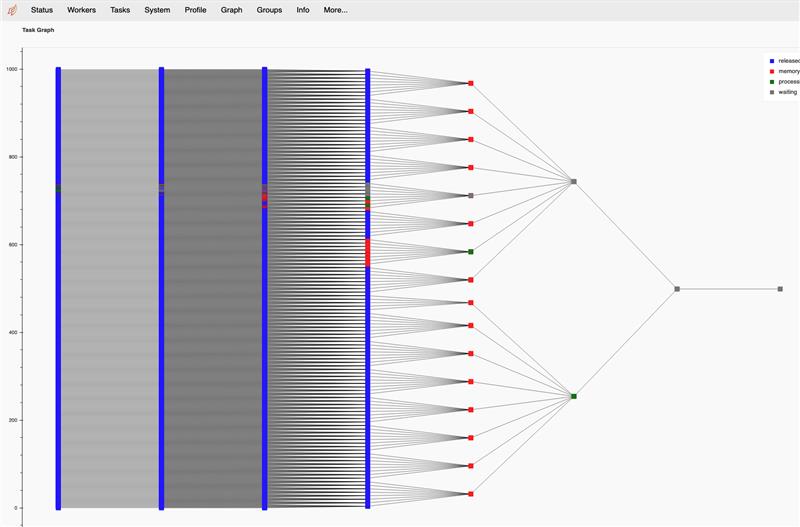
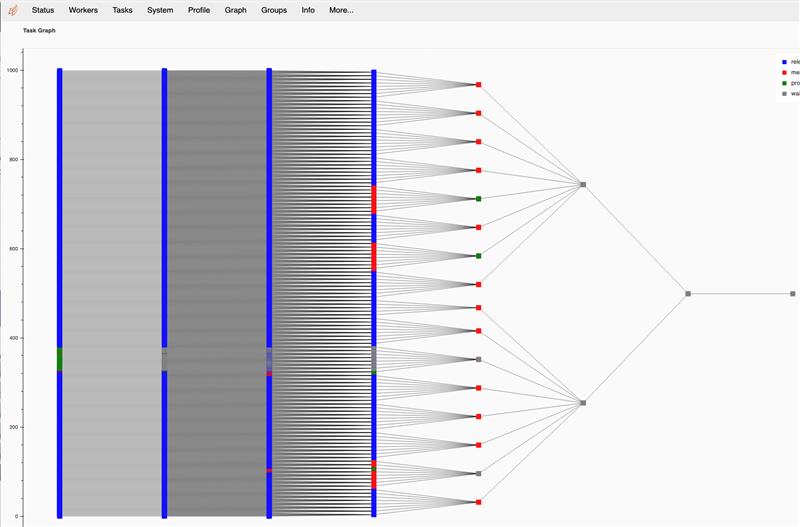
The reason why the dataframe computation blows up is because it tries to squeeze in the entire result into a single partition. This is very easy to confirm this already when inspecting the objects before computing them where you can see that the bag result is spread on ~1k partitions while the dataframe is merged into a single partition


This behaviour can be controlled with the split_out parameter, see https://examples.dask.org/dataframes/02-groupby.html#Many-groups
Setting this parameter to the input partition count is a fairer comparison to the bag and you should be able to compute this. The most efficient paramter is likely much smaller but I can't tell you where it should be ideally. That all depends on the actually used data.
dfs = [delayed(create_partition)(partition_id) for partition_id in range(partition_count)]
ddf = dd.from_delayed(dfs)
ddf = ddf.groupby(by=group_by_columns)
ddf = ddf.mean(split_out=partition_count)I suspect that the end result is actually not even your problem but it may be an intermediate step. By default, this tree reduction is using a branching factor of 32 (i.e. it merges intermediate results in sets of 32 partitions). We are not doing a good job exposing these internal parameters. I'm currently looking into how you can set this to try out
fjetter
commented
2 years ago Ah, the parameter I was looking for is called split_every but it does what I described above. Modifying split_every should help if intermediate results blow up but the end result fits comfortably in memory (ideally in powers of two), e.g. ddf.mean(split_every=16)
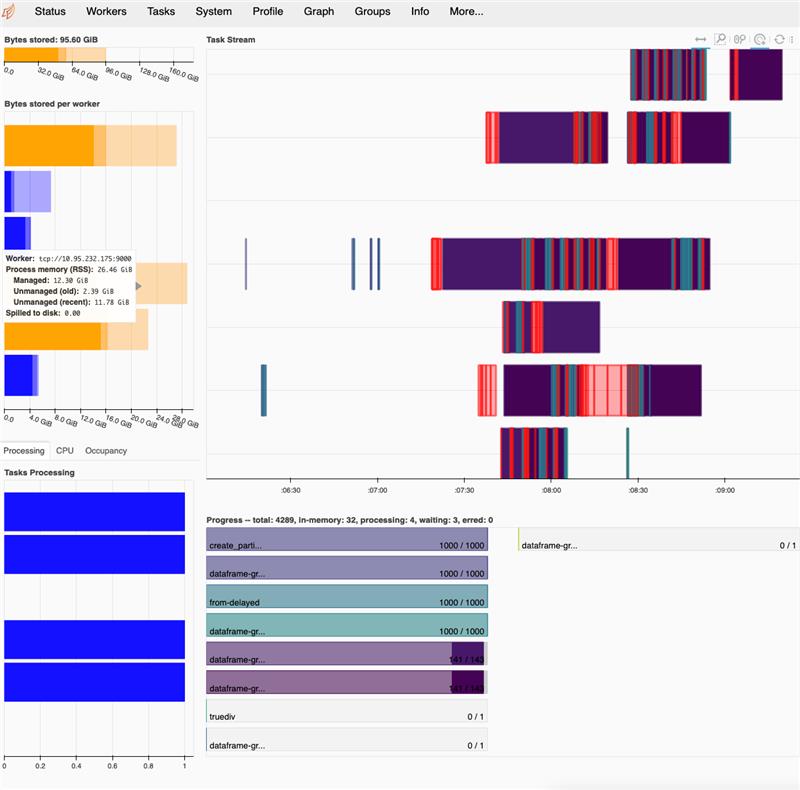
What happened:
KilledWorker exception for a rather small computation using dask dataframes.
We schedule a dask computation based on simulated data as part of our integration tests. In our test code, we create 1k partitions filled with random data which have a fixed size of 7k rows and 50 columns (see example below). The worker seems to go out of memory, the task is unsuccessfully retried on a different worker a couple of times until a
KilledWorkerexception is raised.What you expected to happen:
The computation succeeds, especially because the partition size seems to be small enough and the workers have enough memory (more information to that below).
Minimal Complete Verifiable Example:
Anything else we need to know?:
KilledWorkerexceptiondistributed.utils_comm - INFO - Retrying get_data_from_worker after exception in attempt 3/5: Timed out during handshake while connecting to tcp://172.20.10.118:9000 after 60 sThings we have tried to debug/mitigate the issue:
--> result doesn't change, still worker OOMs and finally a KilledWorker exception.
Environment:
10 Dask workers with 32 GB each, deployed on a kubernetes cluster with istio as service mesh
Cluster Dump State:
Computation fails, can't seem to retrieve this after that?Traceback:
```python --------------------------------------------------------------------------- KilledWorker Traceback (most recent call last) /tmp/ipykernel_29/1086427464.py inLogs:
```log 09:46:14.518 Lost connection to 'tcp://127.0.0.1:41066' while reading message: inScreenshots of dask dashboard: