 datalass1
commented
5 years ago
datalass1
commented
5 years ago Image Kernels, Explained Visually
Victor Powell
An image kernel is a small matrix used to apply effects like the ones you might find in Photoshop or Gimp, such as blurring, sharpening, outlining or embossing. They're also used in machine learning for 'feature extraction', a technique for determining the most important portions of an image. In this context the process is referred to more generally as "convolution". See how they work here.


The key piece of a convolutional neural network is convolution. A good example is http://setosa.io/ev/image-kernels
Most kernels in deep learning are 3x3 really fantastic interactive book http://neuralnetworksanddeeplearning.com/chap4.html
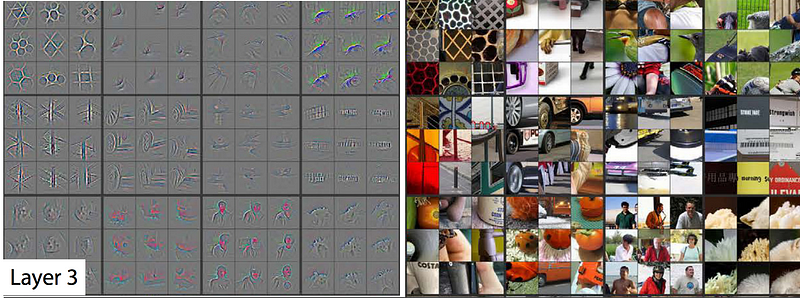
A great paper about what the convolutional layers are learning: Visualizing and Understanding Convolutional Networks, Matthew D. Zeiler, Rob Fergus: https://arxiv.org/pdf/1311.2901.pdf