 datalass1
commented
5 years ago
datalass1
commented
5 years ago Lesson 4: NLP; Tabular data; Collaborative filtering; Embeddings
Review of NLP (2mins - 12mins)
The trick is to use transfer learning! Starting with a language model, it learns to predict the next word of a sentence. N-grams previously used...they are terrible at predicting the next word. Use a Neural Net. Wikitext 103 dataset, so we have a pretrained model that knows how to complete sentences. Using transfer learning we can then use the pretrained wikitext model to predict movie reviews in the IMBD dataset. Self-supervised learning. A classic supervised model with labels that are actually built into the dataset, we don't need labels.
Questions (12mins - 14mins)
Does the language model work on slang, misspelled words, acronyms/short form? Yes. It can be fine tuned so it can learn the specifics of language whether it's medical or slang.
Back to NLP (14mins - 33mins)
How does predictive text work? Language models.
Each word is passed into the model as a weight matrix so we have to limit the volume of words, so words that are used less than twice are omitted and a max volcab size of 60,000 (by default).
The 'xxunk' means that the word token is not common enough to appear in our vocab. 'xxcap' will mean the word is capitalised.
Creating an RNN behind the scenes.
learn = language_model_learner(data_lm, pretrained_model=URLs.WT103_1, drop_mult=0.3)
drop out is regularisation, by reducing regularisation to avoid underfitting.
Fine tuning the last layers, then unfreeze and train the whole thing. It will take 2-3hours!
accuracy is getting it right about a third of the time, now we have a movie review model for predicting the next word.
What we really want is a model to understand the sentence. Create a classifier: make sure we pass in the vocab from the langauge model, so number 10 word is number 10 word in the classifier. Now we label classes - pos or neg Pass in the data and adjust drop out to decide how much regularisation we want > Train the model and we are getting a great accuracy over 90% after 3minutes.
You only have to do the language model once. It takes a long time but you can build on top of it.
Unfreeze the last 2layers only for text classifiers this seems to perform better.
Sentiment analysis refers to finding opinion aka opinion mining.
Questions: What is 2.6**4? discriminative learning rates: how quickly the lowest vs highest layers of a models will learn. As you go from layer to layer adjusting the optimal parameters settings!
Tabular data (33mins - 53mins)
It's interesting because it is spreadsheets! Neural Nets to analyse tabular data and it is useful! Pinterest uses it for their homepage and it works, better engineerings and less maintenance. Pandas dataframe is the most common way to read tabular data in python. For categorical data we use embeddings. For continuous is already numbers so they can go straight into a NN. Similar to transforms we have processors, we pre-process the dataframe AHEAD of time. The ones we will use are:
- FillMissing: look for NAs and deal with them - median and new column which is boolean - so fastai needs to make sure the training and validation text replacements are the same.
- Categorify: categorical values and turns them into pandas categories
- Normalize: take continuous variables and subtract their mean and divide by their standard deviation so they are 0 1 variables.
It is a good idea to .split_by_idx(list(range(800,1000))) in case the data is ordered.
Collaborative Filtering (53mins - 1hr7mins)
Who bought what, who liked what? Sparse matrix if lots of missing info. See Rachel's linear algebra. Basically: pick a user ID and a movie and predict whether that user will like that movie. Cold starts can be challenging - this is when you have no user data to start with, i.e. a new customer
Theory (1hr7mins
microsoft excel GitHub with excel When doing matrix multiplication it is essentially creating a dot product. The dot product of two vectors is a scalar. Dot product of vectors and matrices (matrix multiplication) is one of the most important operations in deep learning.ML cheatsheet. It is the basic starting point of a neural net. You get a matrix for each movie and each user id, the result is lots of random matrix of numbers.
Next we need a loss function for the random matrix of numbers with the output of one number, it is the square root of the mean square error (RMSE)
The gradient descent to try to modify our weight matrices to make our loss smaller. Using Solver Add-in in excel.
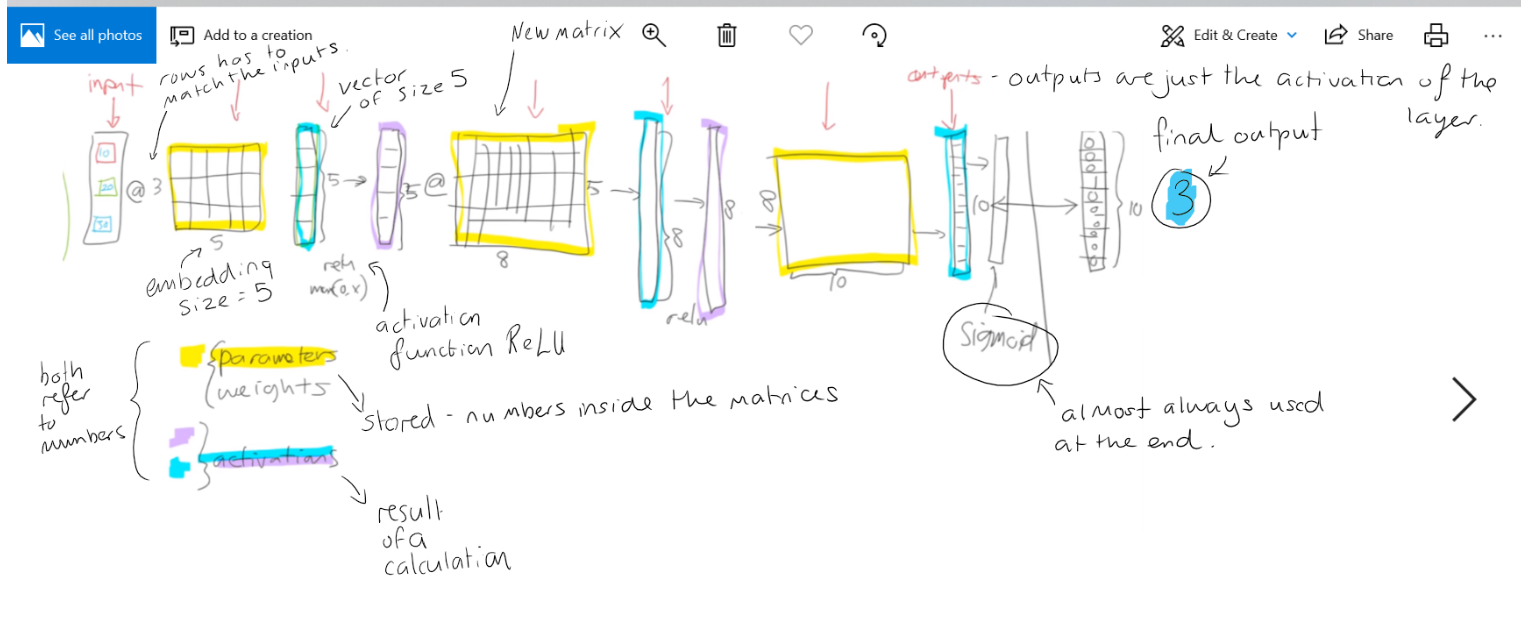
Vim, looking at code and Pytorch Embeddings are a matrix of weights. Any kind of weight matrix is designed to be indexed into as an array. There is an embedding matrix for a user, and embedding matrix for a movie. Bias is how much does a user normally like a movie in this example, we can specifically add a bias. Sigmoid at the end.
Vim and ctags - to open close jump about.
Neural Nets process
- Inputs
- weights/parameters
- activations
- activation functions/nonlinearities
- output
- loss
- metric
- cross-entrophy
- softmax
- fine tuning
In lesson 4 we'll dive in to natural language processing (NLP), using the IMDb movie review dataset. In this task, our goal is to predict whether a movie review is positive or negative; this is called sentiment analysis. We'll be using the ULMFiT algorithm, which was originally developed during the fast.ai 2018 course, and became part of a revolution in NLP during 2018 which led the New York Times to declare that new systems are starting to crack the code of natural language. ULMFiT is today the most accurate known sentiment analysis algorithm.
The basic steps are:
Create (or, preferred, download a pre-trained) language model trained on a large corpus such as Wikipedia (a "language model" is any model that learns to predict the next word of a sentence) Fine-tune this language model using your target corpus (in this case, IMDb movie reviews) Extract the encoder from this fine tuned language model, and pair it with a classifier. Then fine-tune this model for the final classification task (in this case, sentiment analysis). After our journey into NLP, we'll complete our practical applications for Practical Deep Learning for Coders by covering tabular data (such as spreadsheets and database tables), and collaborative filtering (recommendation systems).
For tabular data, we'll see how to use categorical and continuous variables, and how to work with the fastai.tabular module to set up and train a model.
Then we'll see how collaborative filtering models can be built using similar ideas to those for tabular data, but with some special tricks to get both higher accuracy and more informative model interpretation.
This brings us to the half-way point of the course, where we have looked at how to build and interpret models in each of these key application areas:
For the second half of the course, we'll learn about how these models really work, and how to create them ourselves from scratch. For this lesson, we'll put together some of the key pieces we've touched on so far:
We'll be coming back to each of these in lots more detail during the remaining lessons. We'll also learn about a type of layer that is important for NLP, collaborative filtering, and tabular models: the embedding layer. As we'll discover, an "embedding" is simply a computational shortcut for a particular type of matrix multiplication (a multiplication by a one-hot encoded matrix).