 datalass1
commented
5 years ago
datalass1
commented
5 years ago Lesson 5: Back propagation; Accelerated SGD; Neural net from scratch
Foundations of Neural Nets! You need to use deep learning for computer vision for good results. Understanding more about regularisation to sort out underfitting.
This lesson uses EXCEL spreadsheets to support understanding of deep learning, with the example of collaborative learning.
There are only 2 types of layer: parameters and activations.
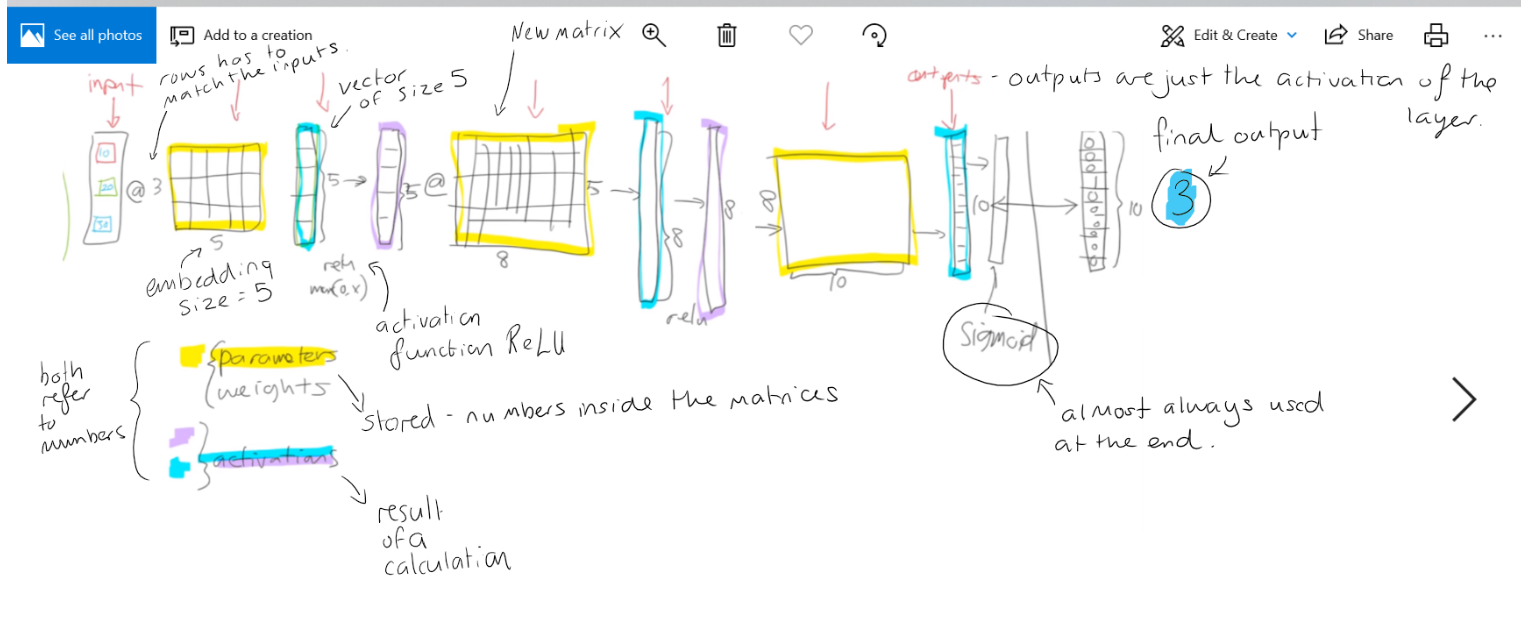 The parameters are what you model learns.
The yellow is our weight tensors/matrix, these numbers are calculated.
Activations come from matrix multiplications (MM) and the activation funcions (in blue): an element wise function - a 20 long vector to 20 long activation. ReLU is what we normally use.
MM followed by ReLU stacked together results is these amazing mathematical property called the universal approximation theorem which is if you have big enough weight matrices and enough of them it can solve any arbitrarily complex mathematical function to any arbitrarily high level of accuracy, assuming you can train the parameters time and compute.
The parameters are what you model learns.
The yellow is our weight tensors/matrix, these numbers are calculated.
Activations come from matrix multiplications (MM) and the activation funcions (in blue): an element wise function - a 20 long vector to 20 long activation. ReLU is what we normally use.
MM followed by ReLU stacked together results is these amazing mathematical property called the universal approximation theorem which is if you have big enough weight matrices and enough of them it can solve any arbitrarily complex mathematical function to any arbitrarily high level of accuracy, assuming you can train the parameters time and compute.
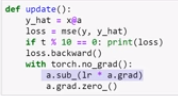
Back propagation
weights = weights - weights.grad * learning rate
Resnet34 has 1000 columns because there is 1000 images to classify in ImageNet. This weight matrix is no good in transfer learning. You have new categories to predict. So when you train a new cnn you delete the last layer and add new weight matrices (as big as you need it to be) with a new ReLU inbetween.
The Zeiler and Fergus paper is a good example of some of the things round in what a weight matrix will find. One of the filters can find corners, the next repeating patterns, next some round things etc, so the weight matrices are becoming more sophisticated, these weight are good so lets keep them as they are.
Don't bother training any of the other weights by freeze all the other layers. Then unfreeze and train the earlier layers, but not too much training. Discriminative learning rates.
Affine functions, it just means a linear function (like a MM, it is the most common kind of affine function used in deep learning). But as we’ll see when we do convolutions. Convolutions are matrix multiplications where some of the weights are tied and so it would be slightly more accurate to call them affine functions.
one hot encoding vs. array lookup aka embedding. Array lookup aka embedding is mathematically identical to doing a matrix product by a one-hot encoded matrix (24mins). Always do an array lookup/embedding - it is much faster and memory efficient.
latent features once we train a neural net
bias we can add another row to the matrix for MM which will take into account bias. Better model and better result, makes sense semantically.
Helpful HINT
 if you get this error, this means that csv isn’t unicode. We solve this by adding
if you get this error, this means that csv isn’t unicode. We solve this by adding encoding='latin-1'
movies = pd.read_csv(path/'u.item',delimite='|', encoding='latin-1',
header=None, names=['movieId','title','date','N','url',*
[f'g{i}' for i in range(19)]])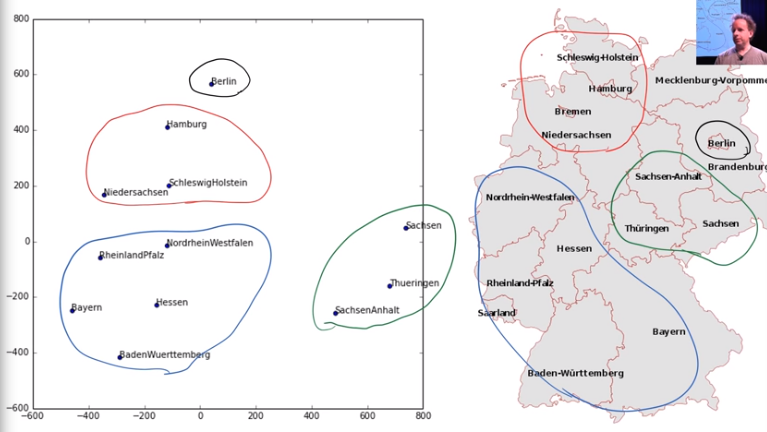
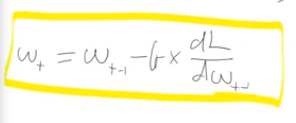 Basically, new weights/parameters are calculated by taking the previous epochs weights (time -1) subtract the learning rate, times the derivative of the loss function divided by the derivative of weight (time -1).
Basically, new weights/parameters are calculated by taking the previous epochs weights (time -1) subtract the learning rate, times the derivative of the loss function divided by the derivative of weight (time -1).  Start off with randomly generated x and y data for ax+b. a=2 b=30
Every row is a batch size of 1.
y_pred: Starting with intercept and slope of 1, the first prediction for x=14 and y=58 is 15. Calculated by 1*14+1 (ax+b).
Start off with randomly generated x and y data for ax+b. a=2 b=30
Every row is a batch size of 1.
y_pred: Starting with intercept and slope of 1, the first prediction for x=14 and y=58 is 15. Calculated by 1*14+1 (ax+b).
Overview
In lesson 5 we put all the pieces of training together to understand exactly what is going on when we talk about back propagation. We'll use this knowledge to create and train a simple neural network from scratch.
We'll also see how we can look inside the weights of an embedding layer, to find out what our model has learned about our categorical variables. This will let us get some insights into which movies we should probably avoid at all costs…
Although embeddings are most widely known in the context of word embeddings for NLP, they are at least as important for categorical variables in general, such as for tabular data or collaborative filtering. They can even be used with non-neural models with great success.
Great notes: https://forums.fast.ai/t/deep-learning-lesson-5-notes/31298