 miku
commented
6 years ago
miku
commented
6 years ago CrossRef - has API but no official regular bulk dump
We have been working with the crossref API (for a search infrastructure project) since early 2015 and we found it to be excellent to work with concerning usability and documentation. We were interested in complete dumps as well, so we implemented a monthly harvest as part of our metadata gathering and processing infrastructure, which is based on luigi.
The basic operation is as follows:
Use a filter (we used deposit, but should switch to from-deposit-date or similar) to request all items for the last month. Also, use the cursor mechanism, which is the way to extract a large number of documents fast (plug: solrdump is a generic fast SOLR document exporter).
You end up with some directory full of JSON files.
$ tree -sh
...
├── [8.4G] begin-2018-02-01-end-2018-03-01-filter-deposit.ldj
├── [7.5G] begin-2018-03-01-end-2018-04-01-filter-deposit.ldj
├── [ 12G] begin-2018-04-01-end-2018-05-01-filter-deposit.ldj
├── [9.4G] begin-2018-05-01-end-2018-06-01-filter-deposit.ldj
└── [6.4G] begin-2018-06-01-end-2018-07-01-filter-deposit.ldjThis is how the monthly harvest sizes developed over the years:
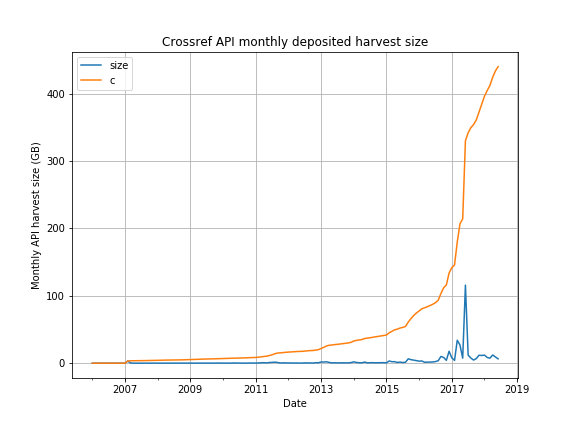
Zoomed in a bit (from 2015):
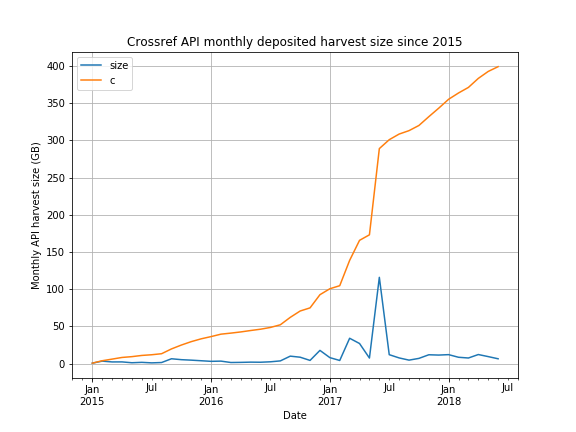
Now, seeing all these files as a single data set, there are quite some duplicates (redeposited files, through publisher updates or API changes). It would not be too complicated to run some additional data store, which could hold only the most recent record (by overwriting records via DOI).
We opted for another approach, which allows us to not have to maintain an external data store and still have only the latest version of each DOI at hand: We just iterate over all records and keep the last. This currently means iterating over 400G of JSON, but that's actually not that bad. After a few sketches, the functionality went into a custom command line tool, span-crossref-snapshot.
That tools is a bit ugly (implementation-wise), as it tries hard to be fast (parallel compression, advanced sort flags, custom fast filter tool with awk fallback, and so on). It is quite fast and despite the awkward bits quite reliable.
// Given a single file with crossref works API messages, create a potentially
// smaller file, which contains only the most recent version of each document.
//
// Works in a three-stage, two-pass fashion: (1) extract, (2) identify, (3) extract.
// Performance data point (30M compressed records, 11m33.871s):
//
// 2017/07/24 18:26:10 stage 1: 8m13.799431646s
// 2017/07/24 18:26:55 stage 2: 45.746997314s
// 2017/07/24 18:29:30 stage 3: 2m34.23537293sIn the end, we do have a file crossref.ldj.gz which is about 40G in size and currently contains 97494426 records.
 anuveyatsu
anuveyatsu rufuspollock
rufuspollock
Awesome page in progress at: https://datahub.io/collections/bibliographic-data
What we Cover
Datasets we want to cover:
Tasks
State of play
I compiled a detailed spreadsheet (as of 2016) of the state of play here:
https://docs.google.com/spreadsheets/d/1Sx-MKTkAhpaB3VHiouYDgMQcH81mKwQtaK2-BXYbKkE/edit#gid=0
Context
These are the kind of questions / user stories I had
User stories:
Aim of research