 davidgiven
commented
5 years ago
davidgiven
commented
5 years ago The good news is that because a pulse is simply dropped but the timing doesn't otherwise change, it looks like whatever's happening is in the sampler or upstream, and not a bytecode processing issue --- as the bytecode concerns itself with intervals, if an interval was dropped I'd expect the timing to change.
I wonder if I've remembered to properly synchronise the pulses before sampling them?

 pelrun
pelrun
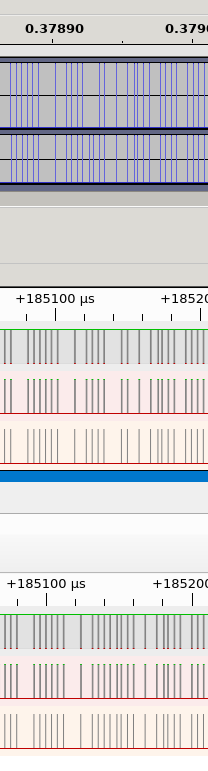
 andrewferguson
andrewferguson
My logic analyser has finally arrived and I've determined that the sampler is, indeed, dropping pulses. Top row is what FluxEngine's sampler is producing, the bottom row is what the logic analyser sees.
This one's from a Mac 800kB disk, but this shows up on the ND 17b disks too (and probably lots more). I have no idea why it's not showing up more. We're reading both HD and DD disks quite happily in other formats.