 Ljupch0
commented
3 years ago
Ljupch0
commented
3 years ago I am trying to achieve the same thing (https://stackoverflow.com/questions/69780665/ggplot-sankey-diagram-of-income-to-expenses-ggsankey). Curious if there is a clean way to incorporate it.

 MPietzke
MPietzke

 stragu
stragu
The question is based on this issue: https://github.com/davidsjoberg/ggsankey/issues/6
First of all, it would be nice to have a proper explanation how the structure of the data should look like. I'm planning to visualise my finances, with 3 stages. I noticed this isn't working, although this is (at least for me) the more logical input structure, you define the flows from stage 1 to stage 2, and these from stage 2 to stage 3. It isn't necessarily defined from stage 1 to 3.
 The empty fields generate NA's which create new nodes, when being converted to long and plotted.
The empty fields generate NA's which create new nodes, when being converted to long and plotted.
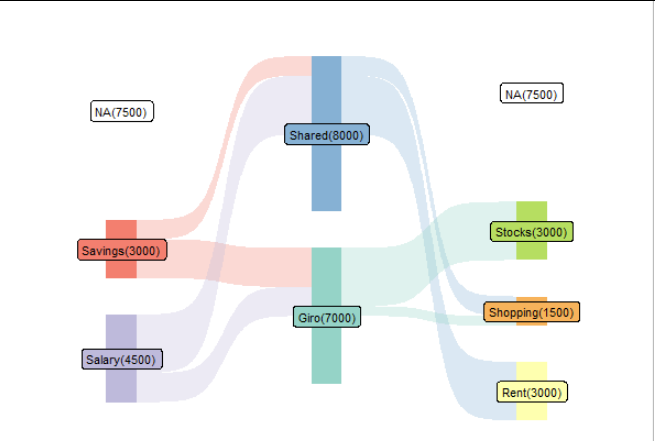
It works however when all the combinations are filled and the numbers (the money) are distributed: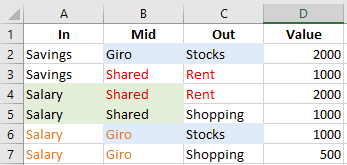
Notice that we now have some duplications in here, e.g. the salary that goes into the giro (1500) is splitted into the money that goes from the giro to the stocks and the shopping. (1000 + 500). Also the money comes from the giro and ends in the stocks (3000) is splitted into the source savings (2000) and salary (1000)
When converting to long and removing the nodes that are NA and the next_nodes that are NA (except for the last nodes) this seem to work. At least for the 3 stages. Maybe you can further test and incorporate this!
CODE: