 kcoyle
commented
4 years ago
kcoyle
commented
4 years ago Some terms being used in the application profile area for this same (or analogous) concept:
DSP: description Resource
BIBFRAME: Resource template
Sinopia: resource
YAMA: descriptions
IMS global: element
ODRL: class
DCAT: class
Wikidata: item
(edit and add others that you know)
 nishad
nishad tombaker
tombaker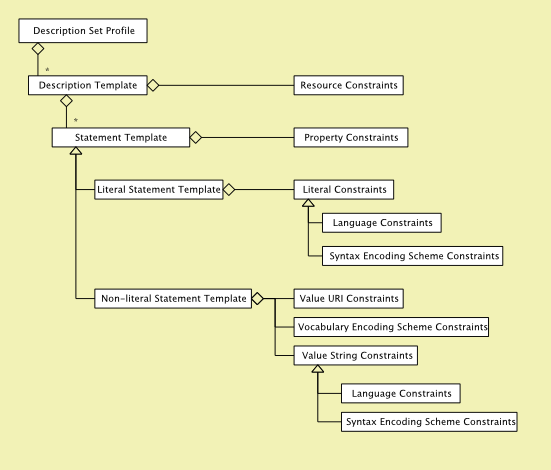
 philbarker
philbarker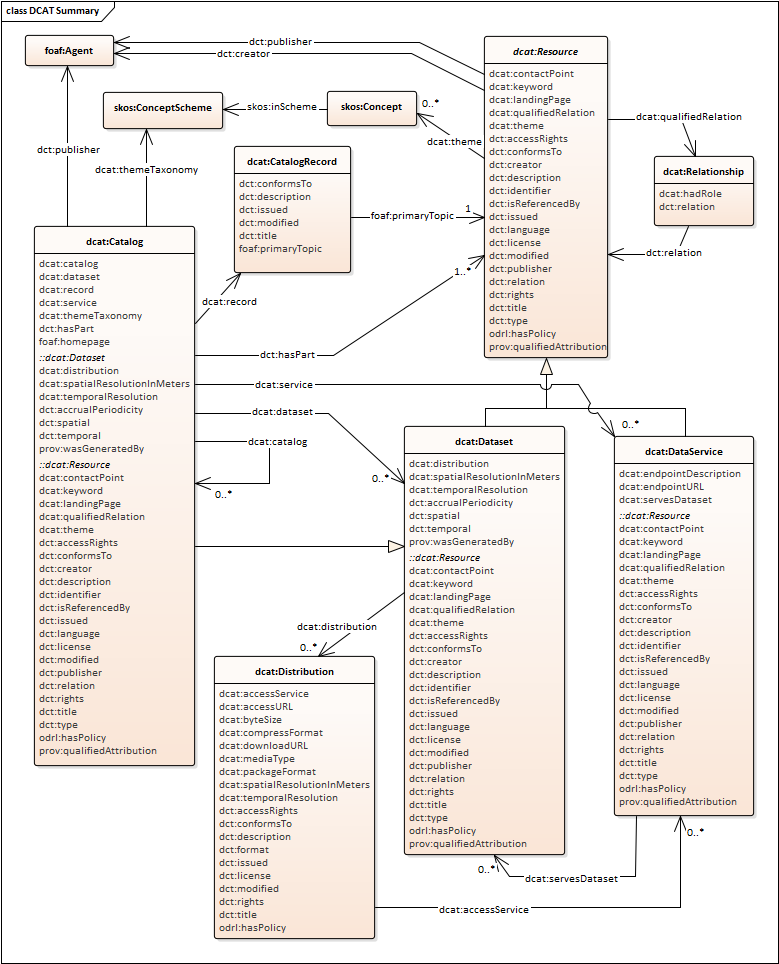

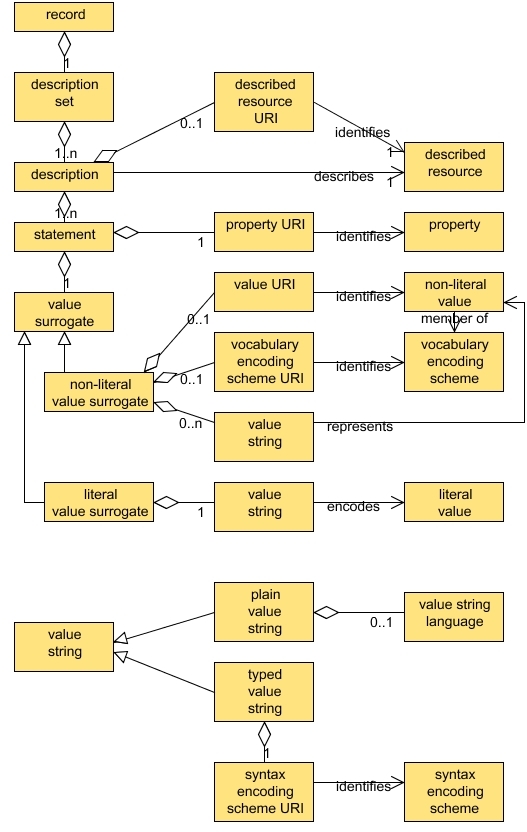
The application profile is generally defined as metadata for a description of one or more things. The DCAM and DSP defined the structure of the profile as:
description with 1..n statement with 1..1 value"Entity" is what we are currently calling the "description" level in our simple template. The entity is represented in a column called "entity_name" which is an identifier for the entity; it could be a simple literal name, or it could be an IRI. There is an "entity_label" column for human display.