 IbrahimSobh
commented
7 years ago
IbrahimSobh
commented
7 years ago Dears
Any updates regarding this issue?
Open nerdoid opened 8 years ago
IbrahimSobh
commented
7 years ago Dears
Any updates regarding this issue?
 fferreres
commented
7 years ago
fferreres
commented
7 years ago I wish someone else with time could help diagnose what's wrong. I know Denny is probably very busy with Language Translate stuff.
The value of this repository is that the code from Denny is very easy to follow (documented, commented) even if takes time at points. I stopped learning about RL when I couldn't figure out why DQN could not be diagnosed by anyone reading this repo, and stuck in general. I am reading slowly on new algorithms like Neural Episodic Control (https://arxiv.org/pdf/1703.01988.pdf). I take blame, in that this RL literature is fascinating, but the details and fine tuning are not for gentle on amateurs.
Any kind soul that knows what may be causing things in the DQN code, please help us get unstuck.
 dennybritz
commented
7 years ago
dennybritz
commented
7 years ago I should have time again to look into it starting late next week, I've been busy with another project. Thanks for all the suggestions so far.
IbrahimSobh
commented
7 years ago Thank you Denny,
I think the same cause is affecting both DQN and A3C ...
 ppwwyyxx
commented
7 years ago
ppwwyyxx
commented
7 years ago @cgel I think the optimizer doesn't actually matter very much. In my own DQN implementation I just used no-brainer AdamOptimizer as usual and it's working fine. I had the same experience that the terminal flag makes little difference.
To this issue itself, it looks like the score you're looking at is the training score (i.e. with epsilon greedy). Using greedy evaluation would improve a lot (and that's what everyone is using). When my agent gets 400 test score, the training score (with eps=0.1) is only around 70. And btw, in evaluation, lost of life is not end of episode (unlike training).
 eduardbermejo
commented
7 years ago
eduardbermejo
commented
7 years ago I'm currently training DQN with some small changes mentioned by @ppwwyyxx . WIll let you know the results asap. Btw, thanks @dennybritz for this nice repo.
eduardbermejo
commented
7 years ago No improvement. But I think it's just a misunderstanding by me.
Don't know if @dennybritz has already tried it but I changed the environment so every time a life was lost the episode should be considered finished and the environment should restart.
This is where I did wrong, because this way you are not letting the agent see advanced states of the game. So the key is to just set the reward to -1 when a life is lost and don't reset the environment, just keep playing so the agent gets to play 5 episodes per game. The key here is that every state-action pair that lead to a loss of life should get a Q value of -1. So we should still be putting a done==True to a loss of life so np.invert() can make his job but only reset the environment when env.env.ale.lives() == 0.
Next week I'll have some time to try this out and will let you know. Maybe it's not the root cause of the problem but I though it might be worth sharing it in case it can help someone or give some ideas.
Let's fix this once and for all between all of us ;) If someone gets to try this please let us know :)
 cgel
commented
7 years ago
cgel
commented
7 years ago @ppwwyyxx I have not run an extensive optimizer search but in my experience DQN is very sensitive to it. Regarding what epsilon should you use, the original DQN used 0.1 for the training and 0.05 the testing. The numbers that you give seem a bit strange to me. When I see a testing score > 300 the training score is > 150.
@ERed you are right in saying that you should not reset the environment but you seem to be over complicating the solution. There is no reason for the Q value of a life lost being -1, it should be 0. The easiest solution is to pass a terminal flag to the agent and keep the game running. But again, I have already tried it and it barely made any difference.
 hengyuan-hu
commented
7 years ago
hengyuan-hu
commented
7 years ago Marking loss of life as termination of the game can bring big improvement in some game (at least in SpaceInvader as I tested). I think the intuition is that, if not, the q-value for the same state under different number of lives should be different but the agent cannot differentiate this difference given only the raw pixel input. In spaceinvader, this can increase the score from ~600 to ~2000 with other variates controlled.
 fuxianh
commented
6 years ago
fuxianh
commented
6 years ago @dennybritz Hi, I think I met the same problem as you, I tried in Open AI Gym baseline BreakoutNoFrameskip-v4, and the reward converges to around 15[In DQN nature paper, it's around 400]. Did you figure out the problem, if possible, pease give me some suggestion about this.
 dylanthomas
commented
6 years ago
dylanthomas
commented
6 years ago Did you get a chance to read this, https://github.com/openai/baselines ?
Seong-Joon Park, Managing Director Move sf.
On Sun, Dec 17, 2017 at 5:41 PM, fuxianh notifications@github.com wrote:
@dennybritz https://github.com/dennybritz Hi, I think I met the same problem as you, I tried in Open AI Gym baseline BreakoutNoFrameskip-v4, and the reward converges to around 15[In DQN nature paper, it's around 400]. Did you figure out the problem, if possible, pease give me some suggestion about this.
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/dennybritz/reinforcement-learning/issues/30#issuecomment-352240537, or mute the thread https://github.com/notifications/unsubscribe-auth/ABAN9R0IfQn6eyb3AY9UX1eVtj16o9AGks5tBNO7gaJpZM4Ky0f- .
 jpangburn
commented
6 years ago
jpangburn
commented
6 years ago I've found more success with ACKTR than with Open AI's deepq stuff. Here's a video of it getting 424: breakout. This wasn't an especially good score, it was just a random run I recorded to show a friend. I've seen it win the round and score over 500.
hengyuan-hu
commented
6 years ago In case anyone still would like to see a working DQN stuff, I have a pretty good implementation here: https://github.com/hengyuan-hu/rainbow It implements several very powerful extensions like distributional DQN, which has a very smooth learning curve on many Atari games. On Wed, Jan 10, 2018 at 3:21 PM Jesse Pangburn notifications@github.com wrote:
I've found more success with ACKTR than with Open AI's deepq stuff. Here's a video of it getting 424: breakout https://www.dropbox.com/s/ax11s81m7rq50xu/breakout.mp4?dl=0. This wasn't an especially good score, it was just a random run I recorded to show a friend. I've seen it win the round and score over 500.
— You are receiving this because you commented. Reply to this email directly, view it on GitHub https://github.com/dennybritz/reinforcement-learning/issues/30#issuecomment-356520642, or mute the thread https://github.com/notifications/unsubscribe-auth/AEglZTuPeqDIHwIPF8wtYKx_QZyHDz12ks5tJGUIgaJpZM4Ky0f- .
 cr7anand
commented
6 years ago
cr7anand
commented
6 years ago @dennybritz firstly, thank you for creating this easy to follow DeepRL repo. I've been using it as a reference to code up my own DQN implementation for Breakout in PyTorch. Is the current avg_score that the agent is achieving still saturating around 30? In your dqn implementation the Experience Replay buffer has a size=500,000 right, I feel that the size of the Replay is very critical to replicating DeepMind's performance on these games. would like to hear your thoughts on this? Have you tried increasing Replay size to 1,000,000 as suggested in the paper?
 zmonoid
commented
6 years ago
zmonoid
commented
6 years ago Wonder if anyone is still following this post.
DQN is very sensitive to your optimizer, and your random seed. Shown below is 4 runs with same setting.
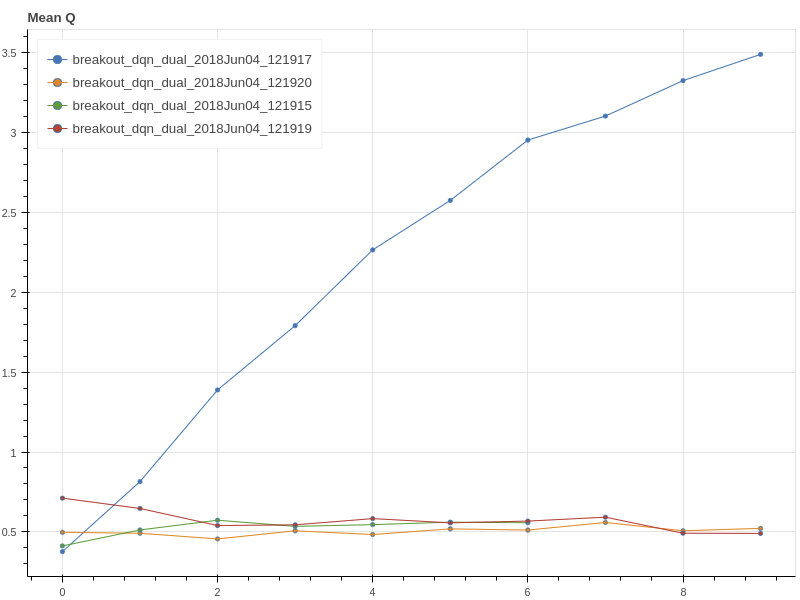

It is very hard to find a good optimizer as below one:

 This one use Adagrad: lr=0.01, epsilon = 0.01 (You need to change adagrad.py for pytorch for this optimizer). It is strange that, use rmsprop: lr=0.01, epsilon=0.01, decay=0, momentum=0, which according to source code is exactly the same, but it will be simply not working. Same for Adam. Good luck to your RL research.
This one use Adagrad: lr=0.01, epsilon = 0.01 (You need to change adagrad.py for pytorch for this optimizer). It is strange that, use rmsprop: lr=0.01, epsilon=0.01, decay=0, momentum=0, which according to source code is exactly the same, but it will be simply not working. Same for Adam. Good luck to your RL research.
ppwwyyxx
commented
6 years ago DQN is very sensitive to your optimizer, and your random seed
... in certain implementation and certain tasks.
Breakout is in fact very stable given a good implementation of either DQN or A3C. And DQN is also quite stable compared to policy-based algorithms like A3C or PPO.
zmonoid
commented
6 years ago @ppwwyyxx Notice in your implementation:
gradproc.GlobalNormClip(10)This may be very important .... Actually, PPO and TRPO could be regarded as gradient clip which makes it stable.
ppwwyyxx
commented
6 years ago IIRC that line of code has no visible effect on training breakout as the gradients are far from large enough to reach that threshold. I'll remove it.
zmonoid
commented
6 years ago @ppwwyyxx I tried Adam optimizer with epsilon=1e-2 same as your setting, it works.
 boranzhao
commented
6 years ago
boranzhao
commented
6 years ago I tested with the gym environment Breakout-v4 and found that the env.ale.lives() will not change instantly after losing a life (i.e. the ball disappears from the screen). Instead, the value will change roughly 8 steps after a life is lost. Could somebody verify what I said? If this is true, then the episode will end (according to whether a life is lost) at a fake terminal state that is 8 steps after the true terminal state. This is probably one reason why DQN using gym Atari environment cannot get high enough scores.
 SamKirkiles
commented
6 years ago
SamKirkiles
commented
6 years ago I've done a brief search over RMSProp momentum hyperparameters and I believe it could be the source of the issue.
I ran three models for 2000 episodes each. The number of frames varies based on the length of the episodes in each test. For scale, the red model ran for around 997,000 frames while the other two ran for around 700k.
The momentum values were as follows: dark blue - 0.0 red - 0.5 light blue - 0.9
Because red performed best at 0.5, I will run a full training cycle and report back with my findings.

It seems strange to use a momentum value of 0.0 while the paper uses 0.95. However, I feel the logic here could be that momentum doesn't work well on a moving target but I haven't seen hard evidence of this being the case.
 GuangxiangZhu
commented
6 years ago
GuangxiangZhu
commented
6 years ago @fuxianh I met the same problem as you when running the DQN code from Open AI Gym baseline on BreakoutNoFrameskip-v4. Have you solved this problem and could you share the experiences?Thank you very much!
 fg91
commented
6 years ago
fg91
commented
6 years ago hey guys,
I've been working on implementing my own version of DQN recently and I encountered the same problem: the average reward (over the last 100 rounds in my plot) peaked at around 35 for Breakout.
I used Adam with a learning rate of 0.00005 (see blue curve in the plot below). Reducing the learning rate to 0.00001 increased the reward to ~50 (see violet curve).
I then got the reward to > 140 by passing the terminal flag to the replay memory when a life is lost (without resetting the game), so it does make a huge difference also for Breakout.


Today I went over the entire code again, also outputting some intermediate results. A few hours later at dinner it struck me that I saw 6 Q values this morning while I had the feeling that it should be 4.
A quick test confirms that for BreakoutDeterministic-v3 the number of actions env.action_space.n is 6:
NOOP, FIRE, RIGHT, LEFT, RIGHTFIRE, LEFTFIRE
Test this with env.unwrapped.get_action_meanings()
DeepMind used a minimal set of 4 actions: PLAYER_A_NOOP, PLAYER_A_FIRE, PLAYER_A_RIGHT, PLAYER_A_LEFT
I assume that this subtle difference could have a huge effect, as it alters the tasks difficulty.
I will immediately try to run my code with the minimal set of 4 actions and post the result as soon as I know :)
Fabio
fg91
commented
6 years ago I recently implemented DQN myself and initially encountered the same problem: The reward reached a plateau at around 35 in the Breakout environment.
I certainly found DQN to be quite fiddly to get working. There are lots of small details to get right or it just doesn't work well but after many experiments, the agent now reaches an average training reward per episode (averaged over the last 100 episodes) of ~300 and an average evaluation reward per episode (averaged over 10000 frames as suggested by Mnih et al. 2013) of slightly less than 400.
I commented my code (in a single jupyter nb) as best as I could so that it hopefully is as easy as possible to follow along if you are interested.

Opposed to previous posts in this thread I also did not find dqn to be very sensitive to the random seed:

My hints:
1) Use the right initializer! The dqn uses the Relu activation function and the right initializer is He.
https://www.youtube.com/watch?v=s2coXdufOzE&t=157s
In tensorflow use tf.variance_scaling_initializer with scale = 2
2) I found that Adam works fairly well so before implementing the RMSProp optimizer DeepMind used (not the same as in TensorFlow) I would try to get it to work with Adam. I used a learning rate of 1e-5. In my experiments larger learning rates had the effect that the reward plateaued at around 100 to 150.
3) Make sure you are updating the networks in the right frequency: The paper says that the target network update frequency is "measured in the number of parameter updates" whereas in the code it is measured in the number of action choices/frames the agent sees.
4) Make sure that your agent is actually trying to learn the same task as in the DeepMind paper!!!
4.1) I found that passing the terminal flag to the replay memory, when a life is lost, has a huge difference also in Breakout. This makes sense since there is no negative reward for losing a life and the agent does "not notice that losing a life is bad".
4.2) DeepMind used a minimal set of 4 actions in Breakout, several versions of open ai gym's Breakout have 6 actions. Additional actions can alter the difficulty of the task the agent is supposed to learn drastically! The Breakout-v4 and BreakoutDeterministic-v4 environments have 4 actions (Check with env.unwrapped.get_action_meanings()).
5) Use the Huber loss function, the Mnih et al 2013 paper called this error clipping.
6) Normalize the input to the interval [0,1].
I hope you can get it to work in your own implementation, good luck!! Fabio
 sloanqin
commented
6 years ago
sloanqin
commented
6 years ago Has anyone solved this problem for denny's code?
 peter-peng-w
commented
6 years ago
peter-peng-w
commented
6 years ago Is there anything to do to solve the problem? Should we use the deterministic environment, like 'BreakoutDeterministic-v4' and should we change the optimizer from RMSprop to Adam since it seem s that DeepMind change to using Adam in their rainbow paper.
fg91
commented
6 years ago If you want to try to improve Denny's code, I suggest you start with the following:
1) Use Adam and a learning rate of 0.00001. DeepMind used 0.0000625 in the Rainbow paper for all the environments. I don't think that RMSProp is the problem in Denny's code in general but maybe the learning rate is not right and I can confirm that Adam with 0.00001 works well in Breakout.
2) Make sure that the terminal flag is passed when a life is lost!
3) Use the tf.variance_scaling_initializer with scale = 2, not Xavier (I assume the implementation uses RELU as activation function in the hidden layers like in the DeepMind papers?!).
4) Does the implementation put 1 million transitions into the replay memory or less?
5) I don't think the "Deterministic" matters that much atm...
6) Make sure you are updating the networks in the right frequency (see my previous post).
Keep us updated, if you try these suggestions :)
 AnubhavGupta3377
commented
4 years ago
AnubhavGupta3377
commented
4 years ago From what I can see, this behavior might be due to the size of replay memory used. Replay memory plays a very critical role in the performance of DQN (read extended table-3 of the original paper https://daiwk.github.io/assets/dqn.pdf).
I also implemented DQN (in Pytorch) with replay memory size of 80,000. After training the model for 12000 episodes (more than 6.5 M steps), it could only reach the evaluation score of around 15. So, my guess is that Denny's code might also be having the same problem.
For those who have seen/solved this or similar issues, it would be great if you can shed some light on whether you observed the same behavior.
 willtop
commented
3 years ago
willtop
commented
3 years ago Hello everyone, interesting thread here.
I would like some help to clarify my confusion here:
Thanks a lot if anyone can confirm on this!
 wetliu
commented
3 years ago
wetliu
commented
3 years ago Hello. I have tried many different things before, including changing the optimizer to what the paper has said, or preprocess the frames as closs as possible to the paper did, but still has a low value. The key thing I found is set "done" flag after every time the agent loses its life. This is super important. I have some benchmark results in https://github.com/wetliu/dqn_pytorch. Thank you for the help in this thread. I deeply appreciate it!
 GauravBhagchandani
commented
8 months ago
GauravBhagchandani
commented
8 months ago Sorry for reviving this thread again, but did anyone figure out what the issue was? I'm attempting the same task (Breakout) and my train reward is stuck at 15-20 at 10M steps. I'm using a replay buffer of 200k, 4 gradient updates per iteration, 5e-4 as the learning rate.
Also using the He initializer as @fg91 mentioned in his comment, DDQN and all other optimizations mentioned as well. I'm not sure if I'm doing it wrong or I just need to wait to train it more.
wetliu
commented
8 months ago @GauravBhagchandani The key thing I found is set "done" flag after every time the agent loses its life. This is super important.
GauravBhagchandani
commented
8 months ago @wetliu Thanks for the reply! I have done that as well, hasn't made much of a difference. It's such a pain because the training takes so long for any small change. Do you know how many steps are needed to reach at least 100+ on the train score?
wetliu
commented
8 months ago @GauravBhagchandani I have tried a bunch of environments after that update and can successfully train the models with less steps reported in the paper. You can refer the code here https://github.com/wetliu/dqn_pytorch.
GauravBhagchandani
commented
8 months ago I got past the 20 train reward barrier. I was using SGD as the optimizer with 0.9 as the momentum. I switched to Adam with an epsilon of 1e-4 and that seemed to do the trick for me. It's currently training but I'm at 6.7M samples so far with train rewards around 30-40 and test up to 300. Currently, the model gets stuck after it tunnels through and breaks a lot of the blocks. It just stops moving. I think that'll get resolved as it trains more.
Update: It plateaued at 30-40 for even 20M steps. I'm a bit lost now on what to do to fix this. It's really annoying.
@wetliu Is there any chance I could show you my code and get some guidance?
Hi Denny,
Thanks for this wonderful resource. It's been hugely helpful. Can you say what your results are when training the DQN solution? I've been unable to reproduce the results of the DeepMind paper. I'm using your DQN solution below, although I did try mine first :)
While training, the TensorBoard "episode_reward" graph peaks at an average reward of ~35, and then tapers off. When I run the final checkpoint with a fully greedy policy (no epsilon), I get similar rewards.
The DeepMind paper cites rewards around 400.
I have tried 1) implementing the error clipping from the paper, 2) changing the RMSProp arguments to (I think) reflect those from the paper, 3) changing the "replay_memory_size" and "epsilon_decay_steps" to the paper's 1,000,000, 4) enabling all six agent actions from the Open AI Gym. Still average reward peaks at 35.
Any pointers would be greatly appreciated.
Screenshot is of my still-running training session at episode 4878 with all above modifications to dqn.py: