 fferreres
commented
8 years ago
fferreres
commented
8 years ago For an example see: https://openreview.net/pdf?id=Hk3mPK5gg
To reduce the correlation of game experience, Asynchronous Advantage Actor-Critic Model [Mnih et al. (2016)] runs independent multiple threads of the game environment in parallel. These game instances are likely uncorrelated, therefore their experience in combination would be less biased. For on-policy models, the same mutual reinforcement behavior will also lead to highly-peaked π(a|s) towards a few actions (or a few fixed action sequences), since it is always easy for both actor and critic to over-optimize on a small portion of the environment, and end up “living in their own realities”. To reduce the problem, [Mnih et al. (2016)] added an entropy term to the loss to encourage diversity, which we find to be critical.
Intuitively, it adds more cost to actions that too quickly dominate, and the higher cost favors more exploration (on top of the random e-greediness).
 IbrahimSobh
IbrahimSobh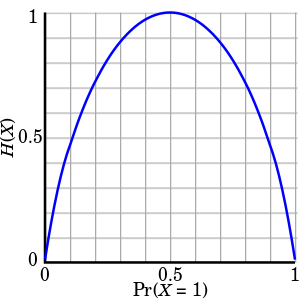
 aistrych
aistrych deependersingla
deependersingla the0demiurge
the0demiurge According to the Asynchronous Methods for Deep Reinforcement Learning, the entropy was added to the policy gradient, which means we want to maximize the log(p) and maximize entropy as well.
According to the Asynchronous Methods for Deep Reinforcement Learning, the entropy was added to the policy gradient, which means we want to maximize the log(p) and maximize entropy as well. akaniklaus
akaniklaus shtse8
shtse8 mimoralea
mimoralea Flock1
Flock1
I do not understand how adding entropy to loss will encourage exploration
I understand that Entropy is a measure of unpredictability, or measure of randomness.
H(X) = -Sum P(x) log(P(x))
While training, we want to reduce the loss. By adding the Entropy (of possible actions ) to the loss, we will reduce the Entropy too (reduce unpredictability)
When all actions have almost same probability, then Entropy will be high When one action has near 1 probability, Entropy will be low
In the beginning of training, almost all actions have same probability. After some training, some actions get higher probability (in the direction of getting more rewards), and entropy is reduced over time.
However, I am confused, how adding entropy to loss will encourage exploration?