 dgunning
commented
6 months ago
dgunning
commented
6 months ago This is much appreciated, you checking this. I'll look into it
Closed ilias-ant closed 3 months ago
dgunning
commented
6 months ago This is much appreciated, you checking this. I'll look into it
 rivera-lanasm
commented
4 months ago
rivera-lanasm
commented
4 months ago as someone interested in this project, I would like to understand the nature of the this bug. Would it be correct to refer to this module, https://github.com/dgunning/edgartools/blob/main/edgar/financials.py, for the potential source of the parsing issue?
dgunning
commented
4 months ago Yes that is correct, financials.py maps data from the XBRL to the financial table.
For this bug the mapping pulls the right data up to 2016.
 ilias-ant
commented
4 months ago
ilias-ant
commented
4 months ago @dgunning is there a sensible fix here?
dgunning
commented
4 months ago @ilias-ant could the 2016 10-K financials be wrong or at least partially wrong?
Part of the remedy for this is building a test harness that can cover the time (years) and space (companies) dimensions.
I will do an investigation this weekend.
 emestee
commented
4 months ago
emestee
commented
4 months ago @dgunning the issue appears to be not the filings, it is with how the timeframe of the fact is treated.
When constructing a dataframe, you are kind of reconstructing the document, and need to map facts to the specific period that the filing covers, i.e. by start and end, so reconstructing a 10-K and a 10-Q would use different periods when looking up facts. For this same reason, it is meaningless to ask a specific filing for "a" fact from the fact table, because the filing can contain more than one fact statement covering different periods, as is the case here:
import pandas as pd
from edgar import *
df = Company("AAPL").get_facts().to_pandas()
pd.set_option('display.float_format', lambda x: '%.3f' % x)
df.query("fact == 'NetIncomeLoss' and accn == '0001628280-16-020309'")
In other words, any filing object must read off the "main" period which it covers, and the conversion to a dataframe object must select only the facts that pertain to this period, because ancillary facts (e.g. horizontals of past quarters) do not belong to the period covered by the filing and must be excluded, since this is the behaviour end users expect.
There is however an associated problem which does not exhibit in this case. Multiple filings can make fact statements for one specific period, and the value of the fact can be changed by a more recent filing, if this filing is an amendment of a previous filing. For this reason, the EDGAR concepts API uses the frame attribute. When the frame attribute is absent from the fact object, it means that this version of this fact is no longer the most recent version of the fact relative to the time frame for which the fact was filed. This happens even if the subsequent filing was not amending the fact or changing its value, which is something you need to be aware of because if you try to implement the reconstruction of a filing to a dataframe by looking at the frame attribute of facts together with the frame attribute, you may find that the frame attribute in the current filing is empty for every version of the fact, because it was mentioned in subsequent filings.
This is visible here:
df.query("fact == 'NetIncomeLoss' and end == '2016-09-24'")
Neither of the facts in our target accession 0001628280-16-020309 have the frame attribute, because subsequent filings mentioned these facts and could have changed their value.
In other words, the correct behaviour for reconstructing a filing into a dataframe is looking for relevant facts not inside the specific filing that you're converting, but inside the entire body of facts, and use only those that cover the period of the filing and have the frame attribute specified, and provide a way to turn off this behaviour so that the reconstructed filing document is either "most recently correct version of the data for this period" or "exactly what the filing said at that point of time, ignoring any future amendments".
dgunning
commented
4 months ago Thanks for that comprehensive analysis. That definitely holds for company facts and it's a good pointer into adjusting the data as the years progress. And that logic will definitely be added when I further refine the Fact features.
This holds for the company facts attached to the company. For filings though the data comes from the xbrl attached to that specific filing and for the 2016 filing is effectively frozen as of that year.
I think this specific bug comes from something else and I got closer last night to figuring out that it has to do with the incorrect period logic making it point at the value for the quarter not the year.
Also the Net Income is missing, and Apple seems to have changed the mapped fact since 2016. This brings up my biggest issue which is building a test harness large enough to cover all the companies market and back in time.
I will continue digging and could have a fix this weekend.
dgunning
commented
4 months ago Found the bug - it's picking up the quarter's values in some cases. Should be straightforward to patch, figuring out side impacts require careful thought. So will work on it on the weekend.
Previously, I had a check for start and end dates being approximately 365 days apart. Some companies however report start = end date so it broke those financials. I have to figure out how to to get it work for all filings.
The bigger deal is writing a test harness. I have a list of 100 popular stocks so if someone can start thinking about how to test that would be appreciated
dgunning
commented
4 months ago Essentially fixed. Now testing
emestee
commented
4 months ago What's your idea of a test harness? #Is your goal to detect this kind of issues using real world data, or in real world data?
dgunning
commented
4 months ago Fixed in 2.26.0
dgunning
commented
4 months ago @emestee I have a list of 100 popular tickers and I am sampling the financials across a sample of years. Manually it's only possible to do a few. Would be nice to automate.
To test the automated extraction of financials requires another method to extract the financials. Maybe we write an LLM based extractor
emestee
commented
4 months ago Thanks for the fix!
If I understand correctly the way your code does it right now, you are essentially reconstituting a financial statement based on a predefined list of facts pulled from that statement (as opposed to the way I described previously, in which the facts are pulled from the entire body of company facts). The inherent problem with this approach is that some items can be just missing from the predefined list, and some items can come from custom schemata that is completely unique for a single instrument. For example, MercadoLibre specifies some line items for crypto assets using the standard SEC/FASB hierarchy, and some using their own custom one. This implies that totals or subtotals in reconstituted statement may not add up as some of the line items would be hidden, since they are not on the predefined list. This is particularly likely to affect subtotals. Since the way to test the reconstituted statement would be to assert that it complies with the accounting equation, any test harness would for the above reason inevitably fail on any but the most basic statements; and applying the harness would cause you to go into a potentially neverending cycle of discovering and adding the relevant facts.
Here's an example:
co = Company("MELI")
co.get_filings(form='10-K', filing_date='2024-02-23').get(0).obj().income_statementMeanwhile the part of the income statement in EDGAR has this:
The provision for doubtful accounts is missing and thereby the subtotal for operating expenses does not add up.
In other words, with the current approach you would have to chase down individual missing items across an endless stream of statements. To solve this problem at the root, it is necessary to parse the RBL in any given document hierarchically, by identifying the mandatory container structures and extracting every fact in them hierarchically. This is non-trivial but far more reliable. In that case, you would be able to test each statement by verifying that the totals add up.
https://github.com/tooksoi/ScraXBRL already does this:
dgunning
commented
4 months ago This is good. Thanks. A key reason to create edgartools is to gradually gain deep knowledge about how the SEC system works and key is through community contributions like this. Basically every feature in library is an attempt at recreation of the semantics of the US corporate economy but the limitations are knowledge and time. This adds to my knowledge.
The underlying structures are already parsed, since it was evident that they represent some structure, so it is possible to recreate the financial statements. And I was already thinking ahead to Financials V3 so this information helps.
If you want to reopen this issue or create a new one, that's fine let's work on it together
emestee
commented
4 months ago From what I understood through cursory reading of this guide, the design of BRL is something like this: facts are recorded as a single-dimensional list, but they are associated with contexts, whereas contexts specify the position of facts in many dimensions. It's been a long while since I touched anything XML, but the basic idea is to do the opposite of what's intuitive.
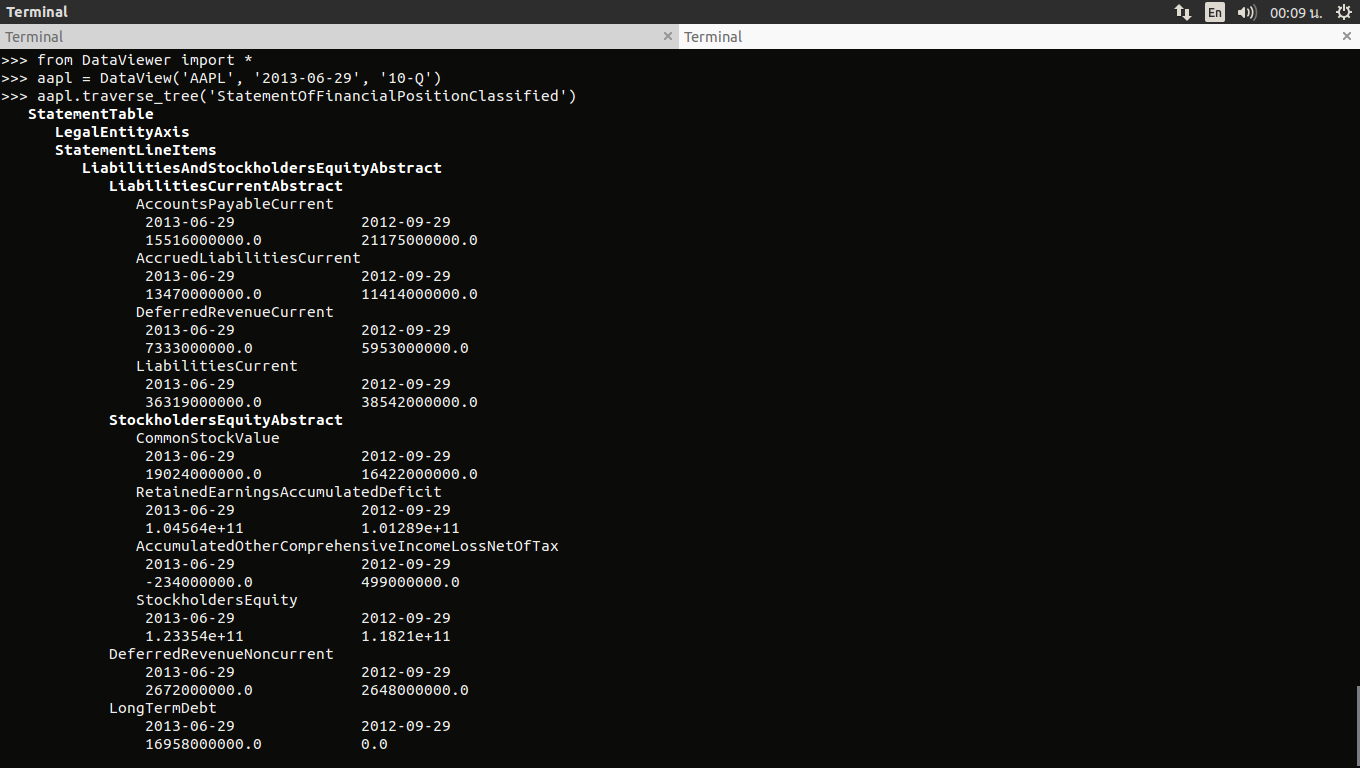
The underlying structures I referred to are, from my understanding, not the XML (i.e. transport) structures of BRL, but rather the special type of an abstract fact that is used as a container; e.g. LiabilitiesAbstractCurrent is a parent for all the child items in current liabilities in the balance sheet. In turn, its parent is LiabilitiesAbstract, but LiabilitiesAbstract is specified to have multiple possible parents, i.e. for the balance sheet it's going to be LiabilitiesAndStockholdersEquityAbstract, as you can observe in the screenshot from ScraXRBL.
I imagine you'd have to change your parser and throw away the fact mapping logic completely. I might try my hand at this but it isn't a small project and you understand your code way better than I do. I wonder if one could cheat by just using existing libraries to do this.
dgunning
commented
4 months ago Let's start planning for Financials V3. I've looked into it and I need to implement at least the XBRL presentation file. It's perfectly doable but I'm tied up at the moment.
dgunning
commented
4 months ago Financials V3 in progress.
emestee
commented
3 months ago Hey,
If this helps, here are the entry points from the FASB taxonomy that group the line items in the mandatory filing statements:
dgunning
commented
3 months ago Closing this issue and we will handle further financials and XBRL related issues using discussions elsewhere
Python version: 3.12.2 (main, Mar 12 2024, 08:01:18) [GCC 12.2.0]edgartools version: 2.21.1Minimum Reproducible Example
yields the following:
i.e. apart from the missing
Net Sales, one can also identify some incorrect numerical values for:Gross ProfitNet IncomeEarnings Per ShareUpon closer examination, it seems that the parser may have "picked up" the values not from the
CONSOLIDATED STATEMENTS OF OPERATIONSbut fromNote 12 – Selected Quarterly Financial Information (Unaudited)(see screenshot below).p.s. May also happen to 10Ks from other fiscal years prior to 2021 (based on my findings, 2021 and beyond is correct). p.s.#2 Keep up the great work, this library is a true gift to the community <3