Open dhkim0225 opened 2 years ago
아 ㅋㅋ relu 가 빠르다고 ㅋㅋ
paper
A == self attention function attention output 은 다음과 같이 정의된다.
보통 S 는 다음과 같이 정의된다.
self-attention 은 왜 잘 될까? (좀 더 깊은 대답은, #98 의 대답이 되겠지만,, 저자들은 이렇게 주장한다.)
2개의 feature 만 유지하면서, 더 효율적인 방식으로 이를 해결할 수 없을까?
linear transformation 부분을 relu 로 대체함.
이걸로 non-negative 는 유지가 되는 거고, smoothing 은 어떻게 할까? 0~1 로 re-weight 만 잘 할 수 없을까? 저자들이 고민하다가 내놓은 해결책은, cos re-weighting
query dimension == N, key&value dimension == M 이다. relu * relu dot product 이후에 reweight 를 다음과 같이 수행해 준다. i-j < M 이기 때문에, 0~1 값으로 곱해주는 거다.
딱 느낌이 오겠지만,
그래서, LRA benchmark 에서도 Pathfinder 성능은 낮다.
위 수식을 정리하면 다음과 같다.
따라서 최종 식은,
아 ㅋㅋ relu 가 빠르다고 ㅋㅋ
paper
self-attention
A == self attention function attention output 은 다음과 같이 정의된다.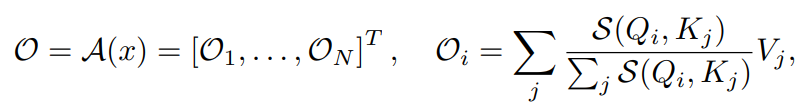
보통 S 는 다음과 같이 정의된다.
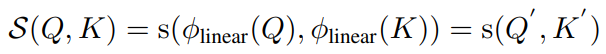
self-attention 은 왜 잘 될까? (좀 더 깊은 대답은, #98 의 대답이 되겠지만,, 저자들은 이렇게 주장한다.)
2개의 feature 만 유지하면서, 더 효율적인 방식으로 이를 해결할 수 없을까?
cosFormer
linear transformation 부분을 relu 로 대체함.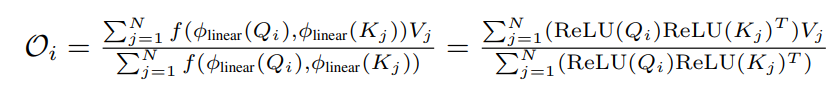
이걸로 non-negative 는 유지가 되는 거고, smoothing 은 어떻게 할까? 0~1 로 re-weight 만 잘 할 수 없을까? 저자들이 고민하다가 내놓은 해결책은, cos re-weighting
query dimension == N, key&value dimension == M 이다. relu * relu dot product 이후에 reweight 를 다음과 같이 수행해 준다. i-j < M 이기 때문에, 0~1 값으로 곱해주는 거다.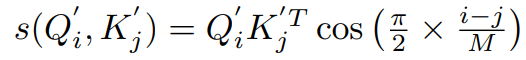
딱 느낌이 오겠지만,
그래서, LRA benchmark 에서도 Pathfinder 성능은 낮다.
위 수식을 정리하면 다음과 같다.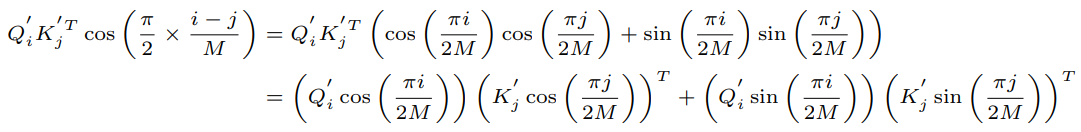
따라서 최종 식은,



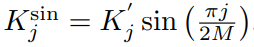
Result
WikiText-103
LRA
Speed
Others