 BarclayII
commented
6 years ago
BarclayII
commented
6 years ago Hmm interesting question. From the perspective of networkx I would expect that the DGLGraph is mutable.
In fact, I will probably write the example above like this:
# GCN module
class GCN(nn.Module):
def __init__(self):
self.updmod = NodeModule()
def forward(self, nx_graph, features):
g = DGLGraph(nx_graph)
g.set_n_repr(features)
g.update_all(message_func='from_src',
reduce_func='sum',
update_func=self.updmod,
batchable=True)
return g.get_n_repr()
# main loop
nx_graph, features, labels = load_data('cora')
gcn = GCN()
for epoch in range(MAX_EPOCH):
logits = gcn(nx_graph, features)
loss = NLLLoss(logits, labels)
loss.backward()
# ...EDIT: if nx_graph is fixed, we can of course store it (and the DGLGraph counterpart) as a module attribute during instantiation.
 jermainewang
jermainewang zzhang-cn
zzhang-cn
Here is a question we found when writing models using DGL. Let's first look at a following GCN example:
Can you spot the bug in this code?
The bug is that we need to reset the input features to the graph at the beginning of each iteration:
This is a very subtle mistake, but we feel that this worth our attention. The reason of such mistake is that we are very used to what autograd DNN frameworks provide us -- immutability. In Pytorch, all tensor operations are immutable (i.e, they always return new tensors). As a result, following Pytorch code is totally fine:
As a contrast, because DGL is derived from networkx, our APIs are mutable. For example, the
update_alldoes not return a new graph. It in fact changes the node representations internally. Because of this, even if user writegg = gcn(g), theggandgare pointing to the same DGLGraph and the node reprs have been updated afterupdate_all.This is an inherent conflict of networkx and Pytorch/TF/MX. I want to know about the opinions from model developers (@GaiYu0 @BarclayII @ivanbrugere @zzhang-cn ). What do you guys think? Do you find this bug very subtle or actually a cunning pitfall? Do you like the current mutable graph or prefer immutable objects?
Here, I also want to share more about what if we want to support immutable graph object. What are the challenge and solution? To make DGLGraph immutable, we need to handle two things:
For transformations on node/edge features (e.g.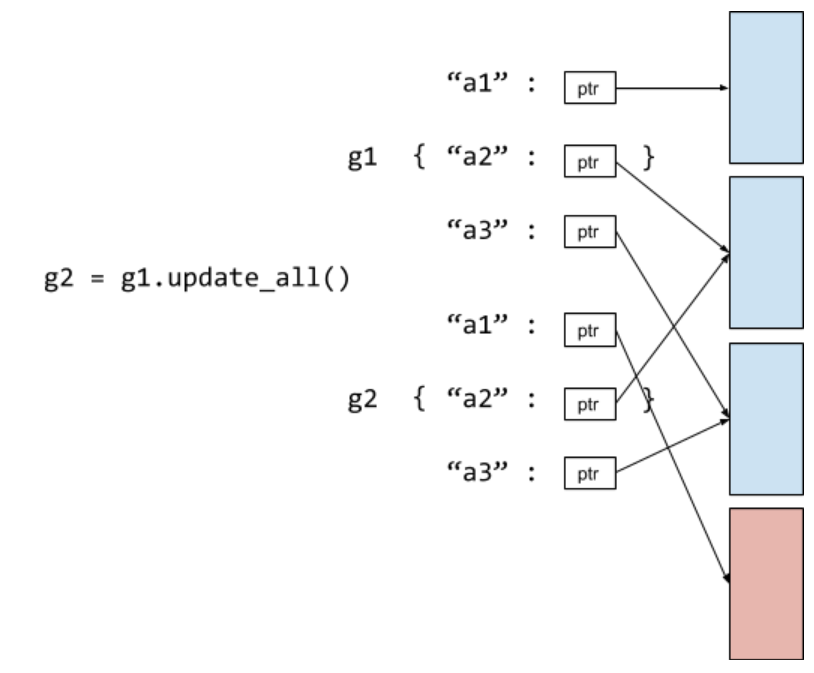
sendto,recv,update_all, ...), we can return a new graph containing different data as follows. In the following example, note that theupdate_allfunction returns a new graph g2. Initially the graph (i.e, g1) has three node features a1, a2, a3. The node update function reads all node features but only update a1 attribute. As a result, the new g2 node storage (called node frame) reuses the other two feature columns but use the newly generated a1 column. Such change to the system should have little overhead.For transformations on graph structures, this is a little tricky. For users that are used to networkx, they actually expect mutable behaviors as follows:
We can change it to immutable by using Copy-On-Write. The question is shall we?