 hcho3
commented
6 years ago
hcho3
commented
6 years ago @Laurae2 Thank you for preparing the GBT benchmark. It has been helpful in identifying the problem spot.
Closed hcho3 closed 1 year ago
hcho3
commented
6 years ago @Laurae2 Thank you for preparing the GBT benchmark. It has been helpful in identifying the problem spot.
 trivialfis
commented
6 years ago
trivialfis
commented
6 years ago @hcho3 Does OpenMP guided schedule help load balancing? If so the ellpack won't be very useful.
hcho3
commented
6 years ago My guess is that static allocation of work using ellpack would achieve balanced workload with lower overhead than guided or dynamic mode of OpenMP. With dynamic, you get runtime overhead of maintaining work stealing queue
 CodingCat
commented
6 years ago
CodingCat
commented
6 years ago might be a bit off-topic, do we have benchmark results of approx?
We find out the sub-optimal speedup with multi-threading in our internal environment...want to look at others' data
hcho3
commented
6 years ago @CodingCat The linked benchmark suite only uses hist. Does approx show performance degradation like hist (e.g. 36 threads slower than 3 threads)?
CodingCat
commented
6 years ago @hcho3 due to the limitation in our cluster, we can test only with up to 8 threads...but we find very limited speedup comparing 8 to 4.....
hcho3
commented
6 years ago @CodingCat You mean 8 threads run slower than 4?
 Laurae2
commented
6 years ago
Laurae2
commented
6 years ago @CodingCat approx has so poor scaling I didn't even want to try benchmarking it. It doesn't even scale properly on my 4 core laptop (3.6 GHz), therefore I don't even imagine with 64 or 72 threads.
@hcho3 I'll get a look at it using your repository with VTune later.
For those who want to get detailed performance in VTune, one can use the following to add to the header:
#include <ittnotify.h> // Intel Instrumentation and Tracing TechnologyAdd the following before what you want to track outside a loop (rename the strings/variables):
__itt_resume();
__itt_domain* domain = __itt_domain_create("MyDomain");
__itt_string_handle* task = __itt_string_handle_create("MyTask");
__itt_task_begin(domain, __itt_null, __itt_null, task);Add the following after what you want to track outside a loop (rename the strings/variables):
__itt_task_end(domain);
__itt_pause();And start a project with VTune with the correct parameters for the number of threads. Start the executable with paused instrumentation to do performance analysis.
CodingCat
commented
6 years ago @hcho3 it's not slower, but maybe only 15-% speedup with 4 more threads...(if I conduct more experiments, I would suspect the results would even converge.....
CodingCat
commented
6 years ago @Laurae2 looks like I am not the only one
Laurae2
commented
6 years ago @hcho3 I'll try to get you some scaling results before the end of this week if no one does on exact, approx and hist, all with depth=6, on commit e26b5d6.
I migrated recently my compute server, and I'm re-doing new benchmarks on Bosch on a new machine with 3.7 GHz all turbo / 36 cores / 72 threads / 80 GBps RAM bandwidth this week.
 RAMitchell
commented
6 years ago
RAMitchell
commented
6 years ago The fast_hist updater should be much faster for distributed xgboost. @CodingCat I am surprised no one has tried to add AllReduce calls so it works in distributed mode.
hcho3
commented
6 years ago @RAMitchell I was pretty new when I wrote the fast_hist updater, so it lacks distributed mode support. I'd like to get to it after 0.81 release.
hcho3
commented
6 years ago @Laurae2 FYI, I ran your benchmark suite on a C5.9xlarge machine and the results for XGBoost hist seem to be consistent with your previous results. I can put up the numbers if you'd like.
hcho3
commented
6 years ago @Laurae2 Also, I have access to EC2 machines. If you have a script you'd like to run on a EC2 instance, let me know.
CodingCat
commented
6 years ago @RAMitchell I was pretty new when I wrote the fast_hist updater, so it lacks distributed mode support. I'd like to get to it after 0.81 release.
@hcho3 if you don't mind, I can take the challenge to get the distributed faster histogram algorithm, I am currently half time on it in my Uber job and next year may have more time on xgboost
hcho3
commented
6 years ago @CodingCat That would be great, thanks! Let me know if you have any question about the 'hist' code.
hcho3
commented
6 years ago @CodingCat FYI, I plan to add unit tests for 'hist' updater soon after 0.81 release. That should help when it comes to adding distributed support.
Laurae2
commented
6 years ago @hcho3 @CodingCat approx seems to have been removed in the last month, is it an expected behavior?
https://github.com/dmlc/xgboost/commit/70d208d68c3a32aaa4fcd6aa456f286a4da5912f#diff-53a3a623be5ce5a351a89012c7b03a31 (PR https://github.com/dmlc/xgboost/pull/3395 has removed tree_method = approx?) => getting identical results between approx and non approx...
hcho3
commented
6 years ago @Laurae2 Looks like the refactor removed a INFO message about approx being selected. Otherwise, approx should be still available.
hcho3
commented
6 years ago @Laurae2 Actually, you are right. Even though approx is still in the codebase, for some reason it is not being invoked even when tree_method=approx is set. I will investigate this bug ASAP.
hcho3
commented
6 years ago Issue #3840 was filed. Release 0.81 won't be released until this is fixed.
Laurae2
commented
6 years ago @hcho3 I'm finding something very strange on my server with fast histogram, I'll let you know the results if tomorrow the benchmark computation finishes (we're talking about huge negative efficiency of fast histogram, it's so huge I'm trying to measure it but hope it doesn't get too long).
For approx, the poor efficiency is way better than expected, but I don't expect it to be true for any computer (maybe it gets better with newer Intel CPU generation = higher RAM frequency?). I'll post the data once fast histogram finishes on my server.
For information, I'm using Bosch dataset with 477 features (the features with less than 5% missing values).
Reached over 3000 hours of CPU time... (at least my server is put for good use for a while) next for me will be to look at https://github.com/hcho3/xgboost-fast-hist-perf-lab/blob/master/src/build_hist.cc with Intel VTune.
@hcho3 If you want, I can provide you my benchmark R script once my server finishes computing. I ran with depth=8 and nrounds=50, for all tree_method=exact, tree_method=approx (with updater=grow_histmaker,prune workaround, before #3849 ), and tree_method=hist, from 1 to 72 threads. It may uncover more interesting stuff to work on (and you would be able to test it on AWS also).
Laurae2
commented
6 years ago Please see the preliminary results below, ran 7 times to average results. Make sure to click to view better. Synthetic table provided. Unlike the plots shows, the CPUs were not pinned.
The charts clearly seem way different than the ones I was prepared for... (due to how strange the behavior is I'm re-running this with UMA on (NUMA off)). Later I'll check with Intel VTune.
Hardware and Software:
pti=off spectre_v2=off spec_store_bypass_disable=off l1tf=off noibrs noibpb nopti no_stf_barrier-O3 -mtune=nativeMeltdown / Spectre protections:
laurae@laurae-compute:~$ head /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/l1tf <==
Mitigation: PTE Inversion; VMX: vulnerable
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spec_store_bypass <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Vulnerable| Threads | Exact (efficiency) | Approx (efficiency) | Hist (efficiency) |
|---|---|---|---|
| 1 | 1367s (100%) | 1702s (100%) | 69.9s (100%) |
| 2 | 758.7s (180%) | 881.0s (193%) | 52.5s (133%) |
| 4 | 368.6s (371%) | 445.6s (382%) | 31.7s (221%) |
| 6 | 241.5s (566%) | 219.6s (582%) | 24.1s (290%) |
| 9 | 160.4s (852%) | 194.4s (875%) | 23.1s (303%) |
| 18 | 86.3s (1583%) | 106.3s (1601%) | 24.2s (289%) |
| 27 | 66.4s (2059%) | 80.2s (2122%) | 63.6s (110%) |
| 36 | 52.9s (2586%) | 60.0s (2837%) | 55.2s (127%) |
| 54 | 215.4s (635%) | 289.5s (588%) | 343.0s (20%) |
| 72 | 218.9s (624%) | 295.6s (576%) | 1237.2s (6%) |
xgboost Exact speed:

xgboost Exact efficiency:

xgboost Approx speed:

xgboost Approx efficiency:

xgboost Histogram speed:

xgboost Histogram efficiency:

RAMitchell
commented
6 years ago Looks like a problem with multiple sockets.
Laurae2
commented
6 years ago @RAMitchell Seems to be an issue with the availability of NUMA nodes, I can replicate this issue (with a way worse result with less threads during training) using Sub NUMA Clustering (2 sockets = 4 NUMA nodes instead of 1 socket = 2 NUMA nodes).

xgboost like most machine learning algs have no optimization for handling NUMA nodes. But that would be a 2nd issue. Therefore, they are not appropriate for multi-socket environment nor when NUMA nodes are available through COD (Cluster on Die) or SNC (Sub NUMA Clustering), and hyperthreading makes the workload imbalance a huge penalty on them.
Issue 1 would be about the huge degradation of multithread performance in xgboost hist mode (this issue).
Issue 2 would be about NUMA optimization (another issue to open).
Laurae2
commented
6 years ago Here are the results with NUMA disabled. I paired the results with NUMA enabled for comparison. Also added 71 threads to showcase the performance before the CPU gets overwhelmed with the kernel scheduler at 72 threads (more resources required than available).
UMA fares way better than NUMA for multithreading, this is an expected result of memory interleaving on a non-NUMA aware process.
Time time:
| Threads | Exact NUMA |
Exact UMA |
Approx NUMA |
Approx UMA |
Hist NUMA |
Hist UMA |
|---|---|---|---|---|---|---|
| 1 | 1367s | 1667s | 1702s | 1792s | 69.9s | 85.6s |
| 2 | 758.7s | 810.3s | 881.0s | 909.0s | 52.5s | 54.1s |
| 4 | 368.6s | 413.0s | 445.6s | 452.9s | 31.7s | 36.2s |
| 6 | 241.5s | 273.8s | 219.6s | 302.4s | 24.1s | 30.5s |
| 9 | 160.4s | 182.8s | 194.4s | 202.5s | 23.1s | 28.3s |
| 18 | 86.3s | 94.4s | 106.3s | 105.8s | 24.2s | 31.2s |
| 27 | 66.4s | 66.4s | 80.2s | 73.6s | 63.6s | 37.5s |
| 36 | 52.9s | 52.7s | 60.0s | 59.4s | 55.2s | 43.5s |
| 54 | 215.4s | 49.2s | 289.5s | 58.5s | 343.0s | 57.4s |
| 71 | 218.3s | 47.01s | 295.9s | 56.5s | 1238.2s | 71.5s |
| 72 | 218.9s | 49.0s | 295.6s | 58.6s | 1237.2s | 79.1s |
Efficiency table:
| Threads | Exact NUMA |
Exact UMA |
Approx NUMA |
Approx UMA |
Hist NUMA |
Hist UMA |
|---|---|---|---|---|---|---|
| 1 | 100% | 100% | 100% | 100% | 100% | 100% |
| 2 | 180% | 206% | 193% | 197% | 133% | 158% |
| 4 | 371% | 404% | 382% | 396% | 221% | 236% |
| 6 | 566% | 609% | 582% | 593% | 290% | 280% |
| 9 | 852% | 912% | 875% | 885% | 303% | 302% |
| 18 | 1583% | 1766% | 1601% | 1694% | 289% | 274% |
| 27 | 2059% | 2510% | 2122% | 2436% | 110% | 229% |
| 36 | 2586% | 3162% | 2837% | 3017% | 127% | 197% |
| 54 | 635% | 3384% | 588% | 3065% | 20% | 149% |
| 71 | 626% | 3545% | 575% | 3172% | 6% | 120% |
| 72 | 624% | 3401% | 576% | 3059% | 6% | 108% |
UMA mode.
xgboost Exact speed:

xgboost Exact efficiency:

xgboost Approx speed:

xgboost Approx efficiency:

xgboost Histogram speed:

xgboost Histogram efficiency:

Laurae2
commented
5 years ago As commented in https://github.com/dmlc/xgboost/pull/3957#issuecomment-453815876, I tested the commits a2dc929 (pre CPU improvement) and 5f151c5 (post CPU improvement).
I tested using my Dual Xeon 6154 server (gcc compiler, not Intel), using Bosch for 500 iterations, eta 0.10, and depth 8, with 3 runs each for 1 to 72 threads. We notice a performance increase of about up to 50% (1/3 faster) for multithreaded workloads at peak performance.
Here are the results for before #3957 (commit a2dc929):

Here are the results for #3957 (commit 5f151c5):

Using the efficiency curves, we see the 50% scalability increase (this does not mean the issue is solved: we still have to improve it, if we can - ideally, if we can get to the 1000-2000% range that would be insanely great).
Efficiency curve of a2dc929:

Efficiency curve of 5f151c5:

hcho3
commented
5 years ago Thanks @Laurae2, I'll go ahead and pin this issue, so that it's always on top of the issue tracker. There is indeed more work to do.
Laurae2
commented
5 years ago @hcho3 @SmirnovEgorRu I am seeing a small CPU performance regression on singlethreaded workloads on 100% dense data with the commit 5f151c5 which incurs a 10%-15% penalty overall when doing hyperparameter tuning on X cores x 1 xgboost thread.
Here is an example of 50M rows x 100 column random dense data (gcc 8), requires at least 256GB RAM to train it properly from Python / R, run 3 times (6 days).
Commit a2dc929 :

Commit 5f151c5 :

Although they lead to very similar multithreaded performance, the singlethreaded performance is hit by a slower training (@SmirnovEgorRu 's improvements still scale faster, reaching in this 50M x 100 case 500% efficiency at 11 threads vs 13 threads before).
Excluding the gmat creation time, we have for singlethread on 50M x 100:
| Commit | Total | gmat time | Train time |
|---|---|---|---|
| a2dc929 | 2926s | 816s | 2109s |
| 5f151c5 | (+13%) 3316s | (~%) 817s | (+18%) 2499s |
 SmirnovEgorRu
commented
5 years ago
SmirnovEgorRu
commented
5 years ago @hcho3 @Laurae2 Generally Hyper-threading helps only in case of Core-bound algorithms, no memory-bound algorithm. HT helps to load pipeline of CPU by more instructions for execution. If most of instructions wait for execution of previous instructions (latency bound) - HT can really helps, in some specific workloads I observed speedup up to 1.5x times. However, if your application spends most of time on working with memory (memory-bound) - HT makes even worse. 2 hyper-threads share one cpu-cache and displace useful information each other. As result, we see performance degradation. Gradient Boosting - memory bound algorithm. Usage of HT shouldn't bring performance improvement in any cases and your maximum speedup due to threading vs 1thread version is limited by number of hardware cores. So, my opinion better to measure performance on CPU without HT.
What about NUMA - I observed the same problems at DAAL implementation. It requires control of memory usage by each core. I will look at it in the future.
What about small slowdown on 1 thread - I will investigate it. I think - fix is easy.
@hcho3 At the moment I'm working on the next part of optimizations. I hope I will be ready for new pull-request in near future.
hcho3
commented
5 years ago @SmirnovEgorRu Thank you again for your effort. FYI, there was a recent discussion about increasing amount of parallelism by performing level-wise node expansion: #4077.
hcho3
commented
5 years ago @Laurae2 Now that we merged in #3957, #4310, and #4529, can we assume that the scaling issue has been solved? Effects of NUMA may still be problematic.
Laurae2
commented
5 years ago @hcho3 I will rebench later to check, but from what I could notice there were performance regressions on production environments (especially #3957 causing more than 30x slowdown).
I'll check performance results with @szilard also.
Open example: https://github.com/szilard/GBM-perf/issues/9
 szilard
commented
4 years ago
szilard
commented
4 years ago The multicore scaling and actually also the NUMA issue has been largely improved indeed:
Multicore:

Very notable the improvement on smaller data (0.1M rows)


More details here:
https://github.com/szilard/GBM-perf#multi-core-scaling-cpu https://github.com/szilard/GBM-perf/issues/29#issuecomment-689713624
Also the NUMA issue has been largely mitigated:



hcho3
commented
4 years ago @szilard Thank you so much for taking time to do the benchmark! And it's great news that XGBoost has improved in the CPU performance scaling.
szilard
commented
4 years ago Yeah, great job everyone on this thread for having accomplished this.
szilard
commented
4 years ago FYI, here are the training times on 1M rows on EC2 r4.16xlarge (2 sockets with 16c+16HT each) on 1, 16 (1so&no HT) and 64 (all) cores for different versions of xgboost:

SmirnovEgorRu
commented
4 years ago @szilard, thank you very much for the analysis! Good to hear that the optimizations work.
P.S. Above I see that XGB 1.2 has some regression against 1.1 version. It's very interesting info, let me clarify this. It's not expected for me.
SmirnovEgorRu
commented
4 years ago @szilard, if this topic is interesting for you - some background and results of the CPU optimizations are available in this blog: https://medium.com/intel-analytics-software/new-optimizations-for-cpu-in-xgboost-1-1-81144ea21115
szilard
commented
4 years ago Thanks @SmirnovEgorRu for your optimization work and for the link to the blog post (I did not see this post before).
To be easier to reproduce my numbers and to get new ones in the future and or other hardware, I made a separate Dockerfile for this:
https://github.com/szilard/GBM-perf/tree/master/analysis/xgboost_cpu_by_version
You'll need to set the CPU core ids for the first socket, no hyper threaded cores (e.g. 0-15 on r4.16xlarge, which has 2 sockets, 16c+16HT each) and the xgboost version:
VER=v1.2.0
CORES_1SO_NOHT=0-15 ## set physical core ids on first socket, no hyperthreading
sudo docker build --build-arg CACHE_DATE=$(date +%Y-%m-%d) --build-arg VER=$VER -t gbmperf_xgboost_cpu_ver .
sudo docker run --rm -e CORES_1SO_NOHT=$CORES_1SO_NOHT gbmperf_xgboost_cpu_verIt might be worth running the script several times, the training times on all cores usually show somewhat higher variability, not sure if because of the virtualization environment (EC2) or because of NUMA.
szilard
commented
4 years ago Results on c5.metal which has higher frequency and more cores than r4.16xlarge I have been using in the benchmark:
https://github.com/szilard/GBM-perf/issues/41
TLDR: xgboost takes the most advantage of faster and more cores vs other libs. 👍
szilard
commented
4 years ago I wonder though about this:

the speedup from 1 to 24 cores for xgboost is smaller for the larger data (10M rows, panels on the right) than for smaller data (1M rows, panels in the middle column). Is this some kind of increased cache hits or something that other libs don't have?
szilard
commented
4 years ago Here are some results on AMD:
https://github.com/szilard/GBM-perf/issues/42
Looks like the xgboost optimizations are working great on AMD as well.
It is about time to tackle the elephant in the room: performance on multi-core CPUs.
Description of Problem
Currently, the
histtree-growing algorithm (tree_method=hist) scales poorly on multi-core CPUs: for some datasets, performance deteriorates as the number of threads is increased. This issue was discovered by @Laurae2's Gradient Boosting Benchmark (GitHub repo).The scaling behavior is as follows for Bosch dataset: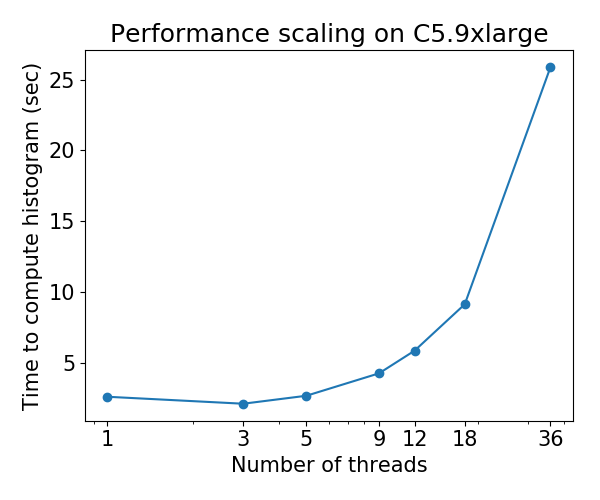
Call for Contribution
I have identified the performance bottleneck of the 'hist' algorithm and put it in a small repository: hcho3/xgboost-fast-hist-perf-lab. You can try to improve the performance by revising src/build_hist.cc.
Some ideas