 dmlls
commented
3 years ago
dmlls
commented
3 years ago Se ha decidido que se seguirá el patrón de API Gateway, en el que para el cliente existe un único punto de conexión, Ese punto de conexión, por detrás, realiza las peticiones necesarias a los diferentes microservicios de manera transparente al cliente.
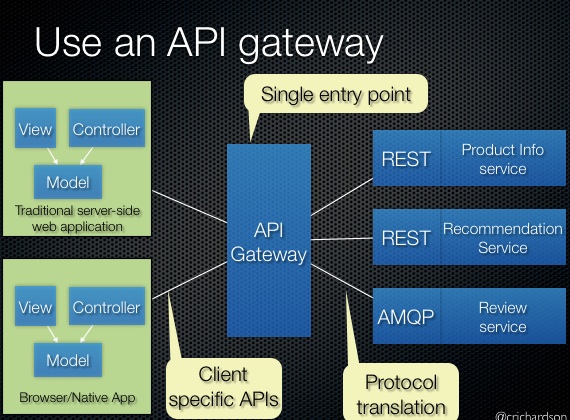
En nuestro caso, el cliente realizaría una petición al API Gateway incluyendo el texto a traducir. El API Gateway se comunicaría con los distintos microservicios (pre-procesador, motor de resumen, post-procesador, etc.) a fin de confeccionar el resumen, y finalmente respondería al cliente con el resumen generado.
Este patrón, además, ofrece la ventaja de que se puede llevar la adición, eliminación o refactorización de los microservicios, sin que el cliente tenga que preocuparse de estos cambios.
 clopezno
clopezno
Generar un diseño preliminar de cómo se organizarán los diferentes microservicios que componen el sistema.