 dominik-pichler
commented
10 months ago
dominik-pichler
commented
10 months ago maybe libraries like SpaCy, NLTK or Stanford NLP help
Closed dominik-pichler closed 9 months ago
dominik-pichler
commented
10 months ago maybe libraries like SpaCy, NLTK or Stanford NLP help
dominik-pichler
commented
10 months ago Pronounce will be replaced by reference entities.
Identify/Recognize all mentioned entities in the text
Solve Entity Disambiguation & Entity Linking Elon's vs Elon -> is the same but will not be recognized as the same thing
Co-Occurrence Graphs Evaluate the co-occurence of terms in a subtask
This could happen in multiple ways:
NLP Model (just as we did with the LLM right?), in Addition TACRED or Wiki80 could be helpful.
found @ https://neo4j.com/blog/text-to-knowledge-graph-information-extraction-pipeline/
dominik-pichler
commented
10 months ago dominik-pichler
commented
10 months ago Had a problem with coreference lib neuralcoref due to version conflicts. Due to time constraints, I'll take care of this last
dominik-pichler
commented
10 months ago 2) Where is the meaning of the sentences hidden? Or is it enough to ask where the ideas are hidden? Actually, I would first need a good working definition of ideas. In this context, ideas are to be understood as concepts that a subject creates in order to make decisions for action. In other words, a premise on the basis of which the world is interpreted. This interpretation is then the foundation on which action decisions are made
In this case, it is a matter of extracting acting relationships. In particular, relationships from (subject-verb-subject)^n. Example: X greets Z)
To be separated from sentient relations ( X feels y about Z) which should come in the next step!
Problem: How do you depict actions spanning across multiple sentences ?
Resources here: https://towardsdatascience.com/named-entity-recognition-with-nltk-and-spacy-8c4a7d88e7da
dominik-pichler
commented
10 months ago Question: In the english language: Is the gramar structured in order? Meaning, give the following Wordtpyes: S1 - a1 - S2 - a2 - S3, could a1 also effect S3 or is it always only affecting S2.
Meaning, what are our chunk patterns ?
dominik-pichler
commented
9 months ago also, the question is, wether chunked subjects (including their attributes in the nodes) should be used ? It would make things easier if I could just work with NP & VDBs, this will likely increase the number of nodes ...
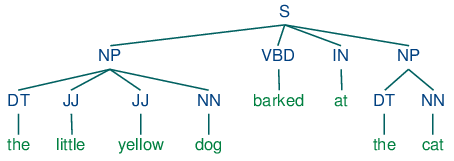
dominik-pichler
commented
9 months ago Quick train of thought: Is it not enough to extract the nouns and link them via sentences ?
The question is, if it is smarter to work with NP's or pure NNs? or, if I can maybe get both ? 🌊
dominik-pichler
commented
9 months ago or to have multiple graphs:
1) NP 2) NNs without attributes 3) NNs with attributes
dominik-pichler
commented
9 months ago Question: In the english language: Is the gramar structured in order? Meaning, give the following Wordtpyes: S1 - a1 - S2 - a2 - S3, could a1 also effect S3 or is it always only affecting S2.
Meaning, what are our chunk patterns ?
No, at least in german there are many examples that break this assumption, so I guess it is the same for english! "Slowly, eaten by the bear, the human starts to cry"
dominik-pichler
commented
9 months ago
Further Overview of LLM alternatives
dominik-pichler
commented
9 months ago For now, I'll stop once the Rule Bases Methods work
dominik-pichler
commented
9 months ago so there then will be two versions: 1) LLM based Meaning/Knowledge Extraction 2) RB Meaning/Knowledge extraction -> Nouns will be nodes, corresponding sentences will be edges
dominik-pichler
commented
9 months ago so the first version is working. It just needs some cleaning
Instead of spliting the nodes with a LLM, other possibilites (syntactic dissemblement etc.) should be investigated