 dotnet-eng-status[bot]
commented
1 year ago
dotnet-eng-status[bot]
commented
1 year ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
Closed dotnet-eng-status[bot] closed 11 months ago
dotnet-eng-status[bot]
commented
1 year ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
dotnet-eng-status[bot]
commented
1 year ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
dotnet-eng-status[bot]
commented
1 year ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
dotnet-eng-status[bot]
commented
1 year ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
 riarenas
commented
1 year ago
riarenas
commented
1 year ago This alert keeps flip flopping specifically for this queue. There are two on prem machines in there. What's the procedure here? I can't find any reference to this alert in our wiki. Is this something DDFUN should handle?
 garath
commented
1 year ago
garath
commented
1 year ago Hm, a percentage-based trigger on a queue that only has two machines is going to be noisy.
I think DDFUN could handle it but what would we ask them to do?
The value of this alert is tricky to me. It is a very coarse measurement (but the best we could do in the moment).
I wonder, is there a job running the entire duration of the alert? Or does the "low disk" condition span multiple jobs? If the former, which is what I expect, then we should try to make the alert smarter. If the later, then... I'll need to think some more.
 premun
commented
1 year ago
premun
commented
1 year ago Maybe it should be evaluating it for longer than 5m? I.e. a job can clean up and it would resolve before alerting?
garath
commented
1 year ago Maybe it should be evaluating it for longer than 5m? I.e. a job can clean up and it would resolve before alerting?
That seems like a good, easy improvement. Evaluate every five minutes for... 2 hours? Something like that.
dotnet-eng-status[bot]
commented
11 months ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
dotnet-eng-status[bot]
commented
11 months ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
dotnet-eng-status[bot]
commented
11 months ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
dotnet-eng-status[bot]
commented
11 months ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
dotnet-eng-status[bot]
commented
11 months ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
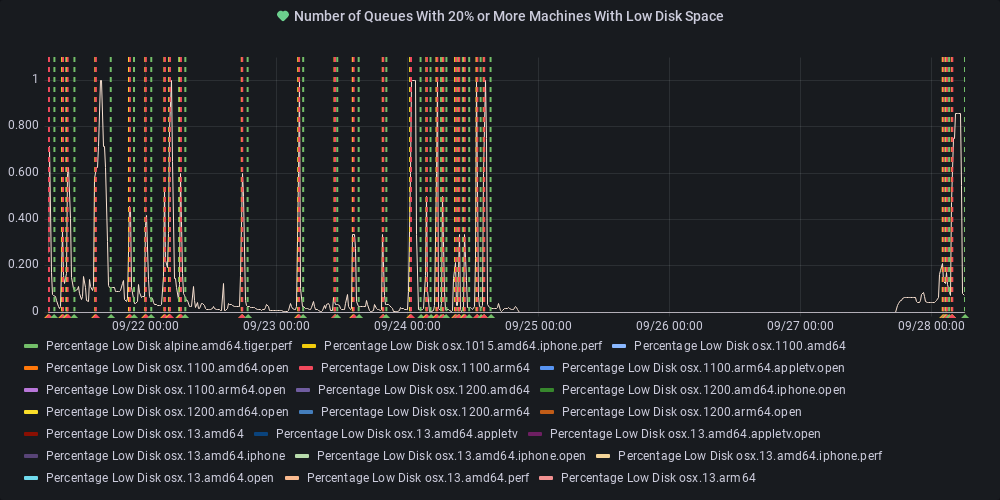
dotnet-eng-status[bot]
commented
11 months ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
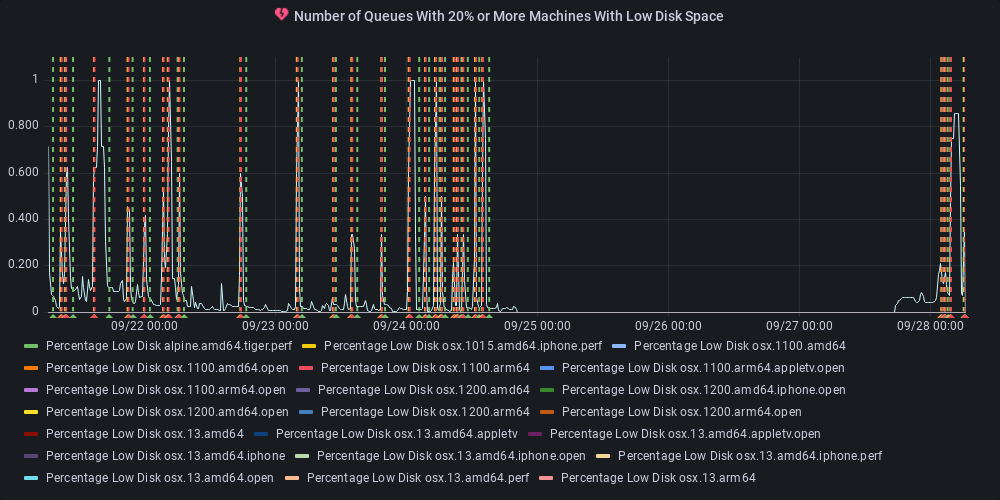
dotnet-eng-status[bot]
commented
11 months ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
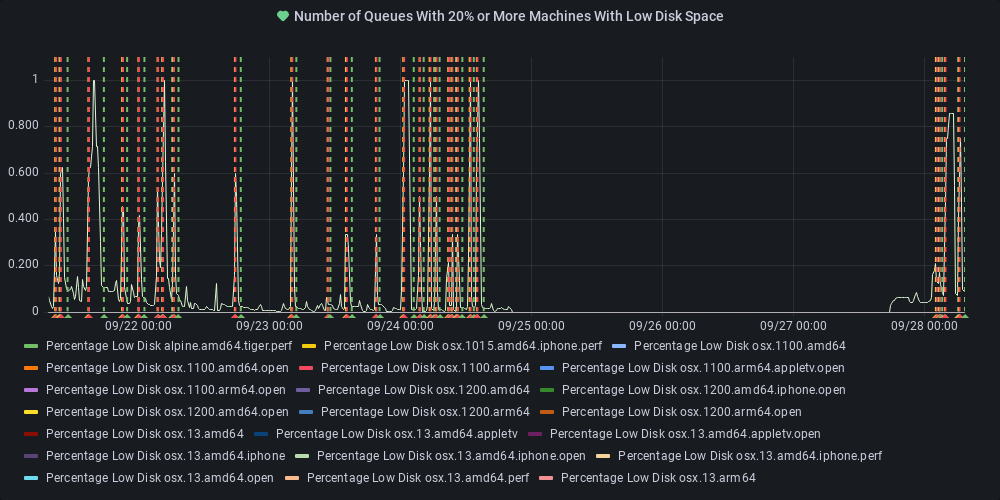
dotnet-eng-status[bot]
commented
11 months ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
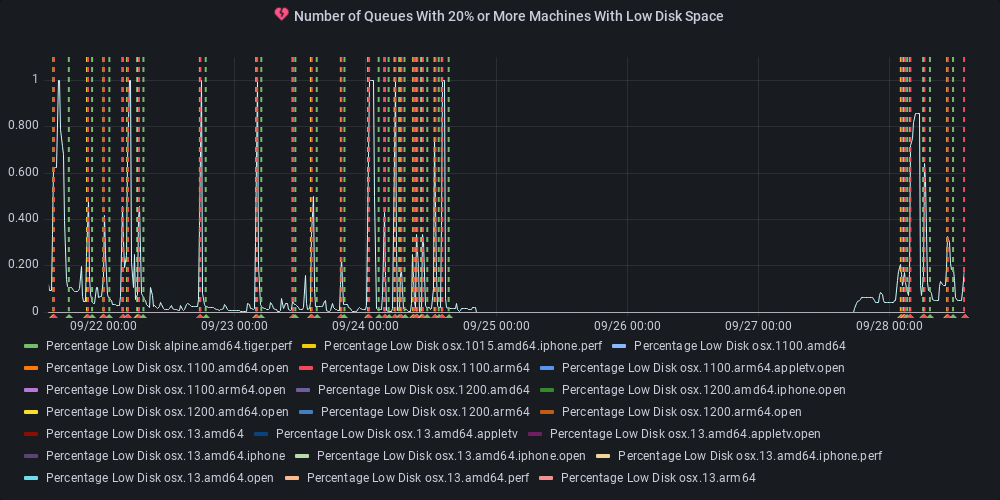
dotnet-eng-status[bot]
commented
11 months ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
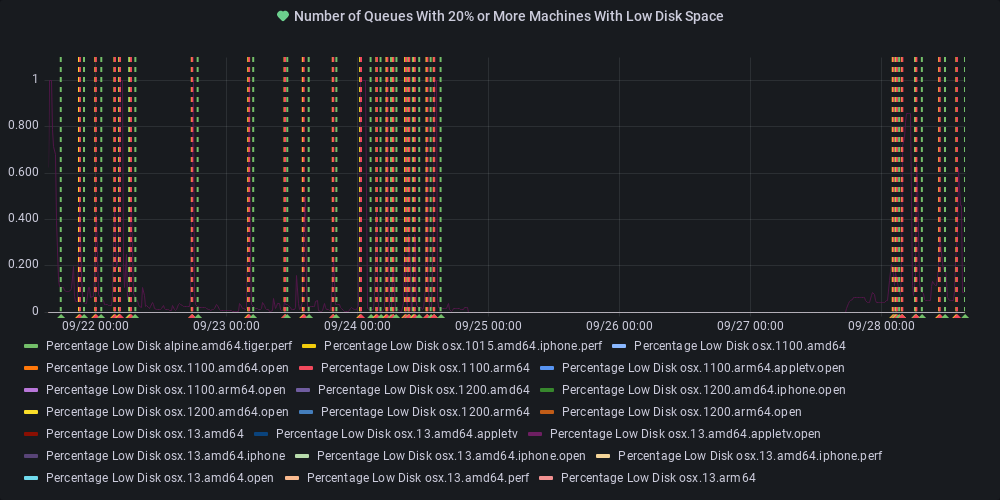
dotnet-eng-status[bot]
commented
11 months ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
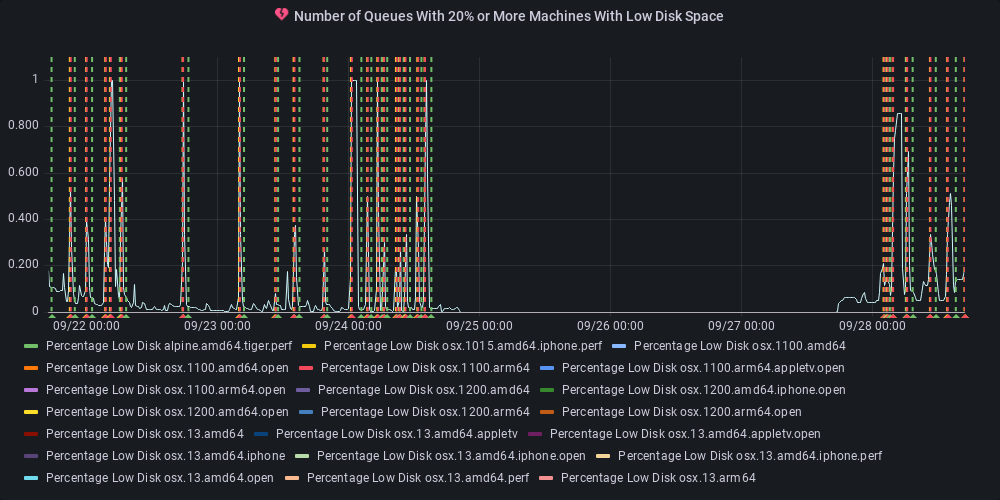
dotnet-eng-status[bot]
commented
11 months ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
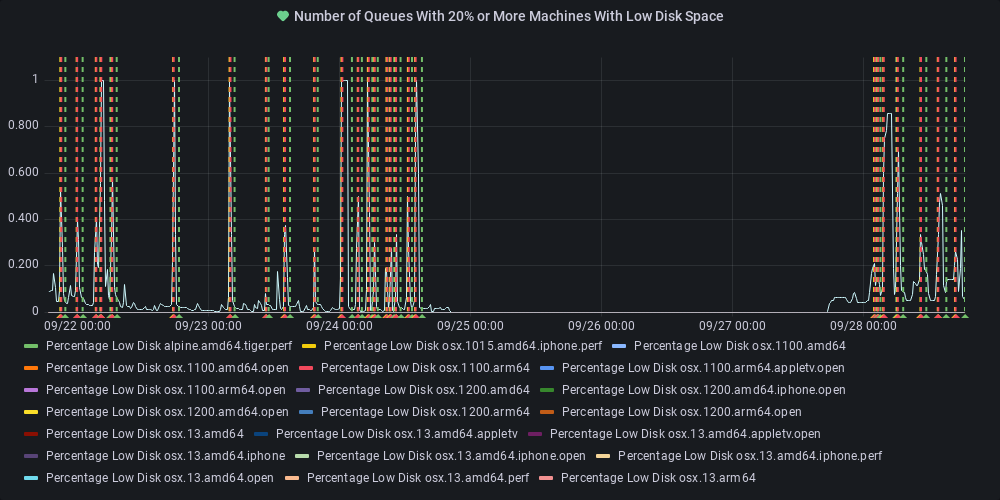
dotnet-eng-status[bot]
commented
11 months ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
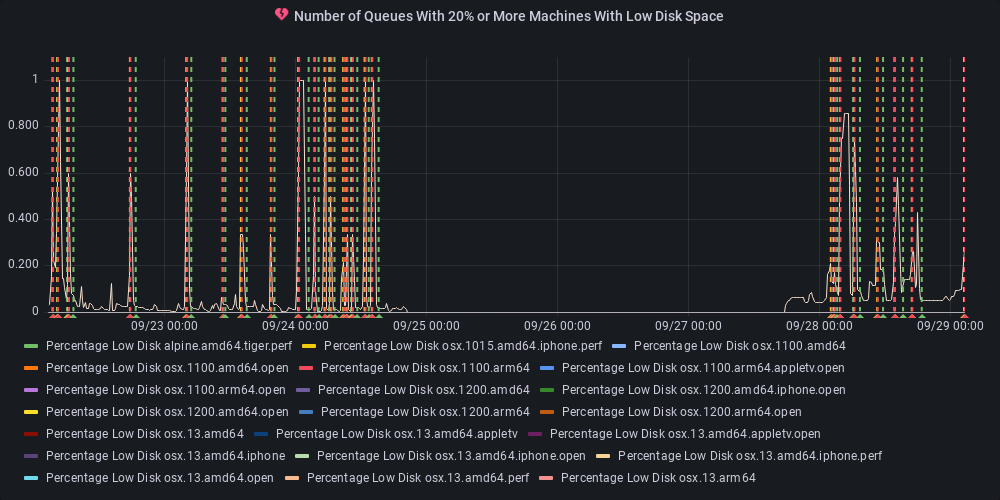
dotnet-eng-status[bot]
commented
11 months ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
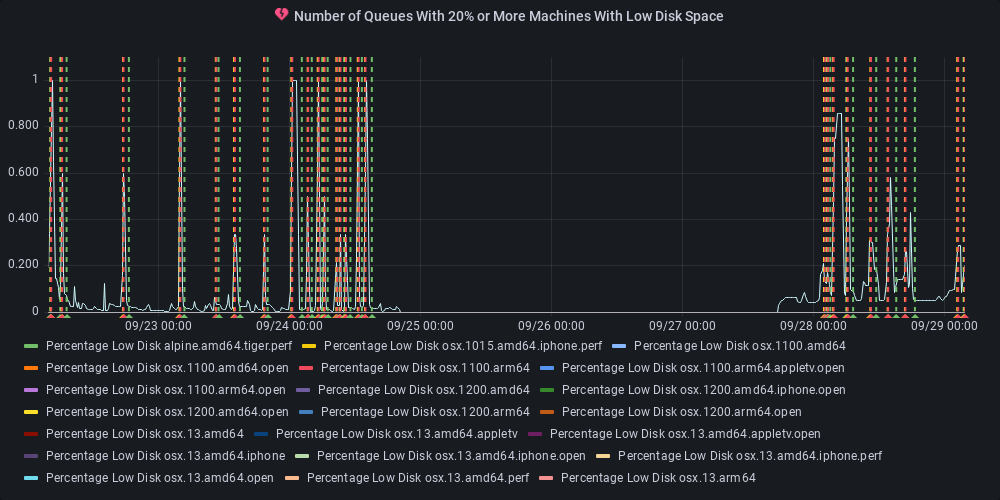
dotnet-eng-status[bot]
commented
11 months ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
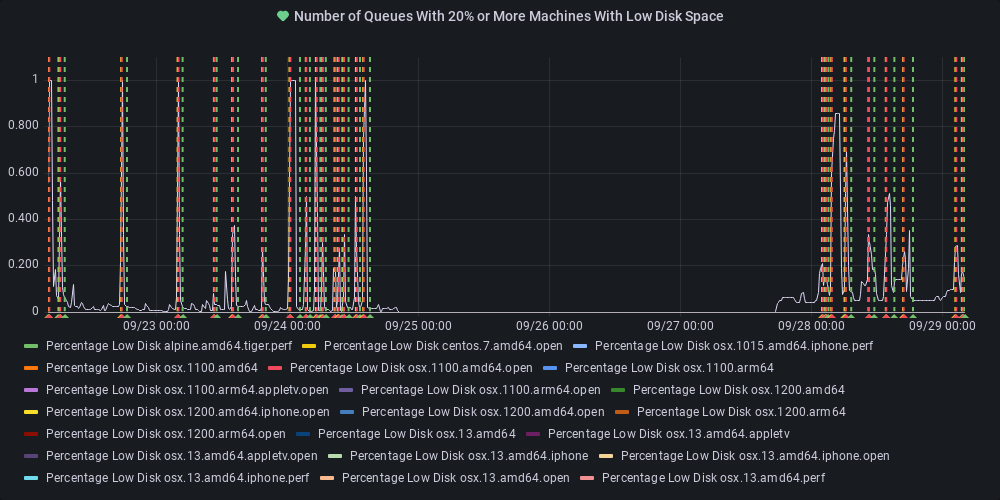
dotnet-eng-status[bot]
commented
11 months ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
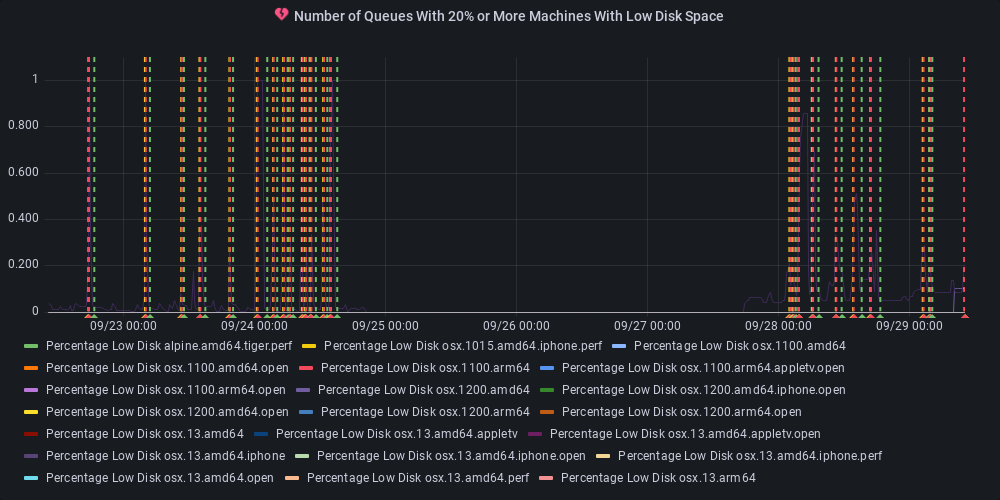
dotnet-eng-status[bot]
commented
11 months ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
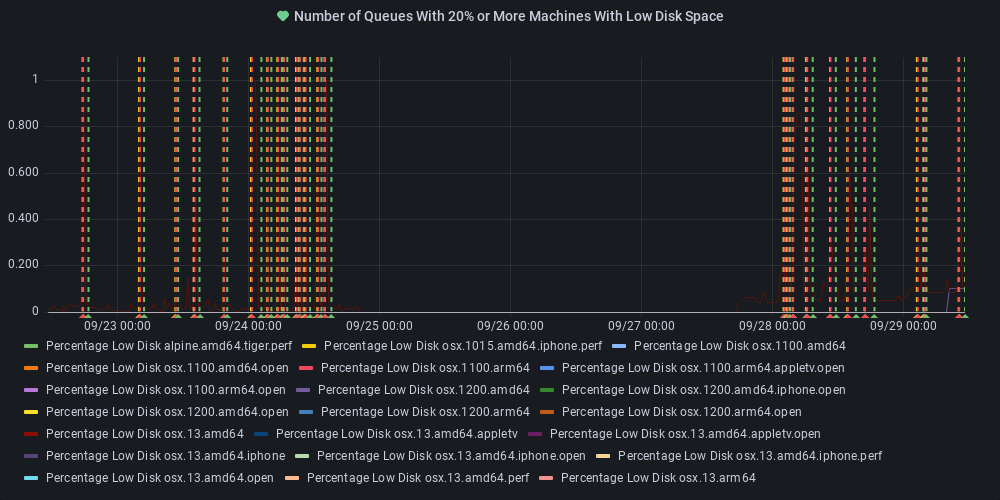
dotnet-eng-status[bot]
commented
11 months ago :broken_heart: Metric state changed to alerting
At least one queue has 20% or more of its agents reporting low disk space.
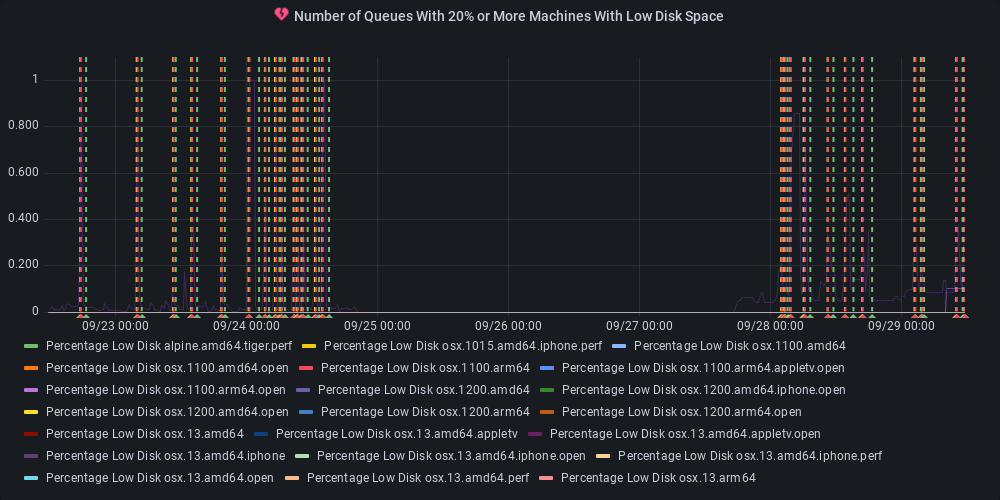
dotnet-eng-status[bot]
commented
11 months ago :green_heart: Metric state changed to ok
At least one queue has 20% or more of its agents reporting low disk space.
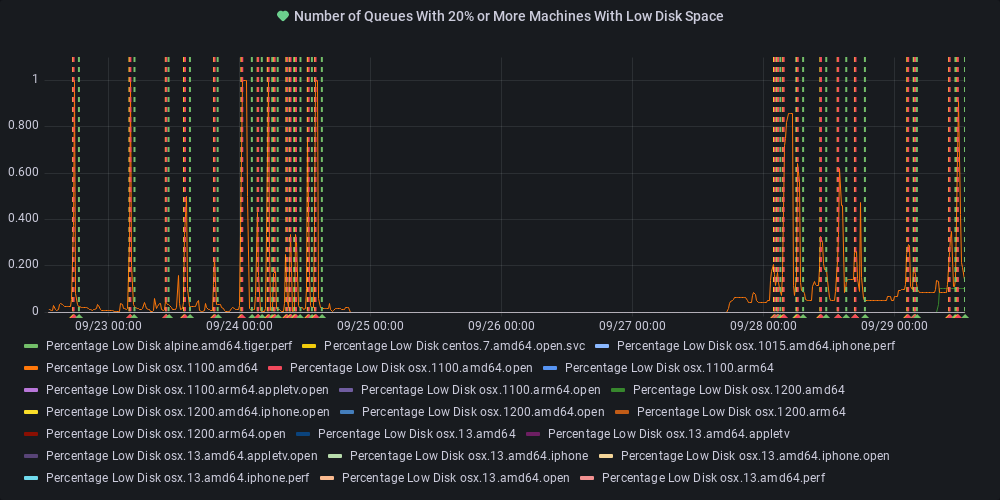
 ilyas1974
commented
11 months ago
ilyas1974
commented
11 months ago Closing this alert as the work to correct this is being down as part of https://github.com/dotnet/dnceng/issues/846
:broken_heart: Metric state changed to alerting
Go to rule
@dotnet/dnceng, please investigate
Automation information below, do not change
Grafana-Automated-Alert-Id-2ca5b0285c1e4179b621f916b8b5e75f