 tannergooding
commented
7 years ago
tannergooding
commented
7 years ago FYI. @mellinoe, @DrewScoggins
Closed tannergooding closed 4 years ago
tannergooding
commented
7 years ago FYI. @mellinoe, @DrewScoggins
 mellinoe
commented
7 years ago
mellinoe
commented
7 years ago Definitely a valuable goal, although the majority of the work here will be in improving the SIMD codegen, and potentially the codegen around the new MathF intrinsics.
tannergooding
commented
7 years ago So looking at Vector2 and Vector3, it seems the primary 'perf' issue with load/store is that we don't treat them as 16-byte structures.
This is good for keeping memory allocations small, but it is bad for perf (because we end up doing multiple read/writes instead of a single read/write).
For something simple like var result = VectorXValue we produce the following:
Vector2:
mov rax,1A0685B7918h
mov rax,qword ptr [rax]
vmovsd xmm0,qword ptr [rax+8]
vmovsd qword ptr [rbp+50h],xmm0 Vector3
mov rax,1A0685B7930h
mov rax,qword ptr [rax]
lea rax,[rax+8]
vmovss xmm0,dword ptr [rax+8]
vmovsd xmm1,qword ptr [rax]
vshufps xmm1,xmm1,xmm0,44h
vmovapd xmmword ptr [rbp+60h],xmm1Vector4
mov rax,1A0685B7948h
mov rax,qword ptr [rax]
vmovupd xmm0,xmmword ptr [rax+8]
vmovapd xmmword ptr [rbp+60h],xmm0 We would probably see a pretty big win here if we treat Vector3 and Vector4 as 16-byte structures. Most operations will end up touching the extra registers, but can trivaially be masked out of operations where it matters (such as equality checks).
For example, DirectXMath implements equality as follows (in all cases FXMVECTOR is __m128):
Vector2
inline bool XM_CALLCONV XMVector2Equal
(
FXMVECTOR V1,
FXMVECTOR V2
)
{
#if defined(_XM_NO_INTRINSICS_)
return (((V1.vector4_f32[0] == V2.vector4_f32[0]) && (V1.vector4_f32[1] == V2.vector4_f32[1])) != 0);
#elif defined(_XM_ARM_NEON_INTRINSICS_)
uint32x2_t vTemp = vceq_f32( vget_low_f32(V1), vget_low_f32(V2) );
return ( vget_lane_u64( vTemp, 0 ) == 0xFFFFFFFFFFFFFFFFU );
#elif defined(_XM_SSE_INTRINSICS_)
XMVECTOR vTemp = _mm_cmpeq_ps(V1,V2);
// z and w are don't care
return (((_mm_movemask_ps(vTemp)&3)==3) != 0);
#endif
}Vector3
inline bool XM_CALLCONV XMVector3Equal
(
FXMVECTOR V1,
FXMVECTOR V2
)
{
#if defined(_XM_NO_INTRINSICS_)
return (((V1.vector4_f32[0] == V2.vector4_f32[0]) && (V1.vector4_f32[1] == V2.vector4_f32[1]) && (V1.vector4_f32[2] == V2.vector4_f32[2])) != 0);
#elif defined(_XM_ARM_NEON_INTRINSICS_)
uint32x4_t vResult = vceqq_f32( V1, V2 );
int8x8x2_t vTemp = vzip_u8(vget_low_u8(vResult), vget_high_u8(vResult));
vTemp = vzip_u16(vTemp.val[0], vTemp.val[1]);
return ( (vget_lane_u32(vTemp.val[1], 1) & 0xFFFFFFU) == 0xFFFFFFU );
#elif defined(_XM_SSE_INTRINSICS_)
XMVECTOR vTemp = _mm_cmpeq_ps(V1,V2);
return (((_mm_movemask_ps(vTemp)&7)==7) != 0);
#endif
}Vector4
inline bool XM_CALLCONV XMVector4Equal
(
FXMVECTOR V1,
FXMVECTOR V2
)
{
#if defined(_XM_NO_INTRINSICS_)
return (((V1.vector4_f32[0] == V2.vector4_f32[0]) && (V1.vector4_f32[1] == V2.vector4_f32[1]) && (V1.vector4_f32[2] == V2.vector4_f32[2]) && (V1.vector4_f32[3] == V2.vector4_f32[3])) != 0);
#elif defined(_XM_ARM_NEON_INTRINSICS_)
uint32x4_t vResult = vceqq_f32( V1, V2 );
int8x8x2_t vTemp = vzip_u8(vget_low_u8(vResult), vget_high_u8(vResult));
vTemp = vzip_u16(vTemp.val[0], vTemp.val[1]);
return ( vget_lane_u32(vTemp.val[1], 1) == 0xFFFFFFFFU );
#elif defined(_XM_SSE_INTRINSICS_)
XMVECTOR vTemp = _mm_cmpeq_ps(V1,V2);
return ((_mm_movemask_ps(vTemp)==0x0f) != 0);
#else
return XMComparisonAllTrue(XMVector4EqualR(V1, V2));
#endif
}It also has a convention for two different types of load. An efficient one, that assumes the read is 16-bytes, and a slow read that assumes it is the size of the data structure (12-bytes for Vector3). Read 12-bytes as Vector3
//------------------------------------------------------------------------------
_Use_decl_annotations_
inline XMVECTOR XM_CALLCONV XMLoadFloat3
(
const XMFLOAT3* pSource
)
{
assert(pSource);
#if defined(_XM_NO_INTRINSICS_)
XMVECTOR V;
V.vector4_f32[0] = pSource->x;
V.vector4_f32[1] = pSource->y;
V.vector4_f32[2] = pSource->z;
V.vector4_f32[3] = 0.f;
return V;
#elif defined(_XM_ARM_NEON_INTRINSICS_)
float32x2_t x = vld1_f32( reinterpret_cast<const float*>(pSource) );
float32x2_t zero = vdup_n_f32(0);
float32x2_t y = vld1_lane_f32( reinterpret_cast<const float*>(pSource)+2, zero, 0 );
return vcombine_f32( x, y );
#elif defined(_XM_SSE_INTRINSICS_)
__m128 x = _mm_load_ss( &pSource->x );
__m128 y = _mm_load_ss( &pSource->y );
__m128 z = _mm_load_ss( &pSource->z );
__m128 xy = _mm_unpacklo_ps( x, y );
return _mm_movelh_ps( xy, z );
#endif
}Read 16-bytes as Vector3
//------------------------------------------------------------------------------
_Use_decl_annotations_
inline XMVECTOR XM_CALLCONV XMLoadFloat3A
(
const XMFLOAT3A* pSource
)
{
assert(pSource);
assert(((uintptr_t)pSource & 0xF) == 0);
#if defined(_XM_NO_INTRINSICS_)
XMVECTOR V;
V.vector4_f32[0] = pSource->x;
V.vector4_f32[1] = pSource->y;
V.vector4_f32[2] = pSource->z;
V.vector4_f32[3] = 0.f;
return V;
#elif defined(_XM_ARM_NEON_INTRINSICS_)
// Reads an extra float which is zero'd
float32x4_t V = vld1q_f32_ex( reinterpret_cast<const float*>(pSource), 128 );
return vsetq_lane_f32( 0, V, 3 );
#elif defined(_XM_SSE_INTRINSICS_)
// Reads an extra float which is zero'd
__m128 V = _mm_load_ps( &pSource->x );
return _mm_and_ps( V, g_XMMask3 );
#endif
}We are using movapd instead of movaps, which is not ideal. The Intel Architectures Optimization Manual (http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf) recommends:
When floating-point operations are bitwise equivalent, use PS data type instead of PD data type. MOVAPS and MOVAPD do the same thing, but MOVAPS takes one less byte to encode the instruction
There are a plethora of other optimization details recommended for fully utilizing the SIMD throughput (including recommendations for exactly how to do partial load/stores).
tannergooding
commented
7 years ago I think these are probably the core optimization rules for handling load/store of SIMD types:
Assembly/Compiler Coding Rule 43. (M impact, ML generality) Avoid introducing dependences with partial floating-point register writes, e.g. from the MOVSD XMMREG1, XMMREG2 instruction. Use the MOVAPD XMMREG1, XMMREG2 instruction instead. The MOVSD XMMREG, MEM instruction writes all 128 bits and breaks a dependence. The MOVUPD from memory instruction performs two 64-bit loads, but requires additional µops to adjust the address and combine the loads into a single register. This same functionality can be obtained using MOVSD XMMREG1, MEM; MOVSD XMMREG2, MEM+8; UNPCKLPD XMMREG1, XMMREG2, which uses fewer µops and can be packed into the trace cache more effectively. The latter alternative has been found to provide a several percent performance improvement in some cases. Its encoding requires more instruction bytes, but this is seldom an issue for the Pentium 4 processor. The store version of MOVUPD is complex and slow, so much so that the sequence with two MOVSD and a UNPCKHPD should always be used.
Assembly/Compiler Coding Rule 44. (ML impact, L generality) Instead of using MOVUPD XMMREG1, MEM for a unaligned 128-bit load, use MOVSD XMMREG1, MEM; MOVSD XMMREG2, MEM+8; UNPCKLPD XMMREG1, XMMREG2. If the additional register is not available, then use MOVSD XMMREG1, MEM; MOVHPD XMMREG1, MEM+8.
Assembly/Compiler Coding Rule 45. (M impact, ML generality) Instead of using MOVUPD MEM, XMMREG1 for a store, use MOVSD MEM, XMMREG1; UNPCKHPD XMMREG1, XMMREG1; MOVSD MEM+8, XMMREG1 instead.
Assembly/Compiler Coding Rule 46. (H impact, H generality) Align data on natural operand size address boundaries. If the data will be accessed with vector instruction loads and stores, align the data on 16-byte boundaries.
Assembly/Compiler Coding Rule 50. (H impact, ML generality) If it is necessary to extract a nonaligned portion of stored data, read out the smallest aligned portion that completely contains the data and shift/mask the data as necessary. This is better than incurring the penalties of a failed storeforward.
Assembly/Compiler Coding Rule 51. (MH impact, ML generality) Avoid several small loads after large stores to the same area of memory by using a single large read and register copies as needed.
Functions that use Streaming SIMD Extensions or Streaming SIMD Extensions 2 data need to provide a 16-byte aligned stack frame.
All branch targets should be 16-byte aligned.
 DrewScoggins
commented
7 years ago
DrewScoggins
commented
7 years ago Adding @dotnet/jit-contrib and @russellhadley
 BruceForstall
commented
7 years ago
BruceForstall
commented
7 years ago We can't write a Vector3 as 16 bytes because the struct is defines as only 12 bytes in size. If it is a member of a struct, we would overwrite what follows. We can't read past 12 bytes, either, if that might cross a page boundary.
For local variables, the JIT does read/write Vector3 as 16 bytes.
tannergooding
commented
7 years ago @BruceForstall, but there is no reason why Vector3 can't be internally implemented as a 16-byte structure so we receive the full perf benefits of doing so.
For something as simple as adding two vectors together, Vector3 is currently 1.3x slower on the perf test (and Vector2 is marginally slower from that as well).
If there is some legitimate concern that someone has taken a dependency on the fact that Vector3 is 12 bytes (and those concerns are great enough to outweigh the perf benefits here). Then, I would argue that we investigate other ways to mitigate this issue for users who do care about the performance here.
tannergooding
commented
7 years ago One such way to provide a perf increase would be to provide a set of extension methods on Vector4 that treat it as a Vector2 or Vector3. These instructions would still be backed by intrinsics, but would require the user to explicitly opt into the functionality (either by referencing an additional assembly or by importing some special namespace that includes these extension methods).
tannergooding
commented
7 years ago and by internally implemented, I mean that today it is implemented as follows:
public struct Vector3
{
public float X;
public float Y;
public float Z;
}Changing the structure to the following would allow us to load/store as 16-bytes and still only allow the user to access the W component.
public struct Vector3
{
public float X;
public float Y;
public float Z;
private float W;
}The only concern from this modification is that some user has hard-coded that the size of Vector3 is 12-bytes. However, I believe the overall perf-benefits of such a change would outweigh these concerns.
 sivarv
commented
7 years ago
sivarv
commented
7 years ago @tannergooding - The very initial implementation of Vector3 was a 16-byte struct. When we checked with a dev from Unity GameEngine and also with XNA graphics library folks, they have strongly indicated to us that for using Vector3 it has to be exactly of 12-bytes in length. The reason is that their libraries have a version of Vector3, that is used in interop and to facilitate adoption by these customers we had to make it 12-bytes struct. These customers do understand loss of performance being a 12-byte struct. If the customer is worried about performance he/she can use Vector4 as if it were a Vector3.
@mellinoe - can provide more historical context here.
Btw, Vector4 has a constructor that takes a Vector2 and two floats or a Vector3 and one additional float and constructs a Vector4. Those customers who are performance conscious can use these constructors and perform all operations as if it were a Vector4.
As @BruceForstall mentioned, JIT does consider it as a 16-byte struct if it is a local var allocated on stack. and provides some perf benefit in Vector3/Vector2 case.
mellinoe
commented
7 years ago Many applications of Vector3 require it to be an actual 12-byte struct (graphics programming mainly). It would essentially be unusable if it were 16-bytes in storage size. We can do optimization tricks where the difference is unobservable (and we already do some of those), but Vector3 does fundamentally need to be 12 bytes in length.
tannergooding
commented
7 years ago Many applications of Vector3 require it to be an actual 12-byte struct (graphics programming mainly).
I somewhat disagree with this statement. Native multimedia applications (including graphics programming) work completely fine with 16-byte structs (just look at the DirectXMath library, where all the functions operate on FXMVECTOR, which is 16-bytes).
As for existing managed frameworks (such as Unity and XNA) I would say that this is an implementation detail on their end, and was likely done to save space since their wasn't any intrinsic support to go off initially.
That being said, since we can't just modify the structs to make them 'better', then I think we need an alternative story.
For example, while Vector4 does have constructors that take a Vector2 and Vector3, these also require the user to pass in the "missing" components (they could be assumed to be 0 by default).
Vector4 also doesn't expose some Vector3 specific functions, such as Cross or have general function implementations that say "Do this function as if I were a Vector3" (in all cases, it uses all four fields, rather than ignoring any additional components -- DirectXMath, for example, does ignore any additional components in its checks).
. . .
Realistically, I think the most optimal solution would be to provide a VectorIntrinsic class that exposed raw intrinsics and allowed the user to write their own implementations. For example, C++ exposes __m128 _mm_add_ps(__m128, __m128), there is really no reason why we couldn't have PackedSingle VectorIntrinsic.AddPackedSingle(PackedSingle, PackedSingle) (or something to that effect).
Users could then implement math libraries to suit their own needs and their own types, even modifying their existing types to be more-performant without breaking back-compat.
 benaadams
commented
7 years ago
benaadams
commented
7 years ago Increasing in memory struct size (vs register) would cause issues with interop on packing with arrays of them.
 mikedn
commented
7 years ago
mikedn
commented
7 years ago but there is no reason why Vector3 can't be internally implemented as a 16-byte structure so we receive the full perf benefits of doing so.
Maybe I'm missing something but that's already the case. A Vector3 ends up in a SSE register and most operations are as if it was a Vector4 - you get addps, mulps and so on.
In terms of storage size, yes, it has 12 bytes and not 16. That results in rather inefficient load/stores and coupled with the lack of optimizations that can result in messy code. For example:
p.v1 = p.v2 / p.v3 + p.v2 * p.v3;generates
00007FFA6A630823 48 8D 50 18 lea rdx,[rax+18h]
00007FFA6A630827 C4 E1 7A 10 4A 08 vmovss xmm1,dword ptr [rdx+8]
00007FFA6A63082D C4 E1 7B 10 02 vmovsd xmm0,qword ptr [rdx]
00007FFA6A630832 C4 E1 78 C6 C1 44 vshufps xmm0,xmm0,xmm1,44h
00007FFA6A630838 48 8D 50 28 lea rdx,[rax+28h]
00007FFA6A63083C C4 E1 7A 10 52 08 vmovss xmm2,dword ptr [rdx+8]
00007FFA6A630842 C4 E1 7B 10 0A vmovsd xmm1,qword ptr [rdx]
00007FFA6A630847 C4 E1 70 C6 CA 44 vshufps xmm1,xmm1,xmm2,44h
00007FFA6A63084D C4 E1 78 59 C1 vmulps xmm0,xmm0,xmm1
00007FFA6A630852 48 8D 50 18 lea rdx,[rax+18h]
00007FFA6A630856 C4 E1 7A 10 52 08 vmovss xmm2,dword ptr [rdx+8]
00007FFA6A63085C C4 E1 7B 10 0A vmovsd xmm1,qword ptr [rdx]
00007FFA6A630861 C4 E1 70 C6 CA 44 vshufps xmm1,xmm1,xmm2,44h
00007FFA6A630867 48 8D 50 28 lea rdx,[rax+28h]
00007FFA6A63086B C4 E1 7A 10 5A 08 vmovss xmm3,dword ptr [rdx+8]
00007FFA6A630871 C4 E1 7B 10 12 vmovsd xmm2,qword ptr [rdx]
00007FFA6A630876 C4 E1 68 C6 D3 44 vshufps xmm2,xmm2,xmm3,44h
00007FFA6A63087C C4 E1 70 59 CA vmulps xmm1,xmm1,xmm2
00007FFA6A630881 C4 E1 78 58 C1 vaddps xmm0,xmm0,xmm1
00007FFA6A630886 48 8D 40 08 lea rax,[rax+8]
00007FFA6A63088A C4 E1 7B 11 00 vmovsd qword ptr [rax],xmm0
00007FFA6A63088F C4 E1 79 70 C8 02 vpshufd xmm1,xmm0,2
00007FFA6A630895 C4 E1 7A 11 48 08 vmovss dword ptr [rax+8],xmm1 mups and addps are lost in a sea of loads. Could be better if redundant loads are eliminated.
Anyway, I don't see why improving this requires turning the world upside down. What seems to be needed here is an efficient way to get a Vector3 out of a Vector4. For example:
private Vector4 v1, v2;
static void Main()
{
var p = new Program();
float d = Vector3.Dot(p.v1.XYZ, p.v2.XYZ);
}@benaadams, what interop code expects it to be 12 bytes?
The point I'm trying to make is that for both GPU and CPU, the register size of a Vector3 is 16-bytes. Because of this, both the CPU and GPU are optimized for loading and storing aligned, 16-byte chunks of memory.
The architecture design manuals specify that doing a single unaligned load/store is also preferred over doing multiple load/stores where possible, because of how much more efficient it is. (aligned 16-bytes > unaligned 16-bytes > anything 12-bytes).
Code that is optimized for speed, should never be using a 12-byte struct, it should be using a 16-byte struct and consuming an additional 4-bytes for each Vector3 they have.
Code that wants to have a balance should be consuming an additional (NumberOfVector3 * 12) % 16 bytes (that is, should be consuming no more than 12-additional bytes of memory, at the end of the array). That way it can do an aligned load, followed by 3 unaligned loads always, and do 12-byte stores when overwriting data is a concern (if it is not a concern, doing aligned store, followed by 3 unaligned stores is more efficient).
Regardless of all this, I did understand that some people may have taken a dependency on the fact that Vector3 is 12-bytes. Which is why I suggested we have an alternative that allows us to treat a Vector4 as if it was a Vector3.
People who care about performance (and not memory) will want a way to have a 16-byte Vector3 (that is, it is 16-byte registers and 16-bytes in memory). Maybe this is providing extension methods on Vector4 that cover this area or maybe it is providing Vector3 methods that take Vector4 as an input or maybe it is providing raw Vector intrinsic support so users can construct load/store and do math in the whichever way suits their code 😄.
@mikedn, that is exactly my point. Having it be 12-bytes in memory is extremely inefficient (especially if you have no way to tell the JIT it can do an unaligned load/store, because you know your data structure is configured to allow it).
mellinoe
commented
7 years ago what interop code expects it to be 12 bytes?
Like I said, graphics programming. It is extremely common to send massive amounts of Vector3's (think hundreds of thousands+) into GPU buffers in a very short amount of time. GPU memory and bandwidth is a limited resource, and there are very particular requirements around data size, format, and alignment when sending data to the GPU. The "physical shape" of these structures is very much a part of their public definition, and it is assumed to never change. So having every Vector3 be 25% larger isn't just an "incidental" change when doing an optimization; it's a fundamentally breaking change.
benaadams
commented
7 years ago what interop code expects it to be 12 bytes?
Serialization and deserialization of arrays of data from storage
Arrays of Structures in gpu format so a Vertex passed to gpu will be
struct Vertex
{
Vector3 Position;
Vector3 Normal;
Vector2 TextureCoords;
}Note this interleaved data
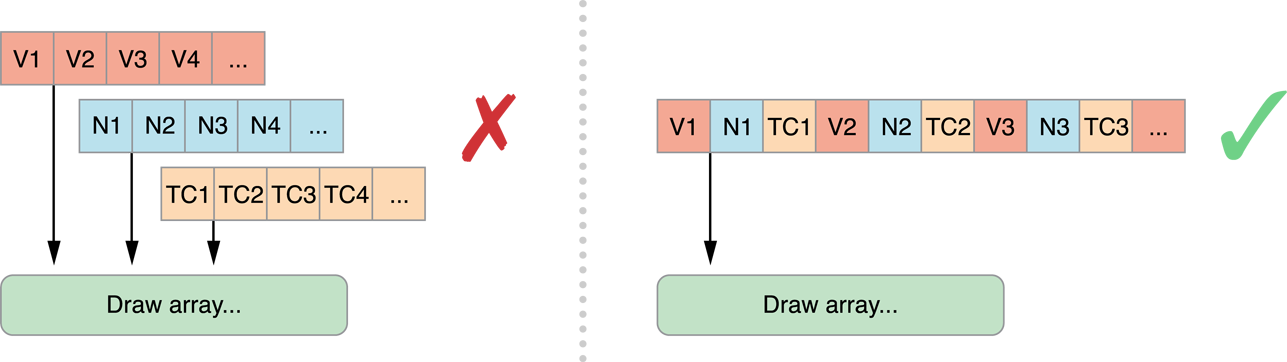
Is still 4 byte aligned in terms of the Vertex as misalginment on the struct will cause issues
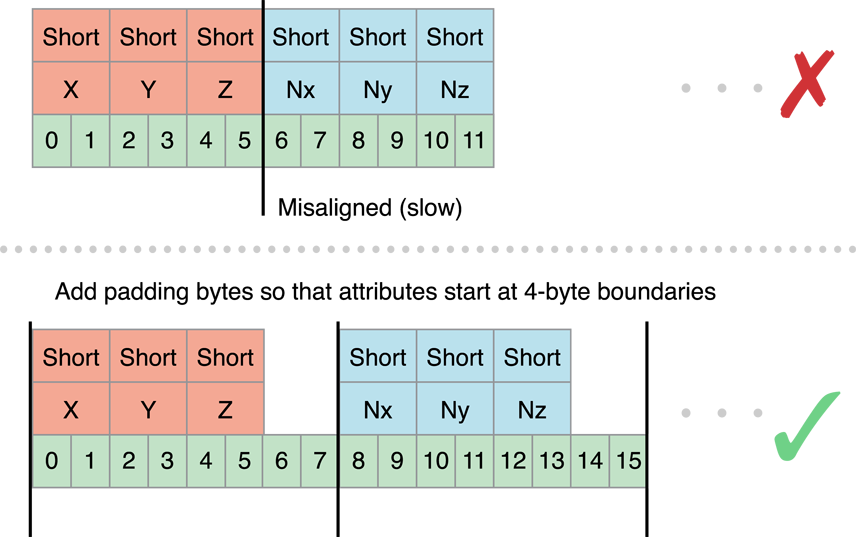
But changing it to
struct Vertex
{
Vector4 Position;
Vector4 Normal;
Vector4 TextureCoords;
}Increases the CPU->GPU bandwidth x1.5 and the bandwidth on GPU by the same; plus every GPU shader would need to change and there are a limited number of 4 float attributes to use; so throwing away values isn't good.
benaadams
commented
7 years ago As an aside; you might not manipulate these data structures on CPU (though you may do); but you'd probably expect them to work rather than having to write
struct Vertex
{
float posX;
float posY;
float posZ;
float normX;
float normY;
float normZ;
float U;
float V;
}But is just an example; bones etc you would likely be manipulating cpu side (though they may be an array of Vector4s)
tannergooding
commented
7 years ago @benaadams, yes. However, the loads performed here can always be 16-bytes where the 'extra' field is thrown away.
Take this sample C# code:
public static Vector3[] _vectors = new Vector3[2048];
static void Main(string[] args)
{
for (var index = 0; index < 2048; index++)
{
_vectors[index] *= 1.5f;
}
}which generates:
sub esp,20h
xor esi,esi
mov rcx,7FFC6FFC4E90h
mov edx,1
call 00007FFCCFBFD910
iteration:
mov rax,1C892C927D0h
mov rax,qword ptr [rax]
cmp esi,dword ptr [rax+8]
jae some_call
movsxd rdx,esi
lea rdx,[rdx+rdx*2]
lea rax,[rax+rdx*4+10h]
movss xmm1,dword ptr [rax+8]
movsd xmm0,qword ptr [rax]
shufps xmm0,xmm0,xmm1,44h
movss xmm1,dword ptr [7FFC70120918h]
shufps xmm1,xmm1,xmm1,40h
mulps xmm0,xmm0,xmm1
movsd qword ptr [rax],xmm0
pshufd xmm1,xmm0,2
movss dword ptr [rax+8],xmm1
inc esi
cmp esi,800h
jl iteration
add rsp,20h
pop rsi
ret
some_call:
call 00007FFCCFD3DA50
int 3 and the corresponding C++ code:
DirectX::XMFLOAT3 _vectors[2048];
int main()
{
for (auto index = 0; index < 2048; index++)
{
auto vector = DirectX::XMLoadFloat3(&_vectors[index]);
vector = DirectX::XMVectorScale(vector, 1.5f);
DirectX::XMStoreFloat3(&_vectors[index], vector);
}
return 0;
}which generates:
movaps xmm3,xmmword ptr [__xmm@3fc000003fc000003fc000003fc00000]
lea rax,[_vectors+8h]
mov ecx,800h
nop dword ptr [rax]
nop word ptr [rax+rax]
iteration:
movss xmm0,dword ptr [rax-4]
movss xmm2,dword ptr [rax-8]
lea rax,[rax+0Ch]
unpcklps xmm2,xmm0
movss xmm0,dword ptr [rax-0Ch]
movlhps xmm2,xmm0
mulps xmm2,xmm3
movss dword ptr [rax-14h],xmm2
movaps xmm0,xmm2
shufps xmm0,xmm2,55h
movss dword ptr [rax-10h],xmm0
shufps xmm2,xmm2,0AAh
movss dword ptr [rax-0Ch],xmm2
sub rcx,1
jne iteration
xor eax,eax
ret Now, I know that the total size of my array is a multiple of 16, so I'll fix my code (this isn't a very good example, since in this scenario we could just iterate over the entire buffer as if it were Vector4).
In C++, I'll modify my code to:
DirectX::XMFLOAT3 _vectors[2048];
int main()
{
for (auto index = 0; index < 2048; index++)
{
auto vector = DirectX::XMLoadFloat4(reinterpret_cast<DirectX::XMFLOAT4*>(&_vectors[index]));
vector = DirectX::XMVectorScale(vector, 1.5f);
DirectX::XMStoreFloat3(&_vectors[index], vector);
}
return 0;
}which generates:
movaps xmm2,xmmword ptr [__xmm@3fc000003fc000003fc000003fc00000]
lea rax,[_vectors]
mov ecx,800h
nop dword ptr [rax]
nop word ptr [rax+rax]
iteration:
movups xmm1,xmmword ptr [rax]
lea rax,[rax+0Ch]
mulps xmm1,xmm2
movss dword ptr [rax-0Ch],xmm1
movaps xmm0,xmm1
shufps xmm0,xmm1,55h
movss dword ptr [rax-8],xmm0
shufps xmm1,xmm1,0AAh
movss dword ptr [rax-4],xmm1
sub rcx,1
jne iteration
xor eax,eax
ret Doing the same in C# is currently impractical.
This is why things like the DirectXMath library have the following:
typedef __m128 XMVECTOR;
typedef const XMVECTOR FXMVECTOR;
struct XMFLOAT3
{
float x;
float y;
float z;
XMFLOAT3() XM_CTOR_DEFAULT
XM_CONSTEXPR XMFLOAT3(float _x, float _y, float _z) : x(_x), y(_y), z(_z) {}
explicit XMFLOAT3(_In_reads_(3) const float *pArray) : x(pArray[0]), y(pArray[1]), z(pArray[2]) {}
XMFLOAT3& operator= (const XMFLOAT3& Float3) { x = Float3.x; y = Float3.y; z = Float3.z; return *this; }
};
__declspec(align(16)) struct XMFLOAT3A : public XMFLOAT3
{
XMFLOAT3A() XM_CTOR_DEFAULT
XM_CONSTEXPR XMFLOAT3A(float _x, float _y, float _z) : XMFLOAT3(_x, _y, _z) {}
explicit XMFLOAT3A(_In_reads_(3) const float *pArray) : XMFLOAT3(pArray) {}
XMFLOAT3A& operator= (const XMFLOAT3A& Float3) { x = Float3.x; y = Float3.y; z = Float3.z; return *this; }
};
XMVECTOR XM_CALLCONV XMLoadFloat3(_In_ const XMFLOAT3* pSource);
XMVECTOR XM_CALLCONV XMLoadFloat3A(_In_ const XMFLOAT3A* pSource);
void XM_CALLCONV XMStoreFloat3(_Out_ XMFLOAT3* pDestination, _In_ FXMVECTOR V);
void XM_CALLCONV XMStoreFloat3A(_Out_ XMFLOAT3A* pDestination, _In_ FXMVECTOR V);
bool XM_CALLCONV XMVector3Equal(FXMVECTOR V1, FXMVECTOR V2);
XMVECTOR XM_CALLCONV XMVector3Dot(FXMVECTOR V1, FXMVECTOR V2);
XMVECTOR XM_CALLCONV XMVector3Cross(FXMVECTOR V1, FXMVECTOR V2);That is, they have a concept of 12-bytes in memory and 16-bytes in memory. But the data you operate on and pass around on the stack is always 16-bytes. The current CoreCLR implementation is roughly similar, except it is implicit knowledge that, once in register, it is in is 16-bytes bytes, there is no concept of a 16-byte Vector3, and there is no way to explicitly load/store a Vector3 to/from a 16-byte address.
On a side note, here is another example of really bad code-gen related to passing Vectors around:
For C#:
public static Vector3[] _vectors = new Vector3[2048];
static void Main(string[] args)
{
Func<Vector3, Vector3> sqrt = Sqrt;
for (var index = 0; index < 2048; index++)
{
_vectors[index] = sqrt(_vectors[index]);
}
}
public static Vector3 Sqrt(Vector3 value)
{
return Vector3.SquareRoot(value);
}Generates:
SquareRoot:
vmovss xmm1,dword ptr [rdx+8]
vmovsd xmm0,qword ptr [rdx]
vshufps xmm0,xmm0,xmm1,44h
vsqrtps xmm0,xmm0
vmovsd qword ptr [rcx],xmm0
vpshufd xmm1,xmm0,2
vmovss dword ptr [rcx+8],xmm1
mov rax,rcx
ret
Main:
push rbp
push rbx
sub rsp,48h
mov rcx,7FFC6FFB7220h
call 00007FFCCFBFD2C0
mov rsi,rax
lea rcx,[rsi+8]
mov rdx,rsi
call 00007FFCCFBFB5B0
mov rcx,21D59A538F0h
mov qword ptr [rsi+18h],rcx
mov rcx,7FFC70110080h
mov qword ptr [rsi+20h],rcx
xor edi,edi
mov rcx,7FFC6FFB4E90h
mov edx,1
call 00007FFCCFBFD910
iteration:
mov r8,21D69A627D0h
mov rbx,qword ptr [r8]
lea rdx,[rsp+30h]
mov r8,qword ptr [r8]
cmp edi,dword ptr [r8+8]
jae some_call
movsxd rcx,edi
lea rbp,[rcx+rcx*2]
lea r8,[r8+rbp*4+10h]
vmovss xmm1,dword ptr [r8+8]
vmovsd xmm0,qword ptr [r8]
vshufps xmm0,xmm0,xmm1,44h
vmovupd xmmword ptr [rsp+20h],xmm0
lea r8,[rsp+20h]
mov rax,rsi
mov rcx,qword ptr [rax+8]
call qword ptr [rax+18h] (SquareRoot)
vmovupd xmm0,xmmword ptr [rsp+30h]
cmp edi,dword ptr [rbx+8]
jae 00007FFC7011096B
lea rax,[rbx+rbp*4+10h]
vmovsd qword ptr [rax],xmm0
vpshufd xmm1,xmm0,2
vmovss dword ptr [rax+8],xmm1
inc edi
cmp edi,800h
jl iteration
add rsp,48h
pop rbx
pop rbp
pop rsi
pop rdi
ret
some_call:
call 00007FFCCFD3DA50
int 3 Where-as in C++:
DirectX::XMVECTOR SquareRoot(DirectX::FXMVECTOR value)
{
return DirectX::XMVectorSqrt(value);
}
int main()
{
DirectX::XMVECTOR(*sqrt)(DirectX::FXMVECTOR) = &SquareRoot;
for (auto index = 0; index < 2048; index++)
{
auto vector = DirectX::XMLoadFloat3(&_vectors[index]);
vector = sqrt(vector);
DirectX::XMStoreFloat3(&_vectors[index], vector);
}
return 0;
}Generates:
SquareRoot:
sqrtps xmm0,xmmword ptr [rcx]
ret
Main:
mov qword ptr [rsp+8],rbx
push rdi
sub rsp,30h
lea rbx,[_vectors+8h]
mov edi,800h
nop word ptr [rax+rax]
iteration:
movss xmm2,dword ptr [rbx-8]
lea rcx,[rsp+20h]
movss xmm0,dword ptr [rbx-4]
unpcklps xmm2,xmm0
movss xmm0,dword ptr [rbx]
movlhps xmm2,xmm0
movaps xmmword ptr [rsp+20h],xmm2
call SquareRoot
movss dword ptr [rbx-8],xmm0
movaps xmm1,xmm0
shufps xmm1,xmm0,55h
movss dword ptr [rbx-4],xmm1
lea rbx,[rbx+0Ch]
shufps xmm0,xmm0,0AAh
movss dword ptr [rbx-0Ch],xmm0
sub rdi,1
jne iteration
xor eax,eax
mov rbx,qword ptr [rsp+40h]
add rsp,30h
pop rdi
retOn a side note, here is another example of really bad code-gen related to passing Vectors around:
That has more to do with the calling convention rather than Vector3 being 12 bytes in size. Things aren't great in the case of Vector4 either because it is passed via memory instead of being passed in a register. Ideally the JIT should support the vectorcall convention and all vector types should be passed via registers.
Of course, if a function has a lot of parameters you can't pass all of them via registers, some will have to go trough memory. In that case it would make sense to always pass 16 byte quantities. The actual size of Vector3 - 12 bytes - is relevant only for type fields, array elements and PInvoke scenarios.
benaadams
commented
7 years ago @tannergooding that's why I specified the difference of memory vs register
Increasing in memory struct size (vs register)
i.e. register can be 16 bytes and operate on 16 bytes; its only when its loaded or written back to RAM (array or member variable) it needs to respect 12 bytes; and other things like SizeOf<T>/Marshal
tannergooding
commented
7 years ago @benaadams, so it sounds like we are roughly saying the same thing, and I'm (as usual) just bad at expressing things via text 😄
tannergooding
commented
7 years ago @benaadams, @mikedn, @mellinoe I think from the discussion so far, the following points can be made:
__vectorcall calling convention would be a win
__fastcall (the default for x64) and would allow SIMD types to be passed via register, rather than on stack
System.Runtime.InteropServices.CallingConventionLet me know if this sounds about right.
mikedn
commented
7 years ago @tannergooding One small observation:
NOTE: This is only for singular values, structs containing vectors and arrays of vectors would still be passed as normal
AFAIR vectorcall allows structs to be passed via registers - e.g. a struct containing 3 float/double/__mm128 members can be passed via 3 xmm registers. It would probably make sense for a struct containing 3 Vector3 members to also be passed via 3 xmm registers, one for each Vector3.
tannergooding
commented
7 years ago @mikedn, you are correct. Certain structs count as HVA (homogeneous vector aggregate) values.
An HVA type is a composite type of up to four data members that have identical vector types. An HVA type has the same alignment requirement as the vector type of its members.
tannergooding
commented
7 years ago Easier with https://github.com/dotnet/designs/issues/13
 fiigii
commented
7 years ago
fiigii
commented
7 years ago Intel hardware intrinsic API proposal has been opened at dotnet/corefx#22940
 tlgkccampbell
commented
7 years ago
tlgkccampbell
commented
7 years ago It is probably worth pointing out that as of Mono 5, all of the System.Numerics.Vector types are treated as being 16 bytes in size on that runtime. I have raised this discrepancy with multiple people at Xamarin, but they seem to consider it a non-issue.
As someone doing cross-platform graphics programming, this inconsistency makes SNV effectively unusable for my purposes, so it would be really nice for both teams to get on the same page--whichever page that is!
mellinoe
commented
7 years ago @tlgkccampbell That sounds pretty unfortunate, could you give more detail about what is handled incorrectly? As described above, the structural shape of the types is very important.
@akoeplinger Are you familiar with who knows the most about mono's System.Numerics.Vectors support?
tlgkccampbell
commented
7 years ago @mellinoe I filed a bug report with Xamarin back in May which goes into more detail and provides replication steps: https://bugzilla.xamarin.com/show_bug.cgi?id=56602
Note that while I originally believed this to only be a problem on Xamarin's mobile runtimes, I discovered later that this behavior changed from Mono 4 to Mono 5 and is also present on the desktop.
 akoeplinger
commented
7 years ago
akoeplinger
commented
7 years ago @akoeplinger Are you familiar with who knows the most about mono's System.Numerics.Vectors support?
That'd be @vargaz or @kumpera
tlgkccampbell
commented
6 years ago @mellinoe
Xamarin resolved my bug last night with the following message:
You're depending on internal implementation details of how the runtime lays out fields and how framework types are defined.
This is not something worth fixing. If you need strict control over memory layout, define the types themselves and convert to System.Numerics.Vectors on load.
Further API discussion on whether this should be part of the contract are to be conducted on corefx github repo and not on a bug report here since this involves the wide dotnet ecosystem.
So it appears that any further discussions will need to happen here.
tannergooding
commented
6 years ago Closing, as this is better tracked by dotnet/runtime#956
The
System.Numerics.Vectortypes are currently implemented as intrinsics in the CoreCLR. However, the perf in some cases is not ideal (especially around load/store for Vector3 and Vector2).These scenarios should be investigated and improved. I believe that targeting comparable performance to the DirectXMath implementation is a reasonable goal here (it is also implemented entirely in intrinsics, but in C/C++).