 mellinoe
commented
9 years ago
mellinoe
commented
9 years ago Could you use something like, for example, Marshal.AllocHGlobal? Or do you need an actual array object?
Closed ayende closed 1 year ago
mellinoe
commented
9 years ago Could you use something like, for example, Marshal.AllocHGlobal? Or do you need an actual array object?
 ayende
commented
9 years ago
ayende
commented
9 years ago That will give me a byte*, but i need byte[].
Also, this isn't limited to just byte arrays. OverlappedData is another thing that is commonly pinned and cause fragmentation.
ayende
commented
9 years ago So does any struct that we pass to async native code
 OtherCrashOverride
commented
9 years ago
OtherCrashOverride
commented
9 years ago In our scenario, we do a lot of I/O work. The problem with I/O is that it requires pinning the memory.
Working with a GPU, the same issue is encountered with I/O from a few bytes ranging to gigabytes. The solution has always been to pin the memory, use it, un-pin. You can store the GCHandle at a member level to share it across multi-threaded instances. It also has a flag that you can check to see if you need to pin it or if its already pinned.
https://msdn.microsoft.com/en-us/library/system.runtime.interopservices.gchandle%28v=vs.90%29.aspx Marshal.GCHandle
ayende
commented
9 years ago Sure, that is what we are effectively doing. The problem is that while the object is pinned, it will fragment the memory very badly.
I would like to be able to say: "Put those in a special place". Slab allocator pattern would be great.
OtherCrashOverride
commented
9 years ago The point I was trying to illustrate is that the pin is held for very little time. In my case its held for the duration of time it takes a DMA to complete. You can pin and release quite liberally without impacting performance. If your pinned memory is idle, it doesn't need to be pinned. You can release it and re-pin it when you actually need to work on it. This give the GC ample opportunities to relocate the object. If you have one giant block of memory pinned, consider breaking it up into smaller blocks to work on so that you have finer grained control over pinning and releasing.
ayende
commented
9 years ago You cannot do that when using I/O.
Example, socket.ReceiveAsync() this is going to be a pending operation (with pinned I/O) until the user send some data to us. This can be 15 seconds, or it can be a few hours, depending on the scenario.
Hibernating Rhinos Ltd
Oren Eini* l CEO l *Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
On Wed, Jul 15, 2015 at 2:25 PM, OtherCrashOverride < notifications@github.com> wrote:
The point I was trying to illustrate is that the pin is held for very little time. In my case its held for the duration of time it takes a DMA to complete. You can pin and release quite liberally without impacting performance. If your pinned memory is idle, it doesn't need to be pinned. You can release it and re-pin it when you actually need to work on it. This give the GC ample opportunities to relocate the object. If you have one giant block of memory pinned, consider breaking it up into smaller blocks to work on so that you have finer grained control over pinning and releasing.
— Reply to this email directly or view it on GitHub https://github.com/dotnet/coreclr/issues/1236#issuecomment-121586130.
 Maoni0
commented
9 years ago
Maoni0
commented
9 years ago Just because the buffers themselves don't move doesn't mean they can't be in higher generation. Where generations start is decided by the GC, regardless of whether objects are moving or not.
If there's fragmentation due to pinning, we want to keep it in gen0 as much as possible (unless it's deemed to be unproductive by our other tuning aspects) - that's by design. It's much better than having fragmentation in higher gen because we can use the fragmentation for your allocations right away.
Usually what happens is you have high fragmentation in gen0 right after a GC is finished, then we will use the gen0 fragmentation for allocations. On entry of the next GC, you will not see high fragmentation because it's used for useful data. Then when GC is done, if those objects died, you would see fragmentation again. When you say "fragmentation in gen0", we also need to know when you are taking this measurement. If it's only at the end of a GC, that's not a bad situation at all - for scenarios that pin heavily it's actually a great situation.
ayende
commented
9 years ago @Maoni0 The actual problem we are seeing is that we have a very high memory usage. And it cannot go down. Imagine a Gen0 heap that is using several GB, and there are a few pinned objects at the end.
Now, that isn't actually wasted space, sure, but from a user view point, that is a big problem. "Okay, you had a lot of work to do so used a lot of memory, but why are you keeping that memory still".
Our problems is that the memory usage do not go down, ever.
Maoni0
commented
9 years ago In order for me to get an idea of what's going on, it's best to send me some perf data if that's doable for you. You can download perfview from Microsoft.com (just search for it) and capture a trace of the GC ETW events:
perfview /GCCollectOnly /nogui /NoV2Rundown /NoNGENRundown /merge:true /zip:true /MaxCollectSec:1800 collect
this collects for 1800 seconds and only GC events. It's low overhead so if 1800s isn't long enough to show the symptom you can make it longer.
 redknightlois
commented
9 years ago
redknightlois
commented
9 years ago @Maoni0 just out of curiosity, in your blog post you said:
and heap allocations can also be more expensive when we use the freelist in gen0, but since we only go to the GC for memory every few kbytes, the effect of using the freelist shouldn’t be too bad
How would the GC behave performance wise in a situation like this one:
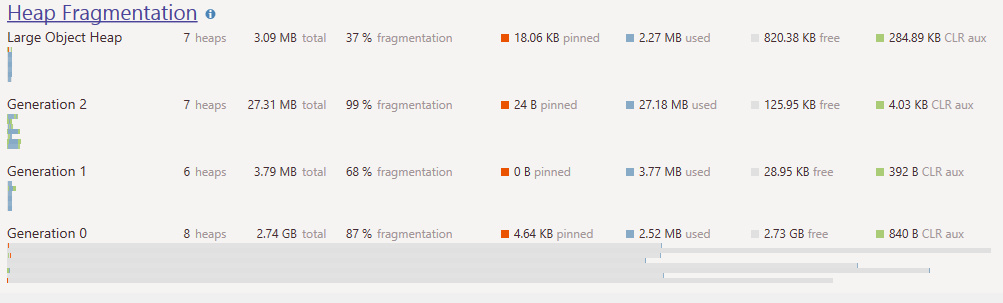
Where Gen0 looks like this:
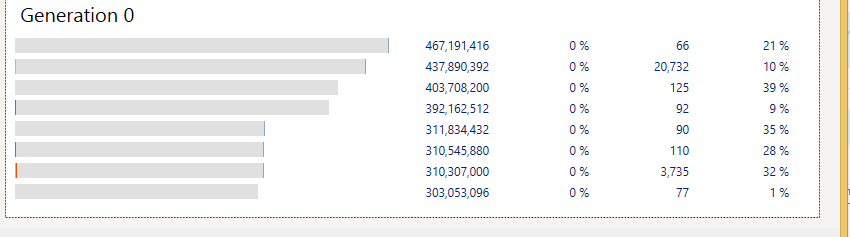
Where you can also see the pinned memory scattered all over the place.
Maoni0
commented
9 years ago Actually I don't see where it indicates "the pinned memory scattered all over the place" in gen0. I haven't seen this tool before. All I see is gray bars with a tiny bit of different colors at the beginning and the end in your 2nd picture. If you can explain in text it would be helpful.
redknightlois
commented
9 years ago That's the state after fragmentation kicks in.
The grey bars is free memory in Gen0 whose total amount is 2.73GB, the faint blue bars are the 2.52MB actually used and the faint orange is the pinned memory (4.64Kb total). If you could be able to zoom on it, you will see that each 300MB+ Gen0 heaps have 1 to 2 small fragments of sub 1Kb pinned memory. Since those pinned Kbs usually live in user time ( very long lived connections ) they prevent empty heaps to be reclaimed.
So I was curious about how the GC would behave (performance wise) in that case, where it has lots of memory already reserved but not in front of the heap.
Maoni0
commented
9 years ago My first post in this issue describes how GC behaves in this situation. If you see fragmentation in gen0 used for allocations, it's exactly by design and is great perf wise (you want the fragmentation to be at the end of the segment, not in front). If you see fragmentation all the time in gen0, which means at some point the pins scattered enough and simply are preventing GC from retracting on the segment, user action is required to make pins not scatter.
 masonwheeler
commented
9 years ago
masonwheeler
commented
9 years ago @Maoni0 I think Ayende's point is that it doesn't matter how "great perf wise" it is if you end up not being able to collect anything and then you hit out-of-memory errors. If that's "by design" then the design is buggy and needs to be fixed.
redknightlois
commented
9 years ago @masonwheeler I may be wrong but there is nothing you can do from the GC point of view. I understand the point of @Maoni0 about the "by design" behavior because it's probable that there is no sane GC design that could accomodate a requirement that allows moving pinned memory around. Nonetheless I side with @ayende in what's missing is a way to help the GC to make the right choice from the start. Call it a "hint" in the right direction in the same way that sometimes we have to hint the JIT in the right direction with specific code pattern to achieve the desired result. That level of flexibility today does not exist, and there is certainly a niche where it is needed (even MS own APIs could use it).
 janvorli
commented
9 years ago
janvorli
commented
9 years ago @Maoni0, aren't we actually unmapping free memory segments in the gen0 space? What I really mean is if we do that, then the memory consumption that's being discussed here is just virtual memory consumption and so that's not a problem at all.
Maoni0
commented
9 years ago @janvorli we don't actually decommit but we kick the pages out of the process' working set (we used to do a MEM_RESET which unfortunately doesn't come in effect till you are really really low on memory). Actually decommitting would require us to recommit these free spaces which has its own downside for perf.
If the pinned buffers stay around that long, ie, so long that your later workload simply can't get to use the fragmentation in gen0, it's likely you could've pooled them to prevent them from scattering all over the heap. This is what we did for a few network libraries and we cut down the heap size by a large percentage by simply using a buffer pool.
 kangaroo
commented
9 years ago
kangaroo
commented
9 years ago NOTE: MEM_RESET does nothing in the PAL. We should probably plumb that to madvise() if I properly understand what it does.
ayende
commented
9 years ago Our problem is that the Gen0 pools are big, and will not go down in size. That has impact on us when needing to do large allocations (the LOH cannot use the Gen0 free memory) and it has a big impact on the perception of the application.
Basically, memory usage can go up, but it doesn't go down.
Hibernating Rhinos Ltd
Oren Eini* l CEO l *Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
On Fri, Jul 17, 2015 at 11:30 PM, Maoni Stephens notifications@github.com wrote:
@janvorli https://github.com/janvorli we don't actually decommit but we kick the pages out of the process' working set (we used to do a MEM_RESET which unfortunately doesn't come in effect till you are really really low on memory). Actually decommitting would require us to recommit these free spaces which has its own downside for perf.
If the pinned buffers stay around that long, ie, so long that your later workload simply can't get to use the fragmentation in gen0, it's likely you could've pooled them to prevent them from scattering all over the heap. This is what we did for a few network libraries and we cut down the heap size by a large percentage by simply using a buffer pool.
— Reply to this email directly or view it on GitHub https://github.com/dotnet/coreclr/issues/1236#issuecomment-122404092.
 jkotas
commented
9 years ago
jkotas
commented
9 years ago From https://github.com/dotnet/coreclr/issues/1235#issuecomment-123169425
https://github.com/dotnet/coreclr/blob/master/src/mscorlib/Common/PinnableBufferCache.cs is a helper designed to deal with the buffer pinning problem. It has methods to explicitly allocate and free buffers. Internally, it manages free buffers in a GC friendly way to avoid problems with pinned buffers.
 benaadams
commented
9 years ago
benaadams
commented
9 years ago Allocate buffers, larger than 85k to push them into LoH, slice with ArraySegment or similar
ayende
commented
9 years ago Ben, That would work, and we are doing it. The problem is that some API, in particular, WebSockets previous to 4.5.2 will only accept ArraySegment with a Start = 0.
Hibernating Rhinos Ltd
Oren Eini* l CEO l *Mobile: + 972-52-548-6969
Office: +972-4-622-7811 l Fax: +972-153-4-622-7811
On Tue, Jul 28, 2015 at 7:49 AM, Ben Adams notifications@github.com wrote:
Allocate buffers, larger than 85k to push them into LoH, slice with ArraySegment or similar
— Reply to this email directly or view it on GitHub https://github.com/dotnet/coreclr/issues/1236#issuecomment-125445155.
 GrabYourPitchforks
commented
4 years ago
GrabYourPitchforks
commented
4 years ago  SingleAccretion
commented
1 year ago
SingleAccretion
commented
1 year ago This capability has been exposed via the GC.AllocateArray(pinned: true) API.
In our scenario, we do a lot of I/O work. The problem with I/O is that it requires pinning the memory. Which lead to fragmentation. We tend to pool those buffers early on system start, but because they are pinned, they cannot be moved to higher gens, and cause fragmentation of Gen0.
It would be great if we had a way to tell the GC "hey, this is going to be around for a long time, and it is going to be pinned, so move it somewhere out of the way".