 benaadams
commented
8 years ago
benaadams
commented
8 years ago Was seeing something similar here: https://github.com/dotnet/coreclr/issues/6132
Also have some threadpool tweaks that may or maynot help here: https://github.com/dotnet/coreclr/pull/5943
Would be interested on how they work on a 48 core machine if you have the time?
 nathana1
nathana1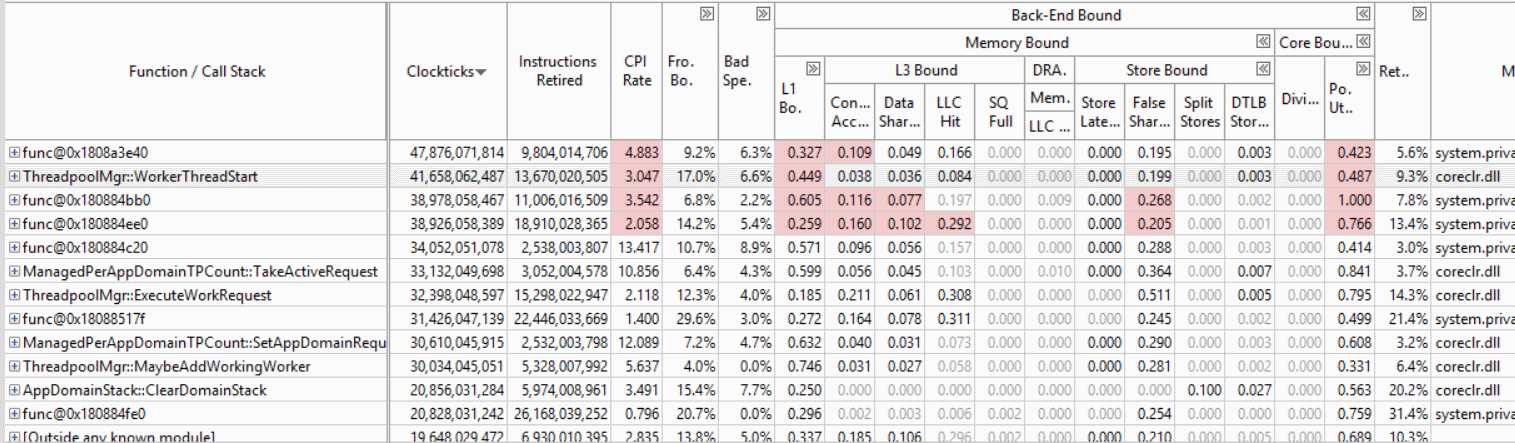
 ghost
ghost kouvel
kouvel sdmaclea
sdmaclea stephentoub
stephentoub
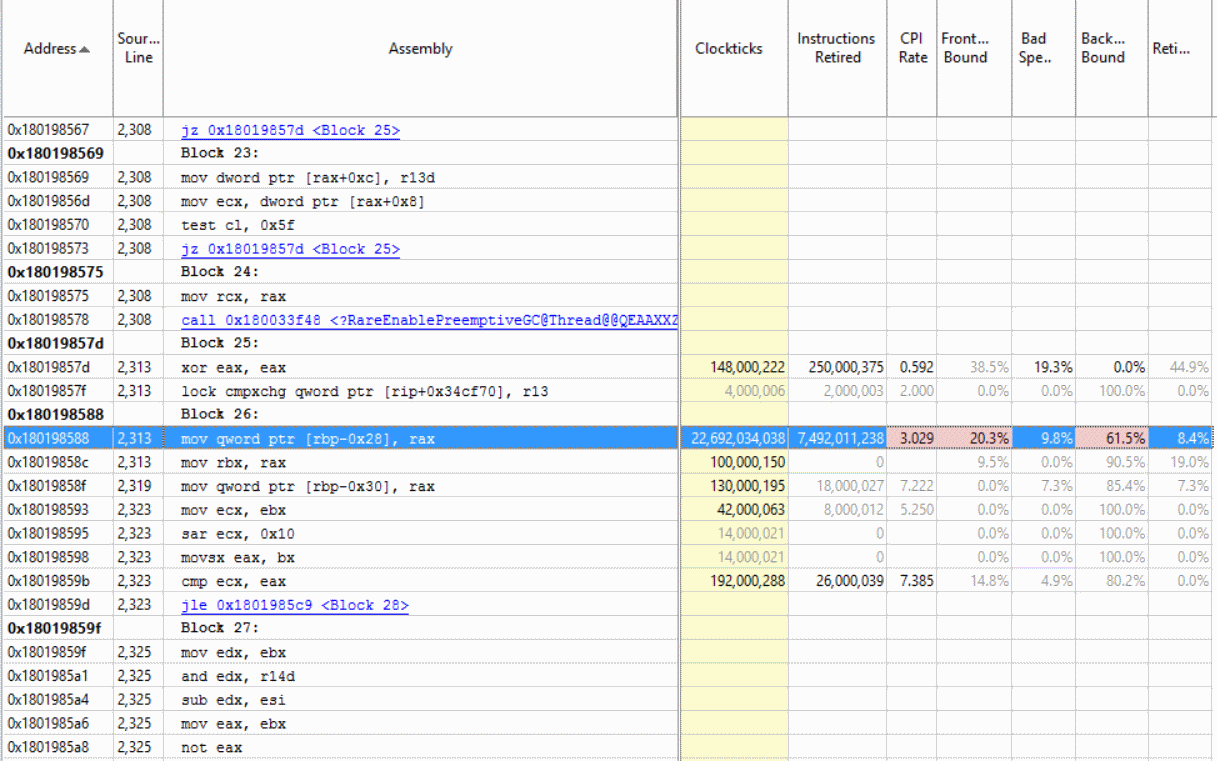
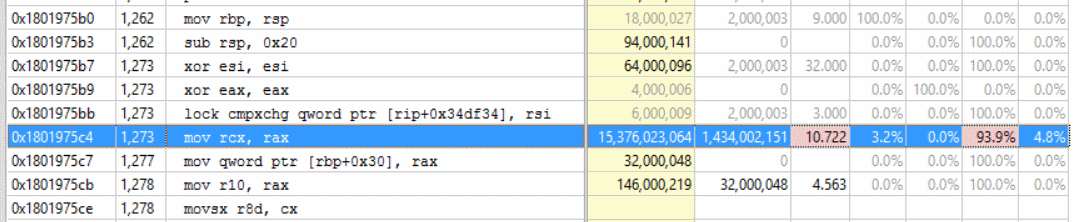
On our 48 core machine we are not able to push about 90% cpu utilization on some simple ASP.NET core scenarios (TechEmpower plaintext). We saturate the cpu and have corresponding better throughput on Windows. During investigation we've had a few theories but no concrete answers yet: