 ghost
commented
2 years ago
ghost
commented
2 years ago Tagging subscribers to this area: @tarekgh, @tommcdon, @pjanotti See info in area-owners.md if you want to be subscribed.
Issue Details
Eventsource can provide a lot of useful information for diagnosing problems. It works well when you can isolate the machine and application so that it is the only source of trace messages. If however you are trying to analyze performance or errors in a high load environment, then turning on diagnostic logging will produce a fire-hose of information, and the production of that information will have an impact on the performance (the schrodinger's cat problem). What you ideally want to be able to do is to sample the tracing, but sampling should be on a "request" basis. You want to be able to mark a request as sampled, and then collect detailed logs, just for those requests. This needs to flow through the async call stacks and trace all work that is done on its behalf. As an illustration, we have been trying to do better analysis of YARP performance, to better understand where time is going in processing requests, and why we are not getting as good results as some other products. In the test lab, we are running around 200k req/s and each request is taking ~800ms. If we turn on tracing, it will have an adverse effect on perf. What we want to be able to do is set a flag on maybe 0.1% of requests and get detailed logging for them. @MihaZupan has done an experiment where he is using Activity.Record as the bit to indicate the request should be sampled, and a custom build of System.Net. He came up with the following results: 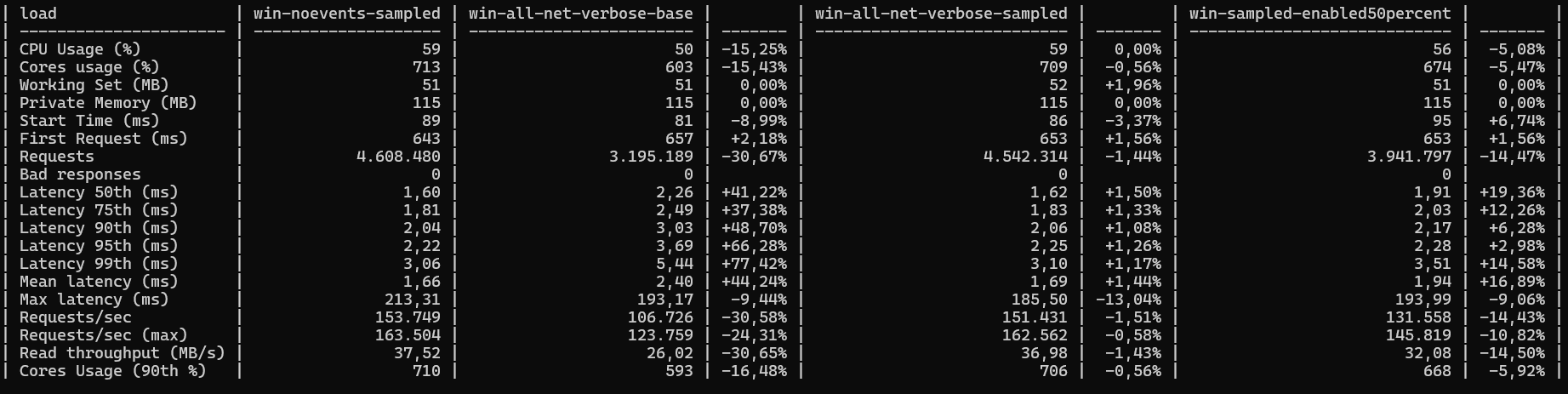 | Column | Definition | ----- | win-noevents-sampled | regular YARP with no EventSource enabled | | win-all-net-verbose-base | enable all System.Net.* and InternalDiagnostics EventSources without any changes to the instrumentation | | win-all-net-verbose-sampled | enable all System.Net.* and InternalDiagnostics EventSources but with a patched build of runtime that does Activity.Current checks | | win-sampled-enabled50percent | actively choose to sample 50% of requests (you can see the perf hit is pretty much 50% compared to enabling everything without changes) | What this says is that actually checking for `Log.IsEnabled() && (Activity.Current?.Recorded ?? false)` is not having an impact on performance. This makes me think that we should look to have a mechanism build into EventSource to be able to set a log level for activities with the record flag, so that you can easily collect sample-based traces. What is cool about this is that you can collect very detailed traces, including verbose level detail, for a small number of requests, so collect really detailed information, but while having minimal effect on the overall performance of the system. This kind of capability is required to be able to diagnose problems against the running infrastructure without affecting other customers, or overall system performance. If we can enable this for the BCL and other libraries then customers can get a much better picture of what is going on without having to rework the application to detect what is going on. You can then either decide to mark requests at the beginning of processing to be sampled, or use distributed tracing to be able to flow that flag through a graph of services.
| Author: | samsp-msft |
|---|---|
| Assignees: | - |
| Labels: | `area-System.Diagnostics.Tracing`, `untriaged` |
| Milestone: | - |
 brianrob
brianrob samsp-msft
samsp-msft MihaZupan
MihaZupan noahfalk
noahfalk
Eventsource can provide a lot of useful information for diagnosing problems. It works well when you can isolate the machine and application so that it is the only source of trace messages.
If however you are trying to analyze performance or errors in a high load environment, then turning on diagnostic logging will produce a fire-hose of information, and the production of that information will have an impact on the performance (the schrodinger's cat problem).
What you ideally want to be able to do is to sample the tracing, but sampling should be on a "request" basis. You want to be able to mark a request as sampled, and then collect detailed logs, just for those requests. This needs to flow through the async call stacks and trace all work that is done on its behalf.
As an illustration, we have been trying to do better analysis of YARP performance, to better understand where time is going in processing requests, and why we are not getting as good results as some other products. In the test lab, we are running around 200k req/s and each request is taking ~800ms. If we turn on tracing, it will have an adverse effect on perf. What we want to be able to do is set a flag on maybe 0.1% of requests and get detailed logging for them.
@MihaZupan has done an experiment where he is using Activity.Record as the bit to indicate the request should be sampled, and a custom build of System.Net. He came up with the following results:
What this says is that actually checking for
Log.IsEnabled() && (Activity.Current?.Recorded ?? false)is not having an impact on performance, and so you can make sample based event profiling pay for play.This makes me think that we should look to have a mechanism build into EventSource to be able to set a log level for activities with the record flag, so that you can easily collect sample-based traces. What is cool about this is that you can collect very detailed traces, including verbose level detail, for a small number of requests, so collect really detailed information, but while having minimal effect on the overall performance of the system. This kind of capability is required to be able to diagnose problems against the running infrastructure without affecting other customers, or overall system performance. If we can enable this for the BCL and other libraries then customers can get a much better picture of what is going on without having to rework the application to detect what is going on.
You can then either decide to mark requests at the beginning of processing to be sampled, or use distributed tracing to be able to flow that flag through a graph of services.