Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation(pSp)
Abstract
Pixel2Style2Pixel(pSp)는 image-to-image 프레임워크를 따른다.
pSp는 style vector들을 만드는 encoder network를 가지고 있다. 이 style vector는 pretrained Style-GAN genertor에 들어가게 된다.(W+ latent space로 확장되어 들어가기도 한다.)
우선, real image를 W+ latent sapce로 embedding 하는 것을 보인다.(추가된 optimization 없는 버전으로)
또한 input image를 다시 잘 만들기 위해서 만든 loss를 소개한다.
pSp를 통해서 스타일 리샘플링을 하면 전역 접근 방식으로 스타일 표현이 가능하다.(기존은 픽셀대 픽셀에 대응하는 스타일 샘플링을 하였다.)
pSp를 가지고 face align, segmentation, high-resolution image를 만들어 낼 수 있다.
1. Introduction
Background
GANs 은 실제적인 얼굴을 만들어내는 network로 이용된다.
StyleGAN은 style 기반 generator 이며, high-resolution image를 만들어 낸다. 또한 Multi-Layer Perceptorn(MLP) mapping network를 이용하여 initial latent space(Z)를 disentangled latnet space(W)로 만들었기 때문에 editing 기능이 된다.
최근에는 StyleGAN's latent space를 조작하는 방법이 소개되기도 한다. StyleGAN latent space 조작을 가지고 real image를 조작 가능하다.
그러나 512 차원 벡터인 w를 이용하면 정확한 이미지를 형성하기 어렵다. 그래서 real image를 다양한 방법으로 W+ latent space에 encode하여 18 different 512-dimentional w vector를 만들어 낸다.
W+로 encoding하는 방법은 어렵고 하나의 이미지를 생성해 내는데 몇분이 소요되는 단점이 있다.
이 최적화 과정을 더욱 빠르게 하기 위해서 대강 W+로 encoder하는 학습 방법 [주석 49,4]이 몇가지 존재한다. 이러한 방법은 좋은 시작 지점을 가지게 하는 이점을 가지고 있다.
In this paper
latent space embedding을 더 넓은 범위로 하는게 주 목적이다.
image를 W+로 바로 encoding하는 새로운 encoder architecture를 소개한다. encoder는 Feature Pyramid Network를 기반으로 하며, 각 pyramid scale에서 서로 다른 style feature vector를 추출한다. 그리고 바로 pretrained StyleGAN generator에 들어간다.
전체 과정은 encoder-decoder network 형태를 지니며, image-to-image translation tasks에 많은 이점을 줄 수 있다. 이 구조는 pix2pix에서 착안했으며 image-to-image tasks의 좋은 방법론이 될 것이다.
학습 과정을 간단하게 소개하면, discriminator는 학습할 필요가 없으며 pretrained StyleGAN generator을 이용하게 되면 다양한 이점이 생긴다.(어떤??)
많은 image-to-image의 네트워크는 generator에 residual feature map으로 구성된 encoder 결과값을 제공하는 방식으로 이루어져 있다.(creating a strong locality bias) 반대로, 본 논문의 generator는 오직 style vector만 input을 받게 된다.
main contribution
A novel StyleGAN encoder able to directly encode real face images into the W+ latent domain
A generic end-to-end framework for solving image-toimage translation tasks
2. Related Work
Latent Space Embedding
Image-to-Image
Latent-Space Manipulation
3. The pSp Framework
pSp framework는 pretrained StyleGAN generator와 W+ latent space를 주로 이룬다. 올바른 latent domain으로 encoding하기 위해서 각 input image를 일치시켜야 한다.
embeding 하는 기술을 간단하게 이야기 하자면, image를 input으로 넣어주고 encoder network의 마지막 레이어로 부터 W+을 만드는 것이다.(512-dimentsional vector)(총 18개의 style vecotr가 된다.)
그러나 이 구조는 강한 bottleneck을 가지고 있으며, 이는 original image의 미세한 부분을 반영하기가 어려워 진다. (이미지를 재 생성하는데 퀄리티의 한계가 발생한다.)
pSp는 pyramid encoder backbone 형식을 따른다. feature map을 3 level 크기로 나누어 추출한 뒤 map2style network에 넣어 준다. 이후 StyleGAN의 input으로 맞는 map scale에 각각 넣어준다.
결론적으로, 차원이 충분히 큰 feature map을 통하여 생성된 style vectors를 이용하는 것은 image generator의 성능 저하에 영향을 미치지 않는다.
face generation의 주요 챌린지는 input / output image 의 특성을 잘 찾아내는 것이다. 앞의 loss들은 facial identity를 찾아내는데 덜 민감하므로, 코사인 유사도를 이용한 방법을 추가로 채택하였다.
R(x) : pretrained ArcFace network
x : input image
ArcFace network(for face recognition)
Summary
전체 loss 수식
3.2. The benefits of the styleGAN domain
pSp 네트워크를 이용한 image to style 방법은 기존 translation framework랑 많이 다르다. 이 pSp model은 픽셀 정보를 global하게 다룬다.
This is a desired property as it has been shown that the locality bias limits current methods when handling non-local transformations.
3.3. Implementation Details
ResNet-IR architecture을 사용한 pSp network는 빠르게 학습하는데 이점이 있었다. 이를 StyleGAN2 generator trained (FFHQ) dataset에 적용시켜 보았다.
input image resolution(256x256)
학습시 Adam optimizer 이용
lr = 0.001
4. Applications and Experiments
Datasets
CelebA-HQ dataset : 30K
FFHQ dataset : 70K
4.1. StyleGAN Inversion
pSp framework로 StyleGAN Inversion을 수행 가능한지 확인. ALAE encoder와 IDInvert를 비교 대상으로 삼았음.
ALAE encoder : StyleGAN 기반 autoencoder : generator와 latent code generator를 나란히 수행하는 encoder
IDInver : real image를 latent domian으로 embedding 시키는 모델. W/W+ latent vector 가 된다.
Result
4.2. Face Frontalization
image-to-image translation의 도전과제 중 하나. 부족한 데이터셋이 문제. 이 도전과제는 3D alignment process과도 관련 있다.
Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation(pSp)
Abstract
1. Introduction
Background
In this paper
main contribution
2. Related Work
Latent Space Embedding
Image-to-Image
Latent-Space Manipulation
3. The pSp Framework
3.1. Loss Functions
pSp encoder에 사용된 loss를 소개한다.
pixel-wise L2 loss
input image와 generated image의 픽셀 값 차이를 알기 위한 loss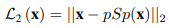
LPIPS loss
이미지 퀄리티를 보여주는 loss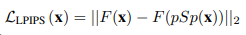
The Identitiy Loss
face generation의 주요 챌린지는 input / output image 의 특성을 잘 찾아내는 것이다. 앞의 loss들은 facial identity를 찾아내는데 덜 민감하므로, 코사인 유사도를 이용한 방법을 추가로 채택하였다.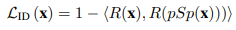
Summary
전체 loss 수식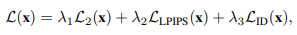
3.2. The benefits of the styleGAN domain
pSp 네트워크를 이용한 image to style 방법은 기존 translation framework랑 많이 다르다. 이 pSp model은 픽셀 정보를 global하게 다룬다. This is a desired property as it has been shown that the locality bias limits current methods when handling non-local transformations.
3.3. Implementation Details
4. Applications and Experiments
Datasets
4.1. StyleGAN Inversion
pSp framework로 StyleGAN Inversion을 수행 가능한지 확인. ALAE encoder와 IDInvert를 비교 대상으로 삼았음.
Result
4.2. Face Frontalization
image-to-image translation의 도전과제 중 하나. 부족한 데이터셋이 문제. 이 도전과제는 3D alignment process과도 관련 있다.
4.3. Conditional Image Synthesis
4.3.1. Face From Sketch
4.3.2. Face from Segmentation Map
4.4. Super Resolution
4.5. Additional Applications