 Optimox
commented
1 year ago
Optimox
commented
1 year ago This error often appears when you have Nans in your data. If things are working properly with cross entropy this must come from your custom loss.
Maybe try to lower the learning rate or clip the gradient norm.
 jbjaypark
jbjaypark
Describe the bug
While training the classifier after a couple backward steps a index -1 should be selected in entmax calculation, which is out of bounds for feature matrix with shape[1] = 172
What is the current behavior?
If the current behavior is a bug, please provide the steps to reproduce.
Expected behavior Training should correctly work with custom loss.
Screenshots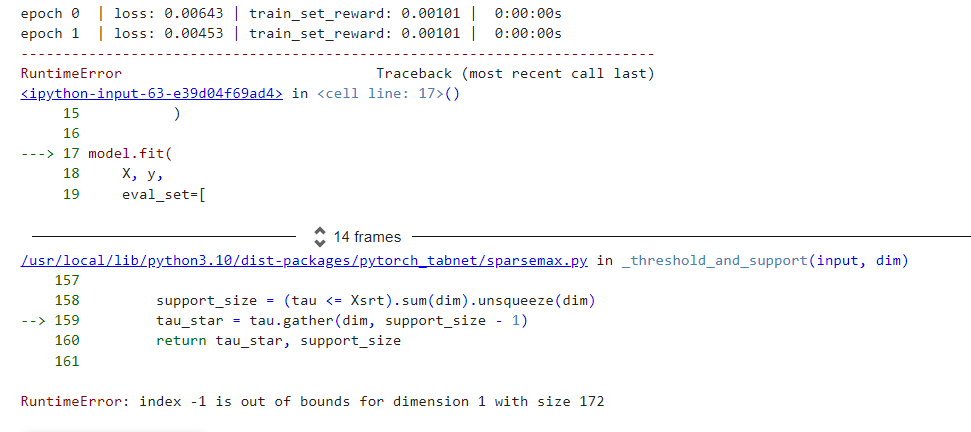
Other relevant information:
Additional context When standard cross entropy is used, the training works fine. So it must have something to do with the custom loss.