Optimox
commented
1 year ago
Optimox
commented
1 year ago pytorch-tabnet is using CUDA if pytorch is using CUDA, there is nothing specific to tabnet here.
So two questions:
- What do you get when trying
torch.cuda.is_available()? - You seem to be using Windows, are you sure that the GPU usage is correctly shown ?
Describe the bug When choosing
device_name="cuda", the training is not done on GPUWhat is the current behavior? Training is carried out on CPU
If the current behavior is a bug, please provide the steps to reproduce.
Expected behavior When choosing CUDA, I expect the GPU RAM to be used instead of the CPU RAM. Also when a custom loss and eval metric is used.
Screenshots During training: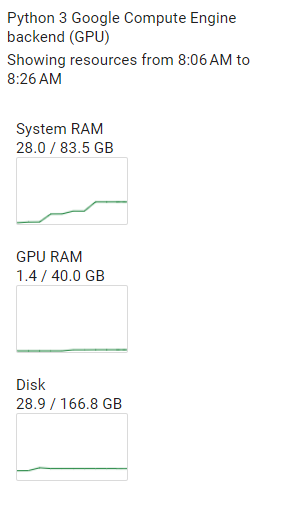
Specs: