 ruebot
commented
7 years ago
ruebot
commented
7 years ago :-1: If it is required.
Further discussion in this thread: https://groups.google.com/forum/#!msg/pcdm/Ep1Cty2JDx4/Hdw8I5pbDwAJ
Closed escowles closed 7 years ago
ruebot
commented
7 years ago :-1: If it is required.
Further discussion in this thread: https://groups.google.com/forum/#!msg/pcdm/Ep1Cty2JDx4/Hdw8I5pbDwAJ
 whikloj
commented
7 years ago
whikloj
commented
7 years ago I've said it before, but I think enforcing an additional resource for the (I have no numbers to back this up...but) small percentage of use cases that will need multiple file sets is not to the general benefit.
I understand the opinion around consistency for development, but I don't find this particularly persuasive. It seems that we can find some way to allow for the need of multiple FileSets without requiring them for all PCDM based resources.
 mjgiarlo
commented
7 years ago
mjgiarlo
commented
7 years ago @whikloj Can you say more about your use cases? What kinds of content do you need to support?
ruebot
commented
7 years ago @mjgiarlo at bare minimum, the content we support now in Islandora 1.x; which, I am near 100% sure, does not have any public use cases from the Islandora Community on the need for multiple FileSets as described. Should we need FileSets, we'd be perfectly happy using the FileSets extension.
:-1: forcing FileSets
 acoburn
commented
7 years ago
acoburn
commented
7 years ago If the PCDM vocabulary did not use predicates such as pcdm:hasMember, pcdm:hasFileSet and pcdm:hasFile (and encouraged people to use ore:aggregates), then the model would support both the simple and complex use case. (With or without FileSets).
whikloj
commented
7 years ago @mjgiarlo I think @ruebot and @acoburn have covered what I would say (and better than I could). Essentially, we could use pcdm:FileSets but for every object in our repository it would be a single lonely pcdm:FileSet and therefore extraneous data with no benefit. So could we not make it optional.
 tpendragon
commented
7 years ago
tpendragon
commented
7 years ago @acoburn
If the PCDM vocabulary did not use predicates such as pcdm:hasMember, pcdm:hasFileSet and pcdm:hasFile (and encouraged people to use ore:aggregates), then the model would support both the simple and complex use case. (With or without FileSets).
whikloj
commented
7 years ago @mjgiarlo sorry our data is 90% newspapers. But the question is more about the possibility of multiple FileSets. We scan and, for better or worse, never scan again. So a second FileSet is extremely unlikely in most all of our use cases.
But perhaps I am misunderstanding the use cases that drove this need.
tpendragon
commented
7 years ago @whikloj @ruebot @awoods The majority of the objects in your repository don't store derivatives? The goal of FileSets is "here's a grouping of binaries and a description about why they're grouped."
If FileSets aren't required, then I assume you just never have multiple FileSets, and your object representing "Page 1" just has three files hooked to it and there's no reason to group the master with the derivatives because only one of those is a master and you can identify it?
So, is optional filesets something we can imagine an ingest routine for? "If it uses hasFileSet, go there for files, if it just hasFile, go there, there's only one grouping, if it has both...I dunno, count it as three filesets?"
tpendragon
commented
7 years ago Ah, forgot to mention, the reason multiple filesets became a thing was there were institutions who had multiple masters for a single "page".
 DiegoPino
commented
7 years ago
DiegoPino
commented
7 years ago @tpendragon if i understand correctly, then the use case that motivated this new rdfs Class is having multiple Masters, with multiple derivatives each one for a same real world entity(page 1 of book 1 for example).
by the way Islandora(and @whikloj) do store Derivatives and a lot of them. I don't feel our use cases are that different, but our approaches are.
Grouping multiple binary resources together under a FileSet Class can be solved(without FileSet) by linking (via a specific predicate, not necessarily in PCDM space) a given Master binary to it's derivatives. You could even make another construct, via proxy's that point to the Binary you want to consider your canonical Master. Just one of many ways. How do you solve the "which of the many masters" problem with FileSet?
I also start to understand that some of this needs are based on programming paradigms, which is maybe the miss understanding we have here, and has probably something to do with how Hydra does data modelling hardcoding structure (based on rdf class to ruby class matching, just guessing) versus what we want to do (trying to extract structure, constraints and requirements from Ontologies and triple store)
If it uses hasFileSet, go there for files, if it just hasFile, go there, there's only one grouping, if it has both...I dunno, count it as three filesets?".
That is what i mean with hardcoded. The ontology itself (the semantic definition of the class + object properties allowed and their target classes) should give us that info instead of the code. I feel that is the idea of using Linked data. I'm not saying one approach is better than other. I'm saying we defer probably on how we deal with the logic over the structure.
tpendragon
commented
7 years ago based on rdf class to ruby class matching, just guessing
Nah, it's totally arbitrary. We store a model statement on the resource to map to the ruby class.
The ontology itself (the semantic definition of the class + object properties allowed and their target classes) should give us that info instead of the code.
I suppose my hypothesis is that this specification is only as good as the tools we can build which utilize it. Arbitrary ingest was just an example. Someone somewhere will have to build that logic, if we can encode that logic into the ontology via restraints that they the developer will have to follow, then great.
Grouping multiple binary resources together under a FileSet Class can be solved(without FileSet) by linking (via a specific predicate, not necessarily in PCDM space) a given Master binary to it's derivatives.
So I think in order to do this we'd have to redefine what a pcdm:File is, because right now it's a binary file. Bits don't have RDF statements - they can have nodes which describe them, but that's not part of the ontology now (except in the case of FileSets).
tpendragon
commented
7 years ago Ah, I may be letting Fedora leak into my previous argument. To be clear, you're proposing:
GET x
<x> <hasFile> <y>
<x> <hasFile> <z>
<y> <type> <master>
<z> <type> <derivative>
<z> <derivedFrom> <y>Which I think solves that case, yeah.
tpendragon
commented
7 years ago We've always said Files only have access and technical metadata. What's derivedFrom?
tpendragon
commented
7 years ago The other issue is one of practicality: FileSets are implementable in LDP, and specifically Fedora.
If we say <z> <derivedFrom> <y> is the structure we want, it might not be.
 cmharlow
commented
7 years ago
cmharlow
commented
7 years ago Just a comment, not pro or con filesets at this point: < derivedFrom > to my mind would count as technical metadata. It is expressing the technical process (via the relationship) used to generate that binary. There's an ebucore property that could possibly be used there, if we go that route.
mjgiarlo
commented
7 years ago @ruebot What does "the content [you] support now in Islandora 1.x" look like? If you've already got this jotted down somewhere, I'd be happy to review existing documentation rather than expect you to type it all out. :) I'm struggling to imagine that Islandora doesn't already have robust support for multi-file works.
acoburn
commented
7 years ago w/r/t FileSets, they are, IMO a very natural way to describe book-like objects. They are, effectively, how we describe thousands of such objects in our current repo: Manuscript -> Page -> (Set of files w/ color targets) and (set of files w/o color target). And I would expect to model them the same way going forward w/ F4.
There are other objects in our repo (hundreds of thousands of them). For these resources, the FileSet abstraction is unnecessary. For these, I could live with that additional layer (FileSets) if necessary, even if not ideal.
Looking into the future, one of the big areas of growth in our repository will be faculty research data. This data does not look anything like books. An example from last semester: perterbations of protein data observed over a period of time (as in several million observations over hundreds of specific protein chains). For this data, not only would FileSets be not quite to the point, the entire PCDM structure would likely get in the way. And no, I do not see "put all the data into a big zip file and be done with it" as an option.
So I am left with a choice: do I model some objects (e.g. book-like things) using PCDM and some objects in ORE or do I attempt to have consistency across the repository in terms of how structural metadata is expressed. Personally, I opt for the latter.
 scossu
commented
7 years ago
scossu
commented
7 years ago In this parallel discussion FileSets are regarded as specific aggregations representing "digital content" in an abstract sense. The Files that they aggregate are different manifestations (i.e. different file formats, encodings, derivations, subsets, etc.) of the same digital source, so they have specific common traits.
This gives FileSets a defined role (e.g. a scan of a page) distinguished from other pcdm:Objects which represent higher-level aggregations (e.g. pages, books, collections etc.).
Even with a FileSet with one File (which is quite unlikely because you will almost surely have a thumbnail, an access image, a preservation copy, an OCR or metadata extract, etc.) you would still benefit from having an independent FileSet to put descriptive metadata about the digitized content. The dc:creator of a pcdm:Object may be the monk who wrote a book page, the dc:creator of the pcdm:File the photographer who reproduced it, and so on.
:+1: to FileSets.
scossu
commented
7 years ago Sorry, wrong link for the discussion mentioned. I mean this one: https://groups.google.com/forum/#!topic/hydra-tech/u181eBfgJcU
 escowles
commented
7 years ago
escowles
commented
7 years ago What if we made FileSet not a subclass of Object (the current proposal), but allowed a single resource to be a FileSet and an Object at the same time? This would allow users to skip the extra node if they had no use for it. For example, if you had an Object with both image and text representations, you could have separate FileSets to separate them out:
<o1> a pcdm:Object ;
rdfs:label "p. 1" ;
pcdm:hasFileSet <fs1>, <fs2> .
<fs1> a pcdm:FileSet ;
rdfs:label "page image" ;
pcdm:hasFile <f1>, <f2> .
<fs2> a pcdm:FileSet ;
rdfs:label "transcription" ;
pcdm:hasFile <f3> .
<f1> a pcdm:File ;
ebucore:filename "page1.tiff" .
<f2> a pcdm:File ;
ebucore:filename "page1.jp2" .
<f3> a pcdm:File ;
ebucore:filename "page1.tei" .But you could also just having a single Object/FileSet combo resource:
<o2> a pcdm:Object, pcdm:FileSet ;
rdfs:label "p. 1" ;
pcdm:hasFile <f1>, <f2>, <f3> .This again would conflate the concepts of real world object and digital content. I find having a dedicated class fot the latter very useful.
I don't see a problem with a FileSet hanging out by itself or potentially having multiple relationships with other Objects. At AIC we have Assets (wannabe FileSets), such as a photographic portrait, that can be representations of both an artwork and a person (Objects).
scossu
commented
7 years ago In the above for FileSet I meant "a digital reproduction of a photographic portrait".
Also, in the scenario you lay out:
<o2> a pcdm:Object, pcdm:FileSet ;
rdfs:label "p. 1" ;
pcdm:hasFile <f1>, <f2>, <f3> .you may think you are content with a simple book page that has only one image. But if in 5 years you make a better reproduction of that page, you will have a hard time separating the old reproduction from the new one.
This discussion seems very similar to the one about the ordering ontology and about why we build a complex structure even for a simple scenario: the reason is to be interoperable and allow for expansion.
escowles
commented
7 years ago @scossu , I agree that it complicates things if you re-scan a page. But what I'm hearing from @whikloj is that they just don't re-scan things. So separating the page Object from the FileSet would just add an additional node, without providing them any benefit.
whikloj
commented
7 years ago @escowles exactly, I'd love to re-scan but the funding is generally always for new digitization, so...
We currently have only 675,000 newspaper pages in Fedora 3.
Every page has a single master (Tiff) and derivatives, and as I said we never re-scan unless the original is useless to use. In which case we don't add the useless scan.
So a set of pcdm:File(s) attached to a pcdm:Object with (perhaps) pcdm use or ebucore predicates is perfectly workable.
Heck I don't even really want my derivatives in Fedora (but that is a Claw discussion).
So while I accept that some people want/need the ability to have multiple FileSets. To me it is just an extra layer to traverse.
scossu
commented
7 years ago The benefit would be in separating the metadata about the newspaper page and the one about its scan.
they just don't re-scan things
@whikloj is this correct? I wonder how one would not even leave room for an option.
whikloj
commented
7 years ago The benefit would be in separating the metadata about the newspaper page and the one about its scan.
So see I would put the metadata about the newspaper page on the pcdm:Object (RdfSource) and the metadata about the scan on the pcdm:File (NonRdfSource).
@scossu, I'm not saying we don't leave room for the ability. But as it has not yet happened, I would love it was an option. But why force the extra layer for everything?
scossu
commented
7 years ago So see I would put the metadata about the newspaper page on the pcdm:Object (RdfSource) and the metadata about the scan on the pcdm:File (NonRdfSource).
You would put the descriptive metadata about the page (e.g. the author of the article(s), date of publication) in the Object; descriptive metadata about the digitized content (author and date of the scan) in the FileSet and technical metadata about the file itself (characterization, file timestamp, etc.) in the File.
why force the extra layer for everything?
To have one single model to predictably store and find information instead of two different ones depending on whether you plan on having one or more files.
whikloj
commented
7 years ago @scossu Why would you not put descriptive metadata about the digitized content on the File itself?
 dannylamb
commented
7 years ago
dannylamb
commented
7 years ago :-1: to FileSet if it forces unneccessary nesting.
:+1: if it doesn't. Why not just use FileSet in lieu of Object when you know you won't have any members, just files? I can just put my descriptive metadata on the fileset.
If we don't plan on having members, we shouldn't have to enforce the entirety of the hydra works structure, which is what this addition to the ontology feels like.
I'd prefer to allow for more complicated structures to be built, but wouldn't sacrifice the simple use cases for generic uniformity. I'd rather have lots of small explicit structures than one generic one.
scossu
commented
7 years ago @whikloj Because according to the model I am describing the File would be a specific manifestation of the FileSet. The content would be the same for every File in the FileSet, except in a different serialization or a subset of it. Therefore, the most convenient place for descriptive metadata would be the FileSet.
scossu
commented
7 years ago Why not just use FileSet in lieu of Object when you know you won't have any members, just files? I can just put my descriptive metadata on the fileset.
@dannylamb you got the point. You may have e.g. a loan agreement as a self-standing FileSet that you can relate to any Object in any way you want, if/when you want.
scossu
commented
7 years ago  azaroth42
commented
7 years ago
azaroth42
commented
7 years ago Why would you not put descriptive metadata about the digitized content on the File itself?
Because the model says you can't do that, and it has always said that.
whikloj
commented
7 years ago @azaroth42 but in @scossu's example he said
... descriptive metadata about the digitized content (author and date of the scan) in the FileSet...
The model for pcdm:File says
The metadata typically includes at least basic technical metadata (size, content type, modification date, etc.), but can also include properties related to preservation, digitization process, provenance, etc.
Is that not the same thing?
dannylamb
commented
7 years ago @scossu Yes, that's another possible use case. Or you could proxy the FileSet ifyou want to share it around.
But I'm thinking about breaking the forced nesting. If a FileSet can stand on its own then it's vastly more useful for me. You certainly can nest it if you want. I'm not going to stop that. But I don't think I should be forced to when I don't need to.
If I only have one representation, and one scan, what compels me to adopt a more complex than necessary structure? I want to use the same vocabulary as Hydra, but I don't want full blown Hydra Works all the time. I don't need that.
ruebot
commented
7 years ago Files MUST be contained by exactly one Object.
Will that need to be changed as well? Will it be: "Files MUST be contained by exactly one FileSet" or "Files CAN be contained by multiple FileSets" or something else?
Another question I have, is what is the container type for FileSets? Is it a BasicContainer? One of my main reservations was that we would lose the "files" DirectContainer we have outlined here.
escowles
commented
7 years ago @ruebot I would change that to "Files MUST be contained by exactly one FileSet", with a FileSet being a BasicContainer, containing the files DirectContainer.
ruebot
commented
7 years ago @escowles Hrm. I was under the impression that the files container was an IndirectContainer. If that's not the case, I'll have to reconsider my position on FileSets.
scossu
commented
7 years ago @ruebot "Files MUST be contained by exactly one Object" would become "Files MUST be contained by exactly one FileSet".
As for container type, I think that is a concern external to PCDM. I see LDP containment and PCDM membership as parallel concepts supporting each other but semantically independent.
whikloj
commented
7 years ago As for container type, I think that is a concern external to PCDM. I see LDP containment and PCDM membership as parallel concepts supporting each other but semantically independent.
👍
ruebot
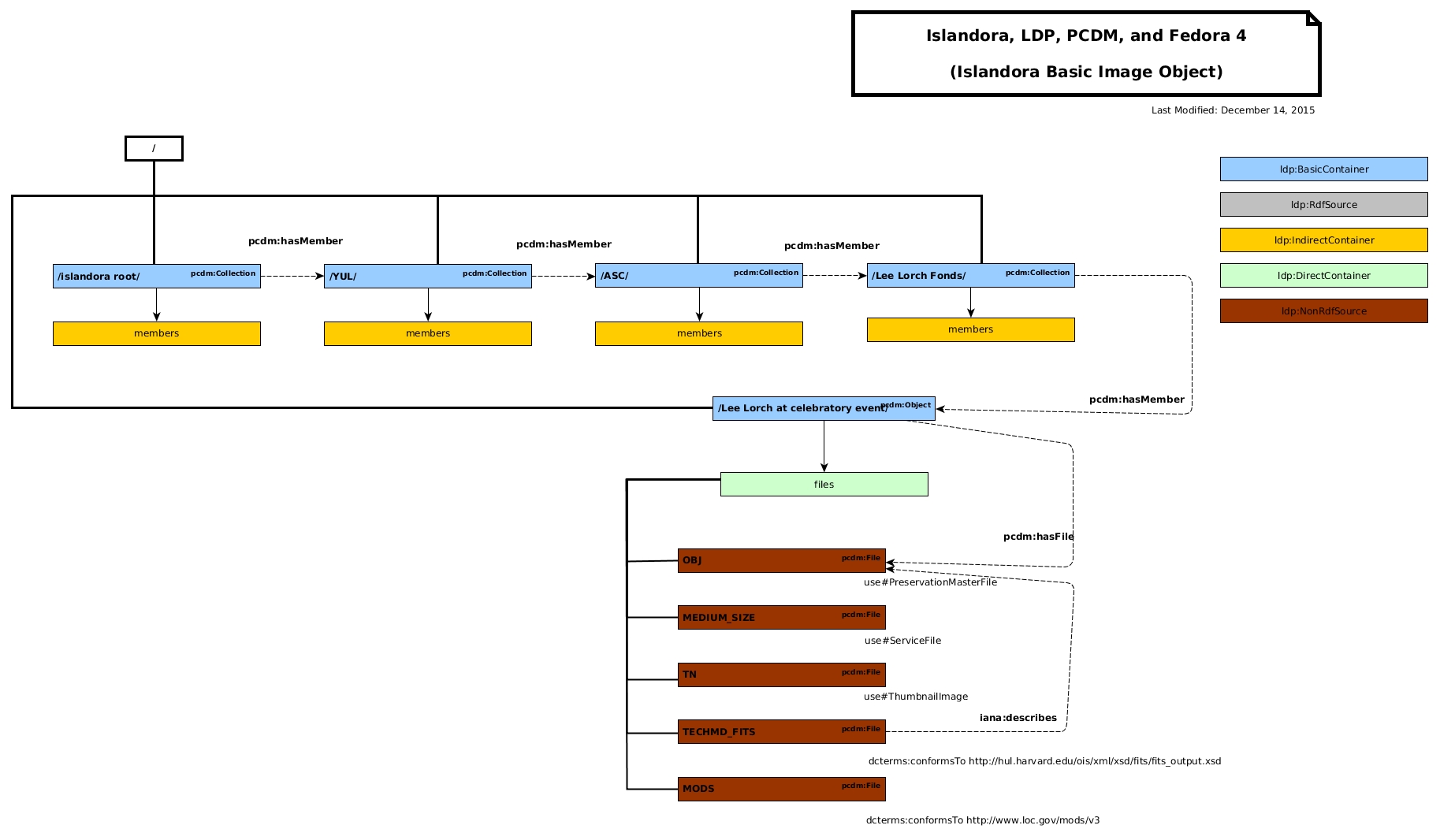
commented
7 years ago If I'm understanding everything right, this is what pcdm:FileSet would like like implemented on the existing Islandora CLAW PCDM diagrams:

scossu
commented
7 years ago @ruebot yes, if you intend the pcdm:hasFile relationship to apply to JP2, JPG, and TN as well.
dannylamb
commented
7 years ago reason for not having the fileset be the direct container itself? not a criticism. just curious.
escowles
commented
7 years ago @dannylamb Maybe we could have the FileSet be a DirectContainer itself. Would it be more palatable if the LDP projection was basically the same, we're just calling out existing files DirectContainer and saying it's an appropriate place to attach metadata about the files as a group?
tpendragon
commented
7 years ago Huh. Does multiple direct containers work? The problem would be you'd have to manage a link that isn't ldp:contains to find the "FileSet"
scossu
commented
7 years ago I am not quite following the discussion about LDP here and maybe I am missing an important part of the PCDM fundamentals, so bear with me.
How is PCDM related to LDP, and most important, is PCDM membership related to LDP containment? My understanding is that PCDM defines the role of resources and their semantic relationships, while LDP focuses on structure and traversal. If we are talking about implementation examples around @ruebot's graph, I understand. If we are introducing LDP concepts in PCDM I would be OK as well, I just would like to know if this has always been a common understanding.
To this point, I would actually rephrase @ruebot's statement to "Files MUST be members of exactly one FileSet".
escowles
commented
7 years ago @scossu There's always been some tension about how to treat LDP: on one hand, PCDM is an abstract model that could be implemented in any number of systems. But on the other hand, most of the people involved in PCDM are planning to implement it with Fedora 4, so how PCDM maps to LDP is an important consideration.
So I would say that LDP is definitely not a part of PCDM or required to use it. But many people who use PCDM are also interested in LDP, so it makes sense to also agree on the mapping (though separately from the modeling discussions).
In this particular case, I think the LDP mapping is relevant to the modeling discussion, because it changes whether adding an extra FileSet node results in adding an extra LDP container or not (with implications for scalability, etc.). If adding a FileSet only results in slightly redefining an existing container in the LDP projection, then maybe that lessens the objection to requiring it.
escowles
commented
7 years ago @tpendragon I believe that we could have a pcdm:Object as a BasicContainer and it could have multiple DirectContainers which were FileSets. This would result in the Object having direct hasFile links to each of the Files, and you could also add hasFileSet linking to the FileSets, which would link to their containing Files with ldp:contains. The triples would look like:
<http://example.org/obj1> a pcdm:Object, ldp:BasicContainer ;
ldp:contains <http://example.org/obj1/files>, <http://example.org/obj1/files2> ;
pcdm:hasFile <http://example.org/obj1/files/f1>, <http://example.org/obj1/files/f2>,
<http://example.org/obj1/files2/f3>, <http://example.org/obj1/files2/f4> ;
pcdm:hasFileSet <http://example.org/obj1/files>, <http://example.org/obj1/files2> .
<http://example.org/obj1/files> a pcdm:FileSet, ldp:DirectContainer ;
ldp:membershipResource <http://example.org/obj1> ;
ldp:hasMemberRelation pcdm:hasFile ;
ldp:contains <http://example.org/obj1/files/f1>, <http://example.org/obj1/files/f2> .
<http://example.org/obj1/files/f1> a pcdm:File ;
rdfs:label "page1.tiff" .
<http://example.org/obj1/files/f2> a pcdm:File ;
rdfs:label "page1.jp2" .
<http://example.org/obj1/files2> a pcdm:FileSet, ldp:DirectContainer ;
ldp:membershipResource <http://example.org/obj1> ;
ldp:hasMemberRelation pcdm:hasFile ;
ldp:contains <http://example.org/obj1/files2/f3>, <http://example.org/obj1/files2/f4> .
<http://example.org/obj1/files2/f3> a pcdm:File ;
rdfs:label "page1.tiff" .
<http://example.org/obj1/files2/f4> a pcdm:File ;
rdfs:label "page1.jp2" . awead
commented
7 years ago
awead
commented
7 years ago Can we clarify that we're using LDP or not? see #56
I'm mildly +1 on using LDP, but I think we need a definitive answer on the topic before proceeding with further discussion about FileSets.
{kind=link}
The works extension includes a FileSet class that represents an original file and other files derived from it. The Hydra implementation has found this to be a very useful structure, and the key to separating Objects that represent component parts of other Objects from groupings of Files.
Should we add a FileSet class to the core ontology?
See #53 for preliminary discussion.