 mspiekermann
commented
3 years ago
mspiekermann
commented
3 years ago - Implement data exchange (push data to HTTP-endpoint)
- Trigger IDS
Closed mspiekermann closed 2 years ago
mspiekermann
commented
3 years ago  ticapix
commented
2 years ago
ticapix
commented
2 years ago Hello,
If I understood correctly, EDC is set to enforce data usage policies when exchanging data.
To do that, 2 EDC instances will verify and negotiate permissions and usage rights.
From this diagram https://raw.githubusercontent.com/eclipse-dataspaceconnector/DataSpaceConnector/main/docs/diagrams/mvp.png, is it correct that the data transfer is going through the EDCs instance and not directly done between the 2 data storage endpoints (fileshares) ?
If correct, how is the system planning to scale ? In order to avoid becoming a bottleneck, does the infrastructure deployed for the EDC itself need to match the specifications (CPU, Bandwidth, Latency) of the data storage endpoints (fileshares) ?
Best regards, Pierre
mspiekermann
commented
2 years ago Hi @ticapix,
the MVP scenario you just linked follows requirements of initaitves that currently use the EDC to support messages by the International Data Space, which currently follow the approach of a data transfer through the Connector component.
The important aspect here: while this is possible with the EDC and used for the MVP along the user's requirements, it is not the intended way the EDC handles data transfer and data flow. The EDC separates control and data plane and ensures scalability by mediating between two EDC instances by two processes (abstraction!), a) the contract and policy part and b) the data flow via out-of-band communication.
So you get it right from the MVP diagram point of view, but the EDC is already able to deal differently with the shortcomings of this approach, which btw (due to its limits) is currently also being discussed to be changed in the IDS initiative.
ticapix
commented
2 years ago Hi @mspiekermann ,
Thank you.
The out-of-band communication scenario is ensured with a sidecar (envoy) that is deployed by the data storage provider[1] with administrative rights[2] on the storage controllers[3] ?
Pierre
[1]: Data storage provider is the organisation managing the storage. Could be the same organisation than the data owner if this is a self-managed tenant or a CSP if this is an off-the-shelf managed subscription.
[2] administrative rights:
[3]: storage controllers: entity with logical and direct access to the data (CEPH/S3/SWIFT storage nodes, HDFS datanodes, FTP server, Kafka brokers, ...)
mspiekermann
commented
2 years ago There is not only that one possibility i would say, how this could be enabled. Adding control and observability with the sidecar pattern is something that defenitly should be considered. Envoy would just be one example for a proxy capability, that is often used with the sidecar pattern to add control to micorservices, so no direct link here. I will have a try to visualize how this can look like with the EDC...
 jimmarino
commented
2 years ago
jimmarino
commented
2 years ago Hi @ticapix,
As @mspiekermann mentioned, sidecars are one deployment scenario if someone is using K8S or similar infrastructure. However, this could also be generalized. For example, the data transfer plane could be a separate set of services operated by one of the parties to the transfer or a third-party. Access to the data plane could be via an API that each connector uses. This would also enable the scenarios you outlined above with minimal infrastructure.
One concrete example of this could be a healthcare dataspace where the data must travel across a secure, private network layer.
The EDC is essentially a transfer process coordinator. It can run separate from the data plane itself as long as there is a control link between the EDC and the latter.
Does this answer your question?
ticapix
commented
2 years ago Hi @jimmarino
Not really. I understand the data/control plane arch. However it requires the control plane to have control over the data plane, which I don't see yet for EDC. The exemple of K8s was given, but K8s is a container orchestrator not a data storage. Unless EDC plans to deploy at runtime storage services (mongodb, kafka, HDFS, S3/SWIFT, ...) inside a K8s cluster ?
We described 4 scenario so far:
| Proxy | Coordinator | Provider | Embedded | |
|---|---|---|---|---|
| Pros | easy to setup up | scale at low cost | one stop solution | better integration for consumer |
| Cons | expensive since the EDC infrastructure must match data storage controller specs to not become the bottleneck | coordinate the first transfer only or requires modification of the data storage offer, doesn't enforce policies | not an industry-grade solution, expensive because must move data 2 times and infra must scale | (not a cons but a warning) requires integration within data storage service offers, expensive development, long term (~years) |
Have I capture all the scenario ? Pierre
jimmarino
commented
2 years ago @ticapix sorry for the delay, we were tied up with the EDC Hackathon last week.
I suspect we may be talking about different things. With the EDC, data transfer generally happens out-of-band, that is, the flow of bits is carried out by other infrastructure. This could be a Kafka cluster, cloud events, blob storage transfer, etc. Two EDC participants will coordinate with this infrastructure on their respective ends. For example, in a transfer between AWS S3 and Azure Object Storage, the EDC on the Azure side will setup a receiving container and temporary access credentials for the EDC on the S3 end to signal its infrastructure to stream out of a bucket to the Azure destination.
I'm simplifying the flow a bit (for example instead of pushing data, "pull" scenarios can also be enabled) but this captures the overall architecture. Usage control can be further applied, for example, the destination Azure container could be confined to a geographic region.
There are also hooks in the EDC to conduct asynchronous provisioning of resources prior to data transfer. This could potentially be used to deploy storage resources, prep data or other tasks.
Does this answer your question?
ticapix
commented
2 years ago Hi @jimmarino
We're getting closer :)
With the EDC, data transfer generally happens out-of-band,
and
the EDC on the Azure side will setup a receiving container
That the coordinator mode as described above, provisioning managed services. Is that correct ?
jimmarino
commented
2 years ago My mental model is that the EDC is always a "coordinator" in that it manages the contract and data flow process (which are asynchronous state machines). How much it "manages" depends on the deployment. For example, an EDC may provision cloud resources (or send a request to other infrastructure to do so), or not provision anything, in which case it would use "static" or "pre-deployed" infrastructure.
A simple example would be S3 buckets. An EDC could be setup to dynamically create them or use pre-existing buckets.
ticapix
commented
2 years ago Ok. In the coordinator mode, EDC can't enforce usage right. It can negotiate access for the first time. Once the access tokens to storage endpoints are shared, it's out of EDC control. In which case, what does EDC solve that a traditional open policy agent + terraform/Ansible can't ?
jimmarino
commented
2 years ago @ticapix Sorry if my explanation was unclear but the EDC can enforce access control. There are a number of ways to do this.
In the case where storage endpoints are used, the EDC can be configured to create either temporary or long-term access credentials. It can also revoke those credentials at any time for long-running/non-finite processes (e.g., streams). With some infrastructures, it is even possible for the EDC to push down policy to the network layer for tighter control.
One large scale project building on EDC in the travel industry is using EDC to control access to a Data Service (API). Access to that service can be revoked, updated, or limited throughout the data access lifecycle.
EDC can use OPA to establish controls and different infrastructure layers. Many users provision EDC setups using Terraform. However, EDC, OPA, Terraform, and Ansible are completely different technologies that solve different problems. Terraform, Ansible, and OPA do not solve the problem of policy-based data sharing. In turn, the EDC does not solve the problem of provisioning deployments or configuring policy in a generic runtime environment.
Basically, EDC solves the problem of how different entities can:
Advertise assets (not just data) and usage policies, and in turn, discover assets offered by others in distributed environments. This is the federated catalog architecture we demonstrated working at our last Hackathon.
Enforce access control to those assets based on flexible identity and trust models (e.g. OAuth2, distributed identity solutions). We demonstrated this working in our first Hackathon using OAuth2 and a distributed identity system built on ION and Bitcoin. In our second Hackathon, we demonstrated a second distributed identity system built on Web DIDs.
Establish electronic contracts based on usage policies for the exchange of assets between two participants that is auditable. A fully functioning policy engine has been in place for some time. Our milestone release to be released on Friday adds initial support for contract negotiation scenarios.
Initiate the exchange of assets in an interoperable way using existing data-sharing technologies. This has been in place for some time, including multi-cloud support.
Coordinate the enforcement of usage policies by integrating with storage and other infrastructure technologies for the receiving participant. Several EDC contributors are currently working on integration with OPA
We plan on releasing Milestone 1 on Friday, December 3. Of course, there is still a lot of work to be done, but this release will provide many of the key pieces of our vision for dataspaces as well as a strong foundation for GAIA-X use cases that center on data sharing.
I hope this clarifies things.
ticapix
commented
2 years ago Hi @jimmarino
The sequence of actions is still unclear to me.
I agree that, if EDC was granted control over the user's tenant:
However, once the first token has been shared - or access granted - I don't get how EDC knows when to update its state machine.
After step 8, how is EDC aware of what actions must be taken to update the access rights ?
Pierre
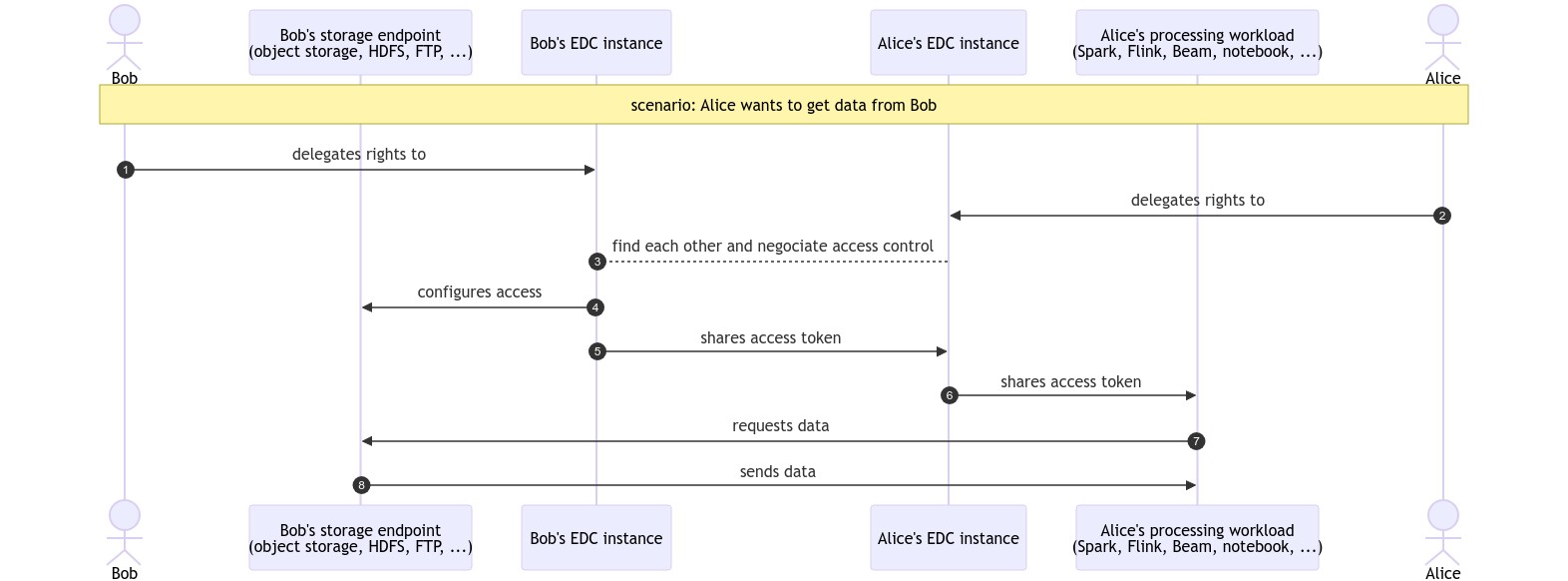
sequenceDiagram
autonumber
actor bob as Bob
participant data_bob as Bob's storage endpoint<br>(object storage, HDFS, FTP, ...)
participant edc_bob as Bob's EDC instance
participant edc_alice as Alice's EDC instance
participant process_alice as Alice's processing workload<br>(Spark, Flink, Beam, notebook, ...)
actor alice as Alice
Note over bob, alice: scenario: Alice wants to get data from Bob
bob ->> edc_bob: delegates rights to
alice ->> edc_alice: delegates rights to
edc_bob --> edc_alice: find each other and negociate access control
edc_bob ->> data_bob: configures access
edc_bob ->> edc_alice: shares access token
edc_alice ->> process_alice: shares access token
process_alice ->> data_bob: requests data
data_bob ->> process_alice: sends dataA few questions in order to answer that:
ticapix
commented
2 years ago If the goal is to have EDC acting as one time access control, then my question is not relevant.
If the goal is to have EDC really controlling the data access over time, then access rights must be updated. (This is the scenario that was advertised by the Mobility dataspace)
BTW, none of the above answer one of my other questions: How EDC control which data is being accessed but we can finish this thread first.
jimmarino
commented
2 years ago Part of the issue we are having is that our discussion is too abstract, and we don't have a common set of terminology to settle on.
My suggestion would be to back up and define a specific use case we want to address. Once we have that defined, we can map that to an EDC architecture. Otherwise, I'm afraid we will go in circles, and I won't do a good job answering your questions.
That said, Catena-X, EONA-X, the Mobility DataSpace and others (there will be public announcements soon) are committed to using the EDC as the foundation of their dataspace platforms. Shall we pick a specific use case from one of those projects and walk through a detailed analysis of how the EDC is being used? As I mentioned, our Milestone 1 release is due on Friday, so what we walkthrough will be actual code, not plans or diagrams. This should allow us to drill down to a very concrete level quickly.
If you want, I can pick a use case and involve relevant people from one of those projects in the discussion. Let me know.
ticapix
commented
2 years ago The sequence diagram above is pretty clear to me, so was the table with the different modes, but ok.
Considering that none of the usecases I heard or have in mind seems to work with EDC, could you provide one ?
Thank you, Pierre
jimmarino
commented
2 years ago @ticapix
The sequence diagram above is pretty clear to me, so was the table with the different modes, but ok.
Considering that none of the usecases I heard or have in mind seems to work with EDC, could you provide one ?
Thank you, Pierre
@ticapix Please don't jump to conclusions. We never said the use cases you have in mind won't work. We are having difficulty arriving at a common set of terminology. We will outline a very specific use case based on an actual project that is currently being developed. I believe this will allow us to make progress as well as keep the discussion grounded in concrete terms.
{kind=link}