 hadyelsahar
commented
4 years ago
hadyelsahar
commented
4 years ago Quantifying Exposure Bias for Neural Language Generation Withdrawn ICLR2020 https://openreview.net/forum?id=rJg2fTNtwr
"We develop a precise, quantifiable definition for exposure bias. Surprisingly, according to our measurements in controlled experiments, there’s only around 3% performance gain when the training-inference discrepancy is completely removed. Our results suggest the exposure bias problem could be much less serious than it is currently assumed to be."
 ibrahimsharaf
ibrahimsharaf mahmoudSalim
mahmoudSalim islamelhosary
islamelhosary Omarito2412
Omarito2412 ship-it-mind
ship-it-mind
 Ragabov
Ragabov mukhal
mukhal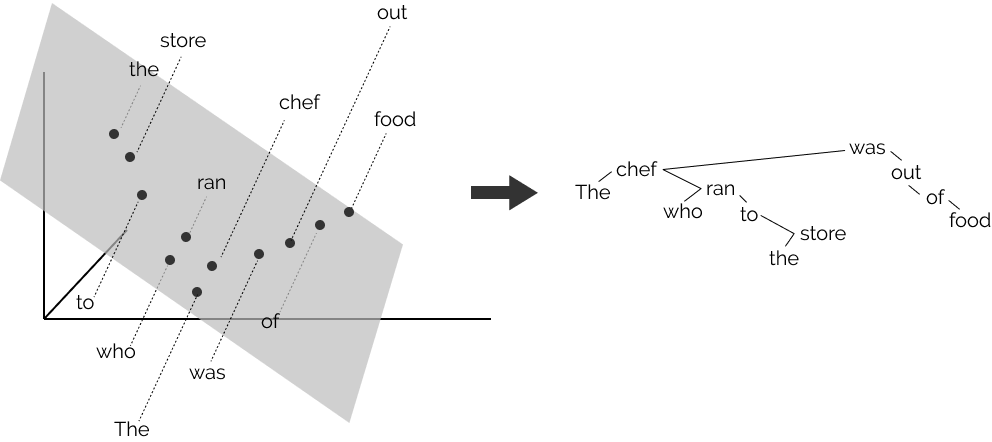


 EngSalem
EngSalem
In this issue you can either: