 eirikb
commented
10 years ago
eirikb
commented
10 years ago That looks great.
I've been thinking to add other package systems to nipster, for example by having tabs on the top (such as NuGet, gulp, bower, aur, etc.). Perhaps this could be part of that?
About publishing the backend I'm not sure if I'm ready for that.
I probably should do just that, but I feel it needs some cleanup, and I would have to hide things like keys. It's a private repo (not on gh).
Here is the NPM-related parts of it, just to show you: https://gist.github.com/eirikb/04bebf18ea8588ebb0ed
 xmojmr
xmojmr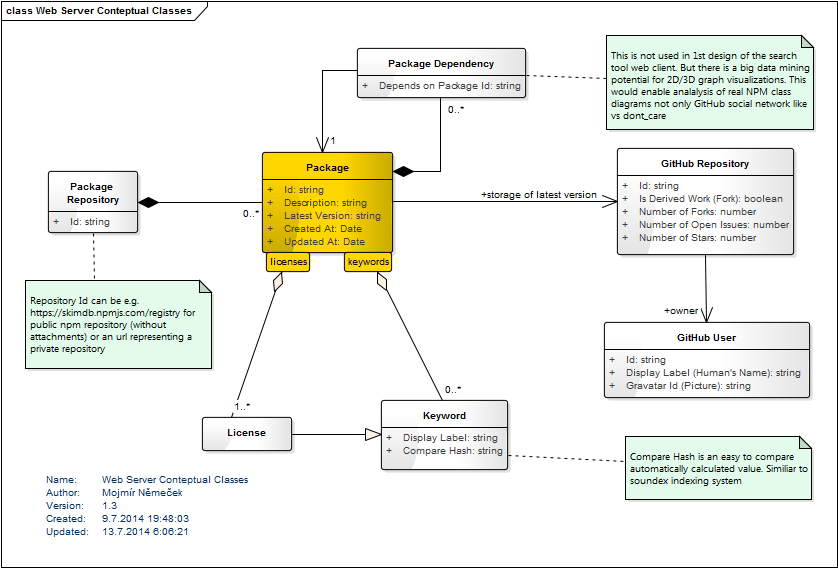{kind=link}
{kind=link}
Finding the
nipsterwas a great surprise for me. I used the original code base and the design as base for JavaScript component search tool, now hosted at http://component.xmojmr.czThe
componentdataset is smaller (only ~3000 records), but with richer column set. e.g. the tags column enables searching the dataset by a tag-cloud filter. All repositories are hosted at GitHubI'd like to try my design against the npm-datatables.json dataset but in its present state there is not enough useful information in it
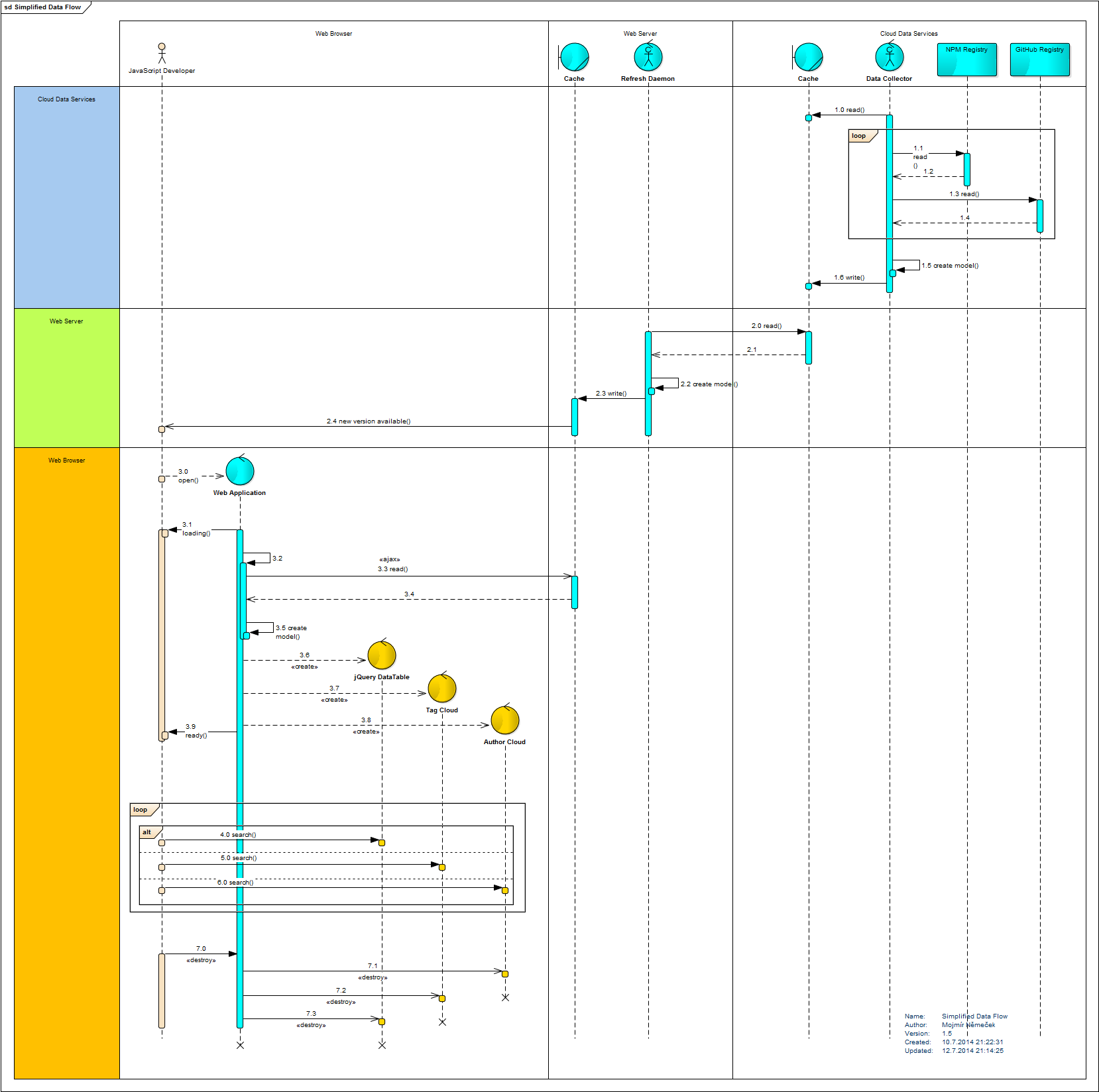
I also did not find sources of the dataset update engine mentioned in #14
Can you publish the sources or extend the dataset with more columns (as used in the component search tool)?
At this moment I'd make use of just one-time dataset, no updates needed, just to have some data for the proof of concept prototype