 elliewhite-usgs
commented
3 years ago
elliewhite-usgs
commented
3 years ago good bot.
Closed github-learning-lab[bot] closed 3 years ago
elliewhite-usgs
commented
3 years ago good bot.
 github-learning-lab[bot]
commented
3 years ago
github-learning-lab[bot]
commented
3 years ago If you've written your own functions or scripts before, you may have run into the red breakpoint dot :red_circle: on the left side of your script window:
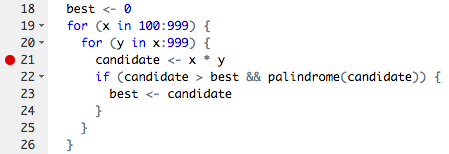
Breakpoints allow you to run a function (or script) up until the line of the breakpoint, and then the evaluation pauses. You are able to inspect all variables available at that point in the evaluation, and even step carefully forward one line at a time. It is out of scope of this exercise to go through exactly how to use debuggers, but they are powerful and helpful tools. It would be a good idea to read up on them if you haven't run into breakpoints yet.
In targets, you can't set a breakpoint in the "normal" way, which would be clicking on the line number after you sourced the script. Instead, you need to use the other method for debugging in R, which requires adding the function call browser() to the line where you'd like the function call to stop and specifying an additional argument when you call tar_make().
:warning: Check your RStudio version (go to the Help menu and click About RStudio). If you have a version earlier than v1.3.5, you may want to consider updating RStudio before proceeding to have the smoothest experience in debugging mode. :warning:
You have a working, albeit brittle, pipeline in your course repository. You can try it out with targets::tar_make(). This pipeline has a number of things you'll work to fix later, but for now, it is a useful reference. The pipeline contains a _targets.R file and several functions defined in .R files.
So, if you wanted to look at what download_files were created within the download_nwis_data() function, you could set a breakpoint by adding browser() to the "1_fetch/src/get_nwis_data.R" file (make sure to hit save for changes to take affect!). Hint: to quickly navigate to this function source code from your makefile, you can put your cursor on the name of the function then click F2 and it will take you to the correct location in the corresponding source file!

There is one more step to get your breakpoint to work in targets. You will need to add callr_function = NULL to your tar_make() call. When you run tar_make(callr_function = NULL), you will land right in the middle of line 8. Give it a try on your own.
To navigate while in browser mode, you can use the buttons at the top of your console pane:

:keyboard: Place a browser() in the for loop of the download_nwis_data() function. Build the pipeline and compare the size of data_out through each iteration of the loop using the debugger navigational features. When you are done, don't forget to remove the browser() command from that function and then save the R script. Then, comment here on where you think you might find browser() handy in future pipelines.
elliewhite-usgs
commented
3 years ago @lindsayplatt I get this error:
x error target site_data Error: 01432160 has failed due to connection timeout. Try tar_make() again
any idea what could be going on? I can step through the loop one time, but on the second iteration browser[2]: it times out.
I think browser function will become handy when we want to change one part of the pipeline and something downstream breaks. It would be nice to figure out where exactly we've got trouble with this method of debugging. It also has the nice advantage of not messing up the global environment while we are testing functions.
github-learning-lab[bot]
commented
3 years ago Seeing the structure of a pipeline as a visual is powerful. Viewing connections between targets and the direction data is flowing in can help you better understand the role of pipelines in data science work. Once you are more familiar with pipelines, using the same visuals can help you diagnose problems.
Below is a makefile that is very similar to the one you have in your code repository (the option configurations and source calls were removed for brevity, but they are unchanged):
p1_targets_list <- list(
tar_target(
site_data,
download_nwis_data(),
),
tar_target(
site_info_csv,
nwis_site_info(fileout = "1_fetch/out/site_info.csv", site_data),
format = "file"
),
tar_target(
nwis_01427207_data_csv,
download_nwis_site_data('1_fetch/out/nwis_01427207_data.csv'),
format = "file"
),
tar_target(
nwis_01435000_data_csv,
download_nwis_site_data('1_fetch/out/nwis_01435000_data.csv'),
format = "file"
)
)
p2_targets_list <- list(
tar_target(
site_data_clean,
process_data(site_data)
),
tar_target(
site_data_annotated,
annotate_data(site_data_clean, site_filename = site_info_csv)
),
tar_target(
site_data_styled,
style_data(site_data_annotated)
)
)
p3_targets_list <- list(
tar_target(
figure_1_png,
plot_nwis_timeseries(fileout = "3_visualize/out/figure_1.png", site_data_styled),
format = "file"
)
)
Two file targets (nwis_01427207_data_csv and nwis_01435000_data_csv) were added to this makefile, but there were no changes to the functions, since download_nwis_site_data() already exists and is used to create a single file that contains water monitoring information for a single site.
The targets package has a nice function called tar_glimpse() that we haven't covered yet (if you get an error when you try to use it, run install.packages("visNetwork") and then try again). It produces a dependency diagram for the target(s) you pass to the allow argument (it will show all of them by default). For this modified makefile, calling that function with the default arguments produces:
targets::tar_glimpse()
If you run the same command, you'll see something similar but the two new files won't be included.
Seeing this diagram helps develop a greater understanding of some of the earlier concepts from intro-to-targets-pipelines. Here, you can clearly see the connection between site_data and figure_1_png. The figure_1 plot needs all of the previous steps to have run in order to build. The arrows communicate the connections (or "dependencies") between targets, and if a target doesn't have any arrows connected to it, it isn't depended on by another target and it doesn't depend on any another targets. The two new .csv files are both examples of this, and in the image above they are floating around with no connections. A floater target like these two will still be built by tar_make() if they are included in the final target list (e.g., here they appear in p1_targets_list which is included in the final target list returned at the end of _targets.R)
The diagram also shows how the inputs of one function create connections to the output of that function. site_data is used to build site_data_clean (and is the only input to that function) and it is also used as an input to "1_fetch/out/site_info.csv", since the nwis_site_info() function needs to know what sites to get information from. These relationships result in a split in the dependency diagram where site_data is directly depended on by two other targets.
Another useful technique for examining your pipeline connections is to use tar_manifest(), which returns a data.frame of information about the targets. While visual examination gives a complete overview, sometimes it is also useful to have programmatic access to your target names. Below is the table that is returned from tar_manifest() (remember that yours might be slightly different because it won't include the two new files).
tar_manifest()
# A tibble: 8 x 3
name command pattern
<chr> <chr> <chr>
1 site_data "download_nwis_data()" NA
2 nwis_01435000_data_c~ "download_nwis_site_data(\"1_fetch/out/nwis_01435000_data.csv\")" NA
3 nwis_01427207_data_c~ "download_nwis_site_data(\"1_fetch/out/nwis_01427207_data.csv\")" NA
4 site_data_clean "process_data(site_data)" NA
5 site_info_csv "nwis_site_info(fileout = \"1_fetch/out/site_info.csv\", \\n site_data)" NA
6 site_data_annotated "annotate_data(site_data_clean, site_filename = site_info_csv)" NA
7 site_data_styled "style_data(site_data_annotated)" NA
8 figure_1_png "plot_nwis_timeseries(fileout = \"3_visualize/out/figure_1.png\", \\n site_d~ NA :keyboard: comment on what you learned from exploring tar_glimpse() and tar_manifest().
elliewhite-usgs
commented
3 years ago tar_glimpse() shows you a network/visual of how the targets are connected. and tar_manifest() shows you the commands that make each target in a dataframe.
github-learning-lab[bot]
commented
3 years ago In the image contained within the previous comment, all of the shapes are circles of the same color. tar_glimpse() is useful to verify your pipeline connections, but once you start building your pipeline tar_visnetwork() creates a dependency diagram with more information and styles the shapes in ways to signify which targets are out of date or don't need to rebuild.
We've put some fragile elements in the pipeline that will be addressed later, but if you were able to muscle through the failures with multiple calls to tar_make(), you likely were able to build the figure at the end of the dependency chain. For this example, we'll stop short of building the figure_1_png target by calling tar_make('site_data_styled') instead to illustrate an outdated target.
The output of tar_visnetwork() after running tar_make('site_data_styled') (and having never built all targets by running tar_make() with no inputs) looks like this:

Only the colors have changed from the last example, signifying that the darker targets are "complete", but that figure_1_png and the two data.csv files still don't exist.
The targets package has a useful function called tar_outdated() which will list the incomplete targets that need to be updated in order to satisfy the output (once again, the default for this function is to reference all targets in the pipeline).
tar_outdated()
[1] "nwis_01435000_data_csv" "nwis_01427207_data_csv" "figure_1_png" This output tells us the same thing as the visual, namely that these three targets :point_up: are incomplete/outdated.
A build of the figure with tar_make('figure_1_png') will update the target dependencies, result in a tar_visnetwork() output which darkens the fill color on the figure_1_png shape, and cause a call to tar_outdated("figure_1_png") to result in an empty character vector, character(0), letting the user know the target is not outdated.
The figure_1_png target can become outdated again if there are any modifications to the upstream dependencies (follow the arrows in the diagram "upstream") or to the function plot_nwis_timeseries(). Additionally, a simple update to the value of one of the "fixed" arguments will cause the figure_1_png target to become outdated. Here the height argument was changed from 7 to 8:
tar_visnetwork("3_visualize/out/figure_1.png")
In the case of fixed arguments, changing the argument names, values, or even the order they are specified will create a change in the function definition and cause the output target to be considered outdated. Adding comments to the function code does not cause the function to be seen as changed.
:keyboard: using tar_visnetwork() and tar_outdated() can reveal unexpected connections between the target and the various dependencies. Comment on some of the different information you'd get from tar_visnetwork() that wouldn't be available in the output produced by tar_glimpse() or tar_manifest().
elliewhite-usgs
commented
3 years ago tar_visnetwork() shows the functions that were used to build the targets and whether or not any of the targets or functions are outdated with fill color.
github-learning-lab[bot]
commented
3 years ago Using tar_visnetwork() shows the dependency diagram of the pipeline. Look at previous comments to remind yourself of these visuals.
As a reminder, the direction of the arrows capture the dependency flow, and site_data sits on the left, since it is the first target that needs to be built.
Also note that there are no backward looking arrows. What if site_data relied on site_data_styled? In order to satisfy that relationship, an arrow would need to swing back up from site_data_styled and connect with site_data. Unfortunately, this creates a cyclical dependency since changes to one target change the other target and changes to that target feed back and change the original target...so on, and so forth...
This potentially infinite loop is confusing to think about and is also something that dependency managers can't support. If your pipeline contains a cyclical dependency, you will get an error when you try to run tar_make() or tar_visnetwork() that says "dependency graph contains a cycle". We won't say much more about this issue here, but note that in the early days of building pipelines if you run into the cyclical dependency error, this is what's going on.
:keyboard: Add a comment when you are ready to move on.
elliewhite-usgs
commented
3 years ago good bot.
github-learning-lab[bot]
commented
3 years ago Moving into a pipeline-way-of-thinking can reveal some suprising habits you created when working under a different paradigm. Moving the work of scripts into functions is one thing that helps compartmentalize thinking and organize data and code relationships, but smart pipelines require even more special attention to how functions are designed.
It is tempting to build functions that do several things; perhaps a plotting function also writes a table, or a data munging function returns a data.frame, but also writes a log file. If a function creates a file or output that is not returned by the command (i.e., it is a "side-effect" output), the file is untracked by the dependency manager because it has no "command" to specify how it is built. If the side-effect file is relied upon by a later target, changes to the side-effect target will indeed trigger a rebuild of the downstream target, but the dependency manager will have no way of knowing when the side-effect target itself should be rebuilt. :no_mobile_phones:
Maybe the above doesn't sound like a real issue, since the side-effect target would be updated every time the other explicit target it is paired with is rebuilt. But this becomes a scary problem (and our first real gotcha!) if the explicit target is not connected to the critical path of the final sets of targets you want to build, but the side-effect target is. What this means is that even if the explicit target is out of date, it will not be rebuilt because building this target is unnecessary to completing the final targets (remember "skip the work you don't need" :arrow_right_hook:). The dependency manager doesn't know that there is a hidden rule for updating the side-effect target and that this update is necessary for assuring the final targets are up-to-date and correct. :twisted_rightwards_arrows:
Side-effect targets can be used effectively, but doing so requires a good understanding of implications for tracking them and advanced strategies on how to specify rules and dependencies in a way that carries them along. :ballot_box_with_check:
Additionally, it is tempting to code a filepath within a function which has information that needs to be accessed in order to run. This seems harmless, since functions are tracked by the dependency manager and any changes to those will trigger rebuilds, right? Not quite. If a filepath like "1_fetch/in/my_metadata.csv" is specified as an argument to a function but is not also a target in the makefile recipe, any changes to the "1_fetch/in/my_metadata.csv" will go unnoticed by the dependency manager, since the string that specifies the file name remains unchanged. The system isn't smart enough to know that it needs to check whether that file has changed.
To depend on an input file, you first need to set up a simple target whose command returns the filepath of said file. Like so:
tar_target(my_metadata_csv, "1_fetch/in/my_metadata.csv", format = "file")Now say you had a function that needed this metadata input file for plotting because it contains latitude and longitude for your sites. To depend on this file as input, do this:
tar_target(map_of_sites, make_a_map(metadata_file = my_metadata_csv))but NOT like this (this would be the method that doesn't track changes to the file!):
tar_target(map_of_sites, make_a_map(metadata_file = "1_fetch/in/my_metadata.csv"))As a general rule, do not put filepaths in the body of a function. :end:
:keyboard: Add a comment when you are ready to move on
elliewhite-usgs
commented
3 years ago good bot!
github-learning-lab[bot]
commented
3 years ago You might have a project where there is a directory :file_folder: with a collection of files. To simplify the example, assume all of the files are .csv and have the same format. As part of the hypothetical project goals, these files need to be combined and formatted into a single plottable data.frame.
In a data pipeline, we'd want assurance that any time the number of files changes, we'd rebuild the resulting data.frame. Likewise, if at any point the contents of any one of the files changes, we'd also want to re-build the data.frame.
This hypothetical example could be coded as
library(targets)
source("combine_files.R")
list(
tar_target(in_files,
c('1_fetch/in/file1.csv',
'1_fetch/in/file2.csv',
'1_fetch/in/file3.csv'),
format = "file"),
tar_target(
plot_data,
combine_into_df(in_files)
),
tar_target(figure_1_png, my_plot(plot_data))
)While this solution would work, it is less than ideal because it doesn't scale well to many files, nor would it adapt to new files coming into the 1_fetch/in directory :file_folder: (the pipeline coder would need to manually add file names to the in_files target).
Lucky for us, the targets package can handle having a directory as a target. If you add a target for a directory, the pipeline will track changes to the directory and will rebuild if it detects changes to the contents a file, the name of a file, or the number of files in the directory changes.
To track changes to a directory, add the directory as a file target (see the in_dir target below). Important - you must add format = "file"! Then, you can use that directory as input to other functions. Note that you'd also need to modify your combine_into_df function to use dir(in_dir) to generate the file names since in_dir is just the name of the directory.
library(targets)
source("combine_files.R")
list(
tar_target(in_dir, '1_fetch/in', format = "file"),
tar_target(
plot_data,
combine_into_df(in_dir)
),
tar_target(figure_2_png, my_plot(plot_data))
)Yay! :star2: This works because a change to any one of the files (or an addition/deletion of a file) in 1_fetch/in will result in a rebuild of in_dir, which would cause a rebuild of plot_data.
:keyboard: Add a comment when you are ready to move on.
elliewhite-usgs
commented
3 years ago good bot!
github-learning-lab[bot]
commented
3 years ago Wow, we've gotten this far and haven't written a function that accepts anything other than an object target or a file target. I feel so constrained!
In reality, R functions have all kinds of other arguments, from logicals (TRUE/FALSE), to characters that specify which configurations to use.
The example in your working pipeline creates a figure, called 3_visualize/out/figure_1.png. Unless you've made a lot of modifications to the plot_nwis_timeseries() function, it has a few arguments that have default values, namely width = 12, height = 7, and units = 'in'. Nice, you can control your output plot size here!
We can add those to the makefile like so
tar_target(
figure_1_png,
plot_nwis_timeseries(fileout = "3_visualize/out/figure_1.png", site_data_styled,
width = 12, height = 7, units = 'in'),
format = "file"
)and it works! :star2:
What if we wanted to specify the same plot sizes for multiple plots? We could pass in width = 12, height = 7, and units = 'in' each time plot_nwis_timeseries is called OR we can create R objects in the makefile that define these configurations and use them for multiple targets.
You can add these
p_width <- 12
p_height <- 7
p_units <- "in"to your _targets.R file and then call them in the plot command for your targets, such as
tar_target(
figure_1_png,
plot_nwis_timeseries(fileout = "3_visualize/out/figure_1.png", site_data_styled,
width = p_width, height = p_height, units = p_units),
format = "file"
)Objects used in the command for tar_target() need to be created somewhere before they are called. It is usually a good idea to put configuration info near the top of the makefile. I would suggest adding the code to create these three objects immediately after your tar_option_set() call.
Another example of when this object (rather than target) pattern comes in handy is when we want to force a target to rebuild. Note that in the example below, we are writing the command for this target by putting two lines of code between {} rather than calling a separate custom function. You can do this for any target, but it is especially useful in this application when we just have two lines of code to execute.
library(targets)
list(
tar_target(
work_files,
{
dummy <- '2021-04-19'
item_file_download(sb_id = "4f4e4acae4b07f02db67d22b",
dest_dir = "1_fetch/tmp",
overwrite_file = TRUE)
},
format = "file",
packages = "sbtools"
)
)By adding this dummy object to our command argument for the work_files target, we can modify the dummy contents any time we want to force the update of work_files. Updating the dummy argument to today's date allows us to simultaneously force the update and record when we last downloaded the data from ScienceBase. You may see the use of these dummy arguments in spots where there is no other trigger that would cause a rebuild, such as pulling data from a remote webservice or website when targets has no way of knowing that new data are available on the same service URL.
:keyboard: Add a comment when you are ready to move on.
elliewhite-usgs
commented
3 years ago good bot!
github-learning-lab[bot]
commented
3 years ago
In this section, we're going to go one by one through a series of tips that will help you avoid common pitfalls in pipelines. These tips will help you in the next sections and in future work. A quick list of what's to come:
tar_visnetwork()andtar_outdated()to further interrogate the status of pipeline targets:keyboard: add a comment to this issue and the bot will respond with the next topic
I'll sit patiently until you comment