 marcizhu
commented
2 years ago
marcizhu
commented
2 years ago IMHO adding padding to ScrollingBuffer does not solve the underlying problem: you have a data race in your code. Adding padding without using mutexes is still undefined behaviour and might still show artifacts. I know mutexes are expensive, but it's the only solution that guarantees that the program won't randomly crash if, for example, one thread is reading the begin() of the buffer while the other thread is updating that exact same pointer.
 ToppDev
ToppDev epezent
epezent
Hello,
this is a feature request, as I don't think the library can handle this yet (tell me if otherwise).
Problem description
When inserting data in a ScrollingBuffer (implementation from the Demo), the following behavior occurs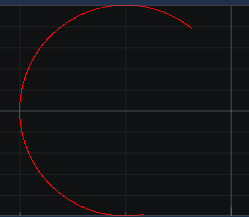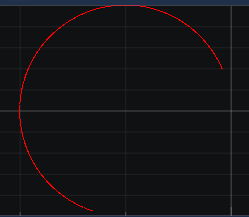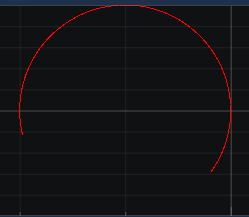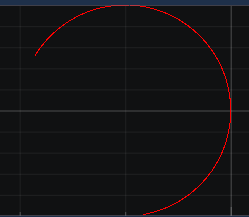
The plot often connects the start to the end of the circle and therefore causing weird lines to appear. I insert the data in a different thread than the plot thread, and that is why this happens.
Solution
I know that implot does not support multithreading, so one solution would be, to use mutexes, in order to make the data insertion and plotting thread safe. This however causes a lot of overhead, which I think can be avoided.
The solution I came up with is, to insert padding elements in my ScrollingBuffer. A quick example will explain what I mean with padding. (
smeans the start of the data,eis one after the last and marks the next insert position)Normal (unpadded) ScrollingBuffer
Padded ScrollingBuffer
The padded buffer has the advantage, that the old value is not directly overridden and therefore the circle would not connect the ends of the circle, but rather just plot a value which is one insertion old.
Improvements for ImPlot needed to make this work
The current behavior of the offset and the buffer is that it starts from the
offsetreadingsize - offsetelements and the jumping back to the start pointer and then reading tilloffsetNeeded would be an ability to tell the Getter how many elements come after the offset and not automatically calculate it with the formula
size - offset. I don't have in-depth knowledge of the ImPlot library so I don't know how this could be done the easiest way.Additional info / resources
Padded ScrollingBuffer implementation: https://compiler-explorer.com/z/6WPP3WTG6
Code in case compiler-explorer goes down
```C++ #include