 eugeneyan
commented
4 years ago
eugeneyan
commented
4 years ago Hey Eugene, came across your great article from LinkedIn! Had a couple of discussion points/questions.
- Just trying to be the devil's advocate here - could it be possible that the slow speed of sampling 2 million integers that you observed might be because your code is not vectorized?
Using numpy.random.randint only takes 11 ms for me to generate 2 million integers, while a simplified version of your approach without shuffling took 34 ms for me (for the latter, I don't know if there's a faster way to do it). Experimental results attached.
https://uploads.disquscdn.c...
-
I'm also wondering how the negative items in the test set were generated in the end using your approach of consuming the array 2 elements at a time. Did you check for every pair (a,b) whether (a,b) was in the positive set (i.e. had a score of > 0.5), and then add it to the negative set if that was not true?
-
For the 'pure' MF without biases, it does seem a bit interesting to me that there is such a 'cliff of death' behavior and exactly at the 0.5 threshold too. Is this something you have observed in other problems before and/or do you have any intuition as to why this happens? I'm actually curious to replicate it to see what's going on.
The curves in the models with bias seem more in line with what I expected - is the only difference in the models that each item has a single bias parameter?
Thanks!
Comment by Daryl Lim on 2020-01-21T08:50:45Z
 ityutin
ityutin vibhas-singh
vibhas-singh dvquy13
dvquy13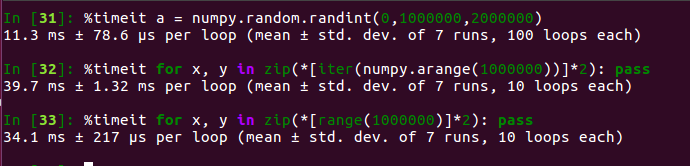{kind=link}
Migrated from json into utteranc.es