 betatim
commented
8 years ago
betatim
commented
8 years ago A minimal git repository that would work as "executable paper" for the "Great icecream preference study of 2016":
icecream-prefs/
|-> icecream/
| \-> ... library code ...
|-> data/ # include directly for small data or mount point for data-volumes
|-> Dockerfile # how to setup the environment
|-> paper.{ipynb,md} # the executable paper
|-> travis.yml # CI instructionsThe paper.{ipynb,md} drives the analysis, all the heavy lifting is done somewhere inside icecream/.
We can provide a the openscience command-line tool that create this layout, and uses it to allow you to run stuff locally using the docker container described in Dockerfile
 ctb
ctb khinsen
khinsen tritemio
tritemio cranmer
cranmer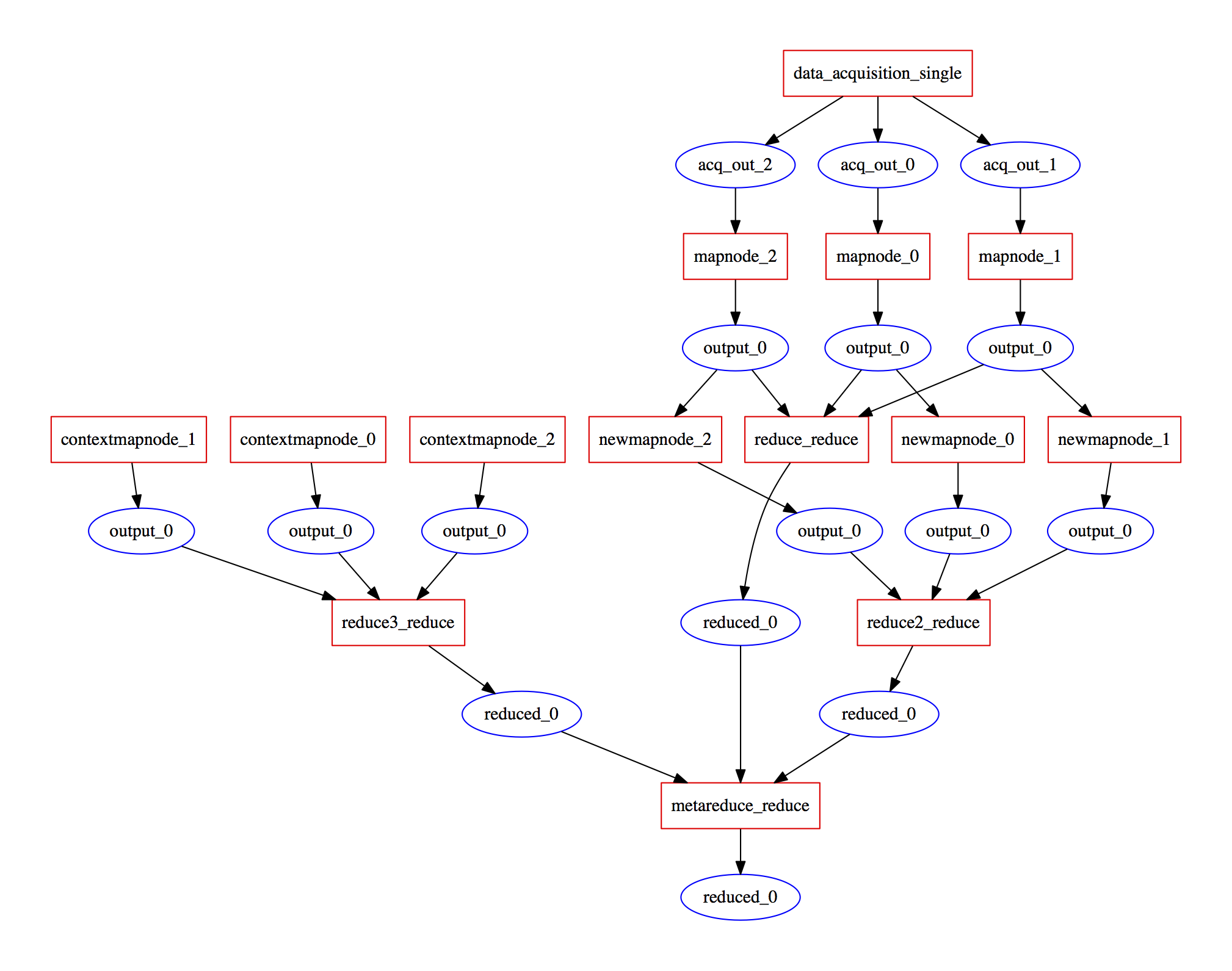 (boxes are "activities" and circles are "Entities" in the PROV language)
(boxes are "activities" and circles are "Entities" in the PROV language) lukasheinrich
lukasheinrich


 mr-c
mr-c
Outline the envisioned workflow for a scientist. With this we can build a better idea of what needs teaching, blue-printing, etc
First suggestion for a workflow:
openscience initto create a skeletongit init, creates a "sensible"Dockerfileopenscience run <cmd>which executes it inside the docker container.mdwith code blocks that has narrative mixed with steps for reproducing parts of the analysisgit commitall alongopenscience paper(?)(I will edit this entry as we iterate)