 lexuansanh
commented
3 years ago
lexuansanh
commented
3 years ago Because you put valid_generator in Model.fit_generator, Then data of valid_generator is augmented same as train_generator. This may affect the valid_generator evaluation. You can use the evaluate() function to evaluate on valid_generator. or tweak in _aug_image() function in BatchGenerator Class so that it doesn't modify the original image of valid data
 ghost
ghost
I am using custom data. I have modified the callbacks in train.py so that it is now monitoring validation loss from the validation set, as opposed to the training set. Original learning rate was 1e-4 `def create_callbacks(saved_weights_name, tensorboard_logs, model_to_save): makedirs(tensorboard_logs)
Here is a plot of loss, blue being validation loss and red being training loss: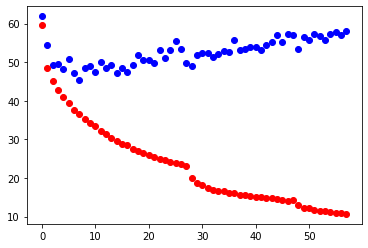
And here is a sample image of my dataset:
where same numbers are top left/bottom right of a bounding box. This example was pretty messy, but other people who have used this dataset claim to reach 70%+ map on a default single shot detector with no modifications. My maximum was 0.2. I am using the default yolov3 and haven't made any configurations. Here is my config: `{ "model" : { "min_input_size": 352, "max_input_size": 352, "anchors": [13,58, 18,14, 30,31, 47,55, 50,128, 75,24, 95,69, 126,121, 161,208], "labels": ["nlb"] },
} `
Data augmented from 612 -> 7140 for training set, valid_set = 152, test_set = 141. I have played around with increasing validation set but still get poor results. I changed initial learning rate from 1e-3 to 1e-5 but again, poor results. If anyone is willing to test it themselves, here are links to the dataset:
train images https://drive.google.com/drive/folders/1qmkCFNNuAtsOtFzQpmEgZyaN-DeSOuyr?usp=sharing train annot https://drive.google.com/drive/folders/1-5SZAcuOXz1Rt_eZ19RtVvgMXr8aId6j?usp=sharing valid images https://drive.google.com/drive/folders/1Xxz28iVaxXMIDA_UVQPKOAs0KfU4KtVT?usp=sharing valid annot https://drive.google.com/drive/folders/1Ml7DjEBwS50eUaMO378zYGdZTQsdfUNB?usp=sharing test images https://drive.google.com/drive/folders/1tEiW-Xx74kWua810sR5e0OyWvPABhJ1z?usp=sharing test annot https://drive.google.com/drive/folders/12jvZpb06tRopSpYLUSoiONOlvBWPV1ud?usp=sharing train.pkl file https://drive.google.com/file/d/1-5a1JGGYr6xP8ydCJOBOfhTPOym93u62/view?usp=sharing valid.pkl file https://drive.google.com/file/d/1-86kPCtYQKmYVzxyFZfQoNIf03_YdwDA/view?usp=sharing
I have spent an embarrassing amount of time trying to solve this problem.