 eziceice
commented
5 years ago
eziceice
commented
5 years ago REST API DESIGN
Basic Design Guide
- Identifying the objects which will be presented as resources.
- Idempotent: GET, HEAD, OPTIONS and TRACE methods are defined as safe, meaning they are only intended for retrieving data and should not change a state of a resource on a server.
- Version:
- Custom Header: Adding a custom X-API-VERSION (or any other header of choice) header key by client can be used by a service to route a request to the correct endpoint
- Add version in header Accept.
- Embed the version in the URL such as POST /v2/users
- Pagenation:
- Filter - GET /users/123/posts?state=published
- Search (Multiple Filters) - GET /users/123/posts?state=published&ta=scala
- Sorting - GET /users/123/posts?sort=-updated_at
- Status Code:
- 2xx Success 200 OK: Returned by a successful GET or DELETE operation. PUT or POST can also use this, if the service does not want to return a resource back to the client after creation or modification. 201 Created: Response for a successful resource creation by a POST request.
- 3xx Redirection 304 Not Modified: Used if HTTP caching header is implemented.
- 4xx Client Errors 400 Bad Request: When an HTTP request body can’t be parsed. For example, if an API is expecting a body in a JSON format for a POST request, but the body of the request is malformed. 401 Unauthorized: Authentication is unsuccessful (or credentials have not been provided) while accessing the API. 403 Forbidden: If a user is not Authorized to perform an action although authentication information is correct. 404 Not Found: If the requested resource is not available on the server. 405 Method Not Allowed: If the user is trying to violate an API contract, for example, trying to update a resource by using a POST method.
- 5xx Server Errors These errors occur due to server failures or issues with the underlying infrastructure.
Caching Guide
- Using HTTP headers, an origin server indicates whether a response can be cached and if so, by whom, and for how long. Caches along the response path can take a copy of a response, but only if the caching metadata allows them to do so.
- Optimizing the network using caching improves the overall quality-of-service in following ways
- Reduce bandwidth
- Reduce latency
- Reduce load on servers
- Hide network failures
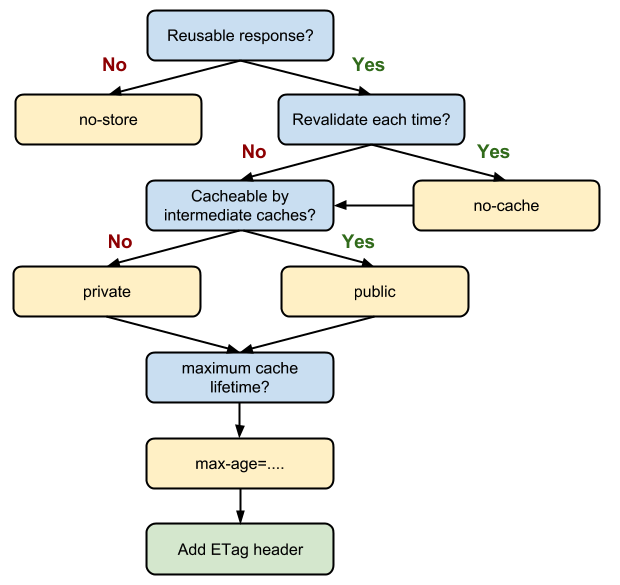
- Related cache headers:
- Expires: The Expires HTTP header specifies an absolute expiry time for a cached representation. Beyond that time, a cached representation is considered stale and must be re-validated with the origin server. To indicate that a representation never expires, a service can include a time up to one year in the future.
- Expires: Fri, 20 May 2016 19:20:49 IST
- Cache-Control: The header value comprises one or more comma-separated directives. These directives determine whether a response is cacheable, and if so, by whom, and for how long e.g.
max-ageors-maxagedirectives.- Cache-Control: max-age=3600, private/public, No-cache/No-store
- No-Cache: User agent has to always ask the server if it's OK to use what it cached.
- No-Store: User agent is not allowed to cache that response.
- Private: Default value. Sets Cache-Control: private to specify that the response is cacheable only on the client and not by shared (proxy server) caches
- Public: Sets Cache-Control: public to specify that the response is cacheable by clients and shared (proxy) caches.
- ETag: An ETag value is an opaque string token that a server associates with a resource to uniquely identify the state of the resource over its lifetime.
- ETag: "abcd1234567n34jv"
- Last-Modified: Whereas a response’s Date header indicates when the response was generated, the Last-Modified header indicates when the associated resource last changed. The Last-Modified value cannot be later than the Date value.
- Last-Modified: Fri, 10 May 2016 09:17:49 IST
- Last-Modified: Fri, 10 May 2016 09:17:49 IST
- Expires: The Expires HTTP header specifies an absolute expiry time for a cached representation. Beyond that time, a cached representation is considered stale and must be re-validated with the origin server. To indicate that a representation never expires, a service can include a time up to one year in the future.
Solid Principale
Single Responsibility Principle
Open Closed Principle
Liskov’s Substitution Principle
Interface Segregation Principle
Dependency Inversion Principle