 NielsRogge
commented
3 years ago
NielsRogge
commented
3 years ago Hi,
looking at this, I would definitely go for option 3 (this is also what's done with models like BERT). Typically, the classification head is trained with the model jointly to get the best performance.
Btw, I have a notebook that illustrates how to easily fine-tune DETR on a custom dataset (balloons): https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb
It's part of my Transformers-tutorials, where I show how to easily fine-tune Transformer-based models on custom data using HuggingFace Transformers. I've added DETR myself to that library, I've implemented both DetrForObjectDetection and DetrForPanopticSegmentation.
❓ How to fine-tune DETR using a small dataset (3k examples)
Hi everyone, I'm using DETR in my master's thesis: it concerns the development of a door recognizer. This is my first experience with transformers, so I would like to share the results I have obtained with my experiments and ask for advice to improve them. Before using my doors' dataset, I'm testing DETR on a public dataset used in other research works. It is called DeepDoors2. It has 3k examples, divided into 3 different types of doors: closed, opened, and semi-opened.
Retrain DETR
I tried to retrain DETR using the default parameters specified in your main.py. I loaded it using the following code:
As you can see, I replaced the class_embed layer and I reduced the object queries to 10. As reported in other issues (#125, #9), retrain DETR using less than 10-15k samples is not recommended. In fact, my results are not good, as shown by the following figure.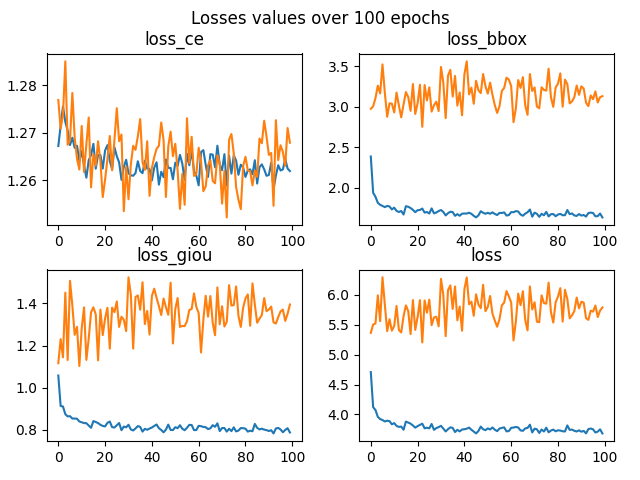
Fine-tune class_embed and box_embed
In the next experiment, I have fine-tuned only the layers that return the predicted labels and the bounding boxes. I created the model using the following code:
The obtained results are better than the previous ones, as shown by the figure.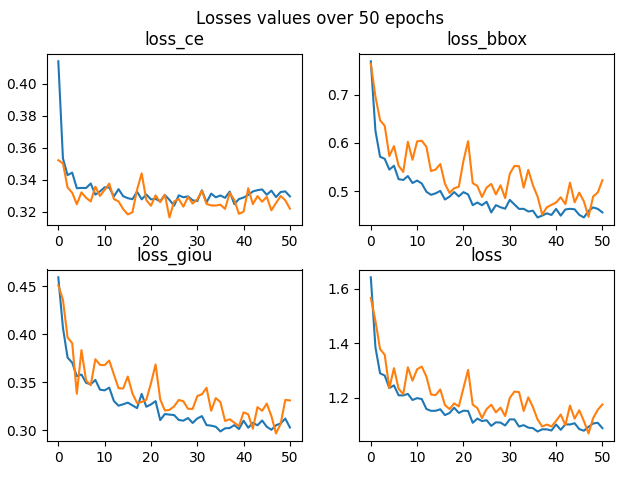
However, the model does not seem to learn more and the bounding boxes found are not good.
Fine-tune the entire trained model (work in progress)
The last experiment concerns the fine-tuning of the entire trained model. The experiment is in progress, I will publish the results soon. I loaded the model using the following code:
I have changed the following parameters:
Questions
1) In the first two experiments, could there be some error? Are their results plausible? 2) The last experiment is the promising one, as reported in #125. Are the parameters I have set correct? Would you have any other suggestions to obtain better results?
NB: I performed all the experiments applying the same data augmentation of DETR (crop, resize, flip ecc) and with a batch size of 1.
Thank you so much in advance for any suggestions.