 woctezuma
commented
2 years ago
woctezuma
commented
2 years ago It is kind of a shot in the dark as I don't have access to several GPUs. However, maybe this would help so I am posting it below.
You can see at the lines below that the learning rate is scaled with respect to batch size and "world size": https://github.com/facebookresearch/xcit/blob/82f5291f412604970c39a912586e008ec009cdca/main.py#L309-L310
I wonder if the world size is the number of GPUs. If true, maybe try to lower the learning rate or the batch size, so that the linearly scaled learning rate is lower.
Personally, I would check the value returned by world size with the debugger, and then try to lower the learning rate args.lr, maybe divide it by 2 (or 4 since you have 4 GPU). Moreover, I think it makes sense if the training is unstable.
 felix-do-wizardry
felix-do-wizardry aelnouby
aelnouby
Hi, I'm trying to reproduce the classification training results.
I tried on 2 different machines, machine A with one RTX 3090 and machine B with four A100 gpus.
The training on machine A with a single GPU is fine; see green line (with default parameters). But on machine B with 4 gpus, it's not training properly and very erratic; see gray, yellow, teal lines (with default and custom parameters). Purple line is DeiT training on the same machine B (default parameters).
All experiments done with --batch-size=128 (128 samples per gpu).
This is validation loss, other metrics tell the same story, some even worse.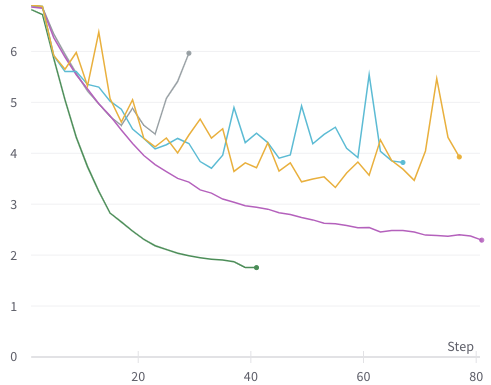
Example of the commands I used:
Anyone's seen this or know how to fix it? Many thanks.