 hosseinfani
commented
2 years ago
hosseinfani
commented
2 years ago Hi @ZahraTaherikhonakdar what's the differences with fani-lab/ReQue#10 ? Why the results of hred-qs are different?
Open ZahraTaherikhonakdar opened 2 years ago
hosseinfani
commented
2 years ago Hi @ZahraTaherikhonakdar what's the differences with fani-lab/ReQue#10 ? Why the results of hred-qs are different?
 ZahraTaherikhonakdar
commented
2 years ago
ZahraTaherikhonakdar
commented
2 years ago hred-qs
As you know the authors of the fani-lab/ReQue#10 and this paper are the same. In this paper, they introduce the framework to jointly learn document ranking and query suggestion and in fani-lab/ReQue#10 they used this framework in the neural model to jointly document ranking and query suggestion.
By difference, you mean why the hred-qs results are so close to this paper's results? if so, as the paper said, hred-qs is so closed to this paper. hred-qs use a hierarchical recurrent encoder-decoder approach by considering session information for context-aware query suggestion(only for suggest queries). This paper follows this approach to jointly rank documents and suggest queries.
hosseinfani
commented
2 years ago @ZahraTaherikhonakdar any updates?
ZahraTaherikhonakdar
commented
2 years ago @ZahraTaherikhonakdar any updates?
In fani-lab/ReQue#10 they improved their previous work by learning dependency between users' queries and clicked in a session. They also compare models in fani-lab/ReQue#10 with fani-lab/ReQue#5. Here are the results that show the improvement:
| Model | MAP | MRR | NDCG (@1) | NDCG(@3) | NDCG(@10) |
|---|---|---|---|---|---|
| M-Match Tensor fani-lab/ReQue#5 | 0.505 | 0.518 | 0.368 | 0.491 | 0.567 |
| CARS fani-lab/ReQue#10 | 0.531 | 0.542 | 0.391 | 0.517 | 0.596 |
ZahraTaherikhonakdar
commented
2 years ago @hosseinfani, as our today's meeting is canceled I describe the novelty of fani-lab/ReQue#10 here. Otherwise, I wanted to explain it in the meeting.
The fani-lab/ReQue#10 pays attention to dependency between issued query and clicked documents in a search task (search session). They apply a mechanism to detect the dependency in a user's past behavior in the same search task. Then, they use the dependency structure as a shared metric (M_shared) in their proposed query suggestion and document ranking component (C_q, C_r) along with queries and documents which considered effective in predicting the next query and rank documents in a session (E_q , E_d) in each related component. To formulate these components (these component are sub-compnent for joint-learning component) : C_q= M_shared + E_q C_r= M_shared + E_d They claim that identifying the dependency structure between query and click sequence in a search task would result in increasing query suggestion and document ranking performance.
Another difference is that fani-lab/ReQue#10 defines a session based on a task. In other words, a session is considered as a sum of all issued queries and clicked documents in search history based on a specific task ( for example, job searching). But, fani-lab/ReQue#5 consider a session as 30-minutes inactivity.
hosseinfani
commented
2 years ago @ZahraTaherikhonakdar as requested, your progress update should be available by Thursday midnight. We can discuss it in our next meeting.
Main Problem: This paper proposed a multi-task learning framework to learn both document ranking and query suggestion. They used users' search log information like clicked documents and sequence of initial queries in one session. They believed that these two tasks have a positive effect on each other and proved it by comparing the performance of their proposed method with the previous document ranking and query suggestion methods.
Input-Output:
phase: Input: input query+sequence of query in a session(from search log)+candidate documents(from search log) Output: predicting documents ranking and query suggestion
Previous Works and their Gaps: Previous query suggestion and documents ranking methods only consider the sequence of queries for query suggestion or clicked documents for document ranking. This paper claimed that by jointly learning query suggestions and documents ranking the performance would increase. Because search behavior like clicked documents and search intent capturing from a sequence of queries in session could have a positive effect on these two tasks.
Result: The proposed method significantly improved compared to previous query suggestions and document raking methods. Document ranking performance :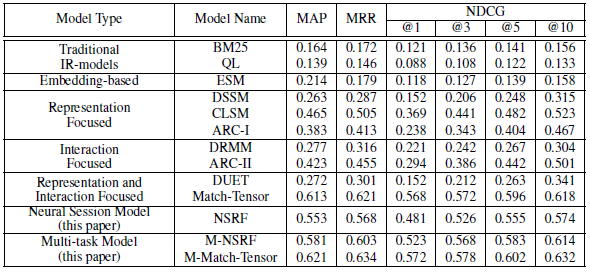 Query suggestion performance:
Query suggestion performance:
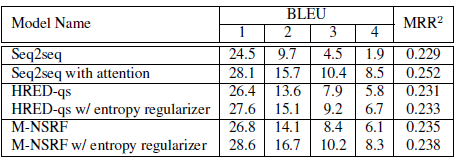
Data Set: They used AOL dataset.
Gap of this work: This paper used shallow information for training the model. More useful information can be used in training the model to capture users interest and intent in web search and rank documents based on user's behavior. Social information along with search logs can be useful to understand users' intent and improve the qury suggestion and documents ranking tasks. Code: https://github.com/wasiahmad/context_attentive_ir