 faroit
commented
5 years ago
faroit
commented
5 years ago ha thats a nice idea. Yes its certainly interesting.
Can you show the plot here?
Would it make sense to add torch and tensorflow?
Closed hagenw closed 5 years ago
faroit
commented
5 years ago ha thats a nice idea. Yes its certainly interesting.
Can you show the plot here?
Would it make sense to add torch and tensorflow?
 hagenw
commented
5 years ago
hagenw
commented
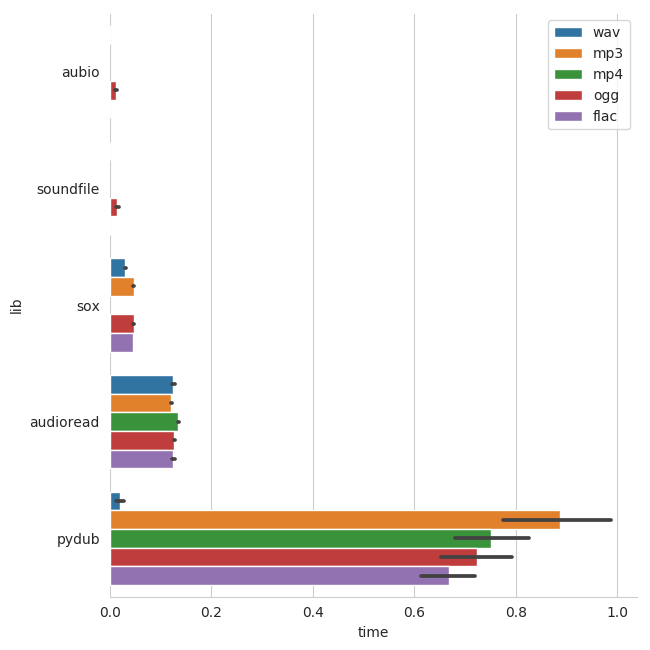
5 years ago The plot is part of this commit:
hagenw
commented
5 years ago But it might be better, to rerun everything in the docker container, otherwise the time axis of this (metadata) plot is not comparable to the time axis of the three other plots.
hagenw
commented
5 years ago As you asked to integrate torch or tensorflow. Do they provide functions to gather metadata from audio before loading the file?
faroit
commented
5 years ago torchaudio has torchaudio.info(filepath). Tensorflow (neither 1.x nor 2.0) will have something to load the metadata before loading the file.
hagenw
commented
5 years ago I tested torchaudio.info which seems to be fast, but also has a problem as it simply segfaults for non supported file type. This you cannot handle with a try-catch statement in Python, but you have to check for the file extension before.
For a better comparison, we might also think about removing pydub from the comparison as it is unacceptable slow.
With those changes the output looks like this:

Please say if you would like to stay with pydub or not and I will update this branch.
faroit
commented
5 years ago Please say if you would like to stay with pydub or not and I will update this branch.
No I think you are right. Maybe add a note, that you omitted pydub because its too slow. I will merge then.
hagenw
commented
5 years ago I updated all files accordingly and added the missing benchmark_metadata.py file.
This should now be ready to merge.
faroit
commented
5 years ago Great, Thanks!
This adds a benchmark for extracting the following metadata from audio files:
All of that information can of course be calculated as soon as the file is loaded, but for some operations it might be interesting to look it up before.
It's totally fine, if you think this is not fitting into the purpose of this repository. Then just close this PR. Otherwise feel free to ask for changes or the inclusion of further frameworks besides
audio,soundfile,sox,audioread, andpydub.NOTE: for
audbioandsoundfilethe results for WAV and FLAC files are too small to see a bar in the plot.Maybe we should also think about adding a test that the returned results are correct as well as in my experience they can differ, especially for duration and number of samples.