 faroit
commented
5 years ago
faroit
commented
5 years ago Thanks, I will re-ran the benchmark asap. Can't wait to have a fast audio loading in librosa 👍
As an aside, we always had API support for excerpts and seeking. It wasn't terribly efficient because audioread didn't support that universally, but it should be almost no overhead relative to soundfile now.
I just updated the table, I oversaw the seek support.
 bmcfee
bmcfee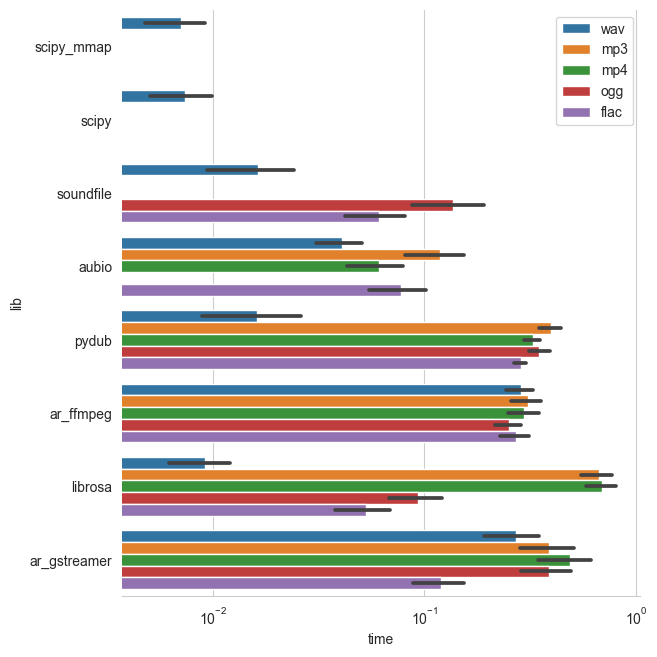
Leaving a marker here that the benchmarks should rerun on librosa 0.7.0 (and probably include version numbers more generally).
Quick summary of changes:
As an aside, we always had API support for excerpts and seeking. It wasn't terribly efficient because audioread didn't support that universally, but it should be almost no overhead relative to soundfile now. The only additional overhead would be downmixing or resample-on-load, but those shouldn't be included in the benchmarks anyway.