 nfplay
commented
4 years ago
nfplay
commented
4 years ago Hi,
I see that feature serving presupposes the download of data to a staging location. Is this by design? How does this scale to terabyte and petabyte scale? Shouldn't training be allowed directly over the batch store?
Thank you! NF
 woop
woop ches
ches groodt
groodt Yanson
Yanson Jeffwan
Jeffwan dr3s
dr3s kennydataml
kennydataml SHARANTANGEDA
SHARANTANGEDA stale[bot]
stale[bot]
1. Introduction
We've had a lot of demand for either open source or AWS batch stores (#367, #259). Folks from the community have asked us how they can contribute code to add their stores types.
In this issue I will walk through how batch stores are currently being used and how a new batch store type can be added.
2. Overview
Feast interacts with a batch store in two places
3. Data ingestion
Feast creates and manages population jobs that stream in data from upstream data sources. Currently Feast only supports Kafka as a data source, meaning these jobs are all long running. Batch ingestion pushes data to Kafka topics after which they are picked up by these "population" jobs.
In order for the ingestion + population flow to complete, the destination store must be writable. This means that Feast must be able to create the appropriate tables/schemas in the store and also write data from the population job into the store.
Currently Feast Core starts and manages these population jobs that ingest data into stores, although we are planning to move this responsibility to the serving layer. Feast Core starts an Apache Beam job which synchronously runs migrations on the destination store and subsequently starts consuming from Kafka and publishing records.
Below is a "happy-path" example of a batch ingestion process: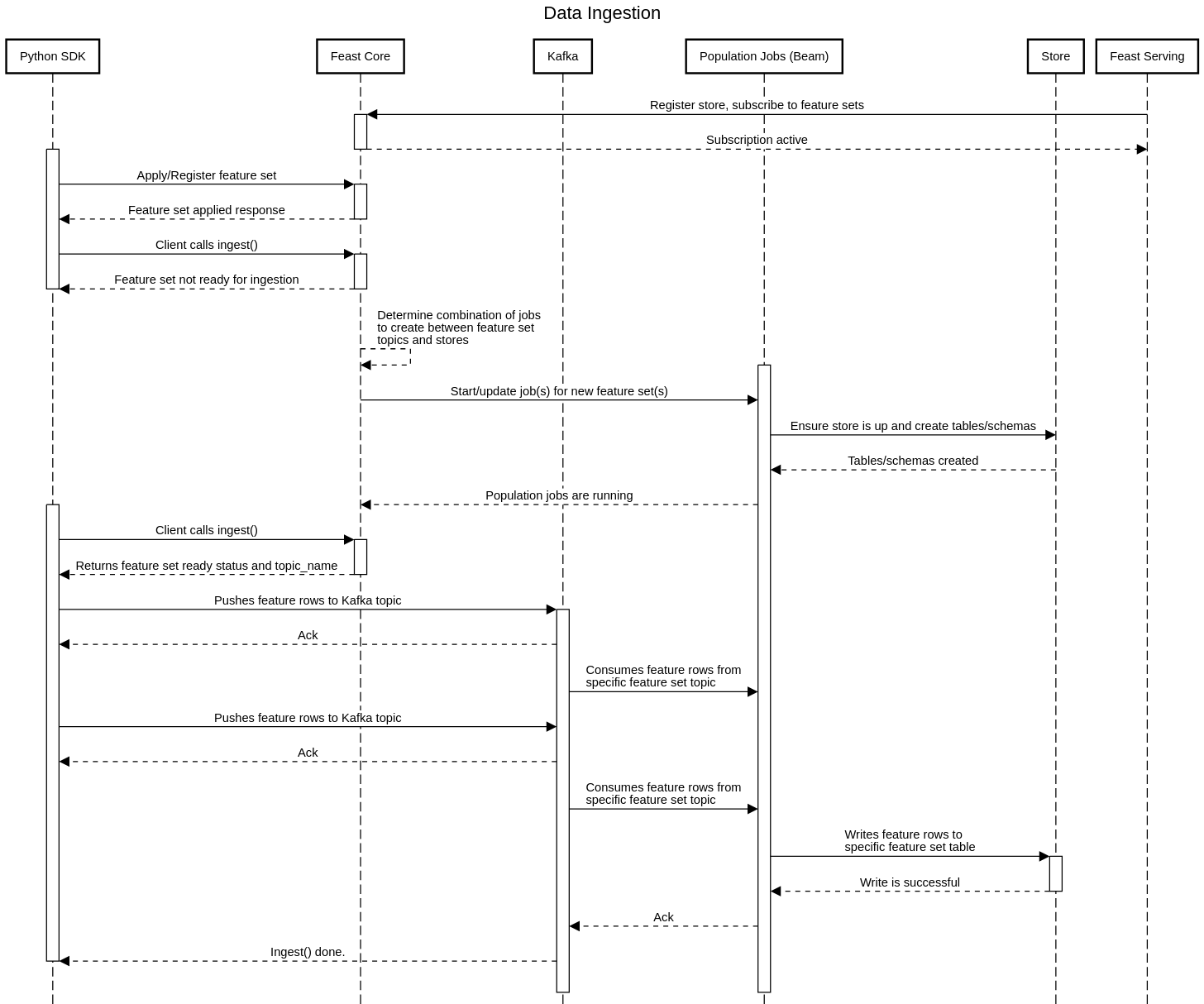
In order to accommodate a new store type, the Apache Beam job needs to be updated to support
4. Feature serving (batch)
Feast Serving is a web service that allows for the retrieval of feature data from a batch feature store. Below is a sequence diagram for a typical feature request from a batch store.
Currently we only have support for BigQuery has a batch store. The entry point for this implementation is the BigQueryServingService, which extends the ServingService interface.
The ServingService is called from the wrapping gRPC service ServingService, where the functionality is more clearly described.
The interface defines the following methods
Notes on the current design: Although the actual functionality will be retained, the structure of these interfaces will probably change away from extending a
serviceinterface and towards having astoreinterface. There are various problems with the current implementation