 christianrickert
commented
3 years ago
christianrickert
commented
3 years ago I've done some troubleshooting. My current working hypothesis is that the Gabor training feature is not compatible with stack training for single image classification. As before, I've trained on the large stack with the same training features - excluding Gabor!
Here's the probability map for the first image of the stack:

And here's the probability map for the same image extracted from the stack:

The probability maps are identical. Here's the difference (all pixels have a value of 0.0):

IMHO a word of warning might be helpful for users using reading the Trainable Weka Segmentation Plugin documentation: In particular, the section describing the Trainable Weka Segmentation Training features (2D) could include a sentence highlighting the stack issue.
Is this issue known or even by design? I'm not experienced enough with the feature implementation...
 iarganda
iarganda imagesc-bot
imagesc-bot
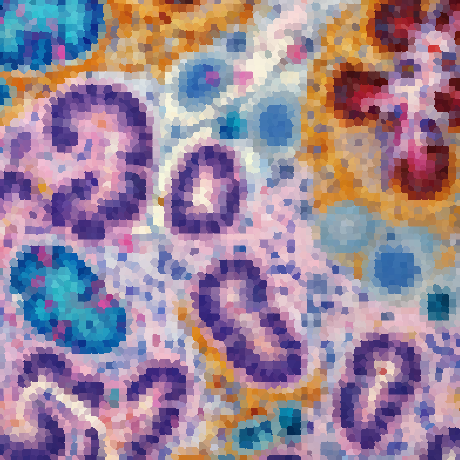
Hello, there's something curious about the transfer of my classification model from a training stack to my experimental dataset: The probability map for the stack looks fine, but the probability map for a single image from the same stack looks different - using the same model for classification.
@iarganda suggested in a response to another issue to train on either a stack or on a sequence of images (for multiple images). I've trained on a stack with 30 images depicting nuclei - using fairly computationally expensive features.
Here's the probability map for the first image of the stack:
And here's the probability map for the same image extracted from the stack:
The segmentation results for both images differ significantly, even though the same classification model has been used.
The macro below will create the probability maps for the training stack and then duplicate the first stack image and create the probability map with the same model for comparison: it takes roughly 25 min on my system with a peak memory usage of about 13.5 GB.
The files required for reproduction of the issue can be downloaded here: example.zip (MD5: EA367E1226010A1E14B3A1570DA2DD5F)
As a consequence, I can't train on a larger dataset to improve the segmentation results.
Any idea what went wrong with my approach or what I could do to prevent this issue in the future?