 jangdelong
commented
4 years ago
jangdelong
commented
4 years ago http协议
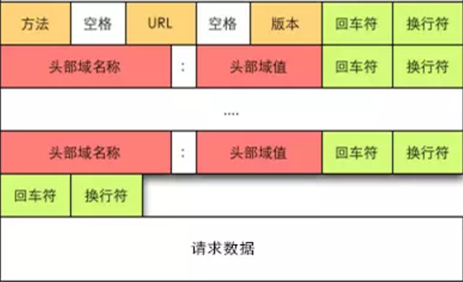
请求报文和响应报文都是由以下4部分组成
- 请求行
- 请求头
- 空行
- 消息主体
下图为http请求的报文结构
下图为http响应报文结构

请求行
格式为:
Method Request-URI HTTP-Version 结尾符
结尾符一般用\r\n
请求头
通用报头
既可以出现在请求报头,也可以出现在响应报头中
Date:表示消息产生的日期和时间
Connection:允许发送指定连接的选项,例如指定连接是连续的,或者指定“close”选项,通知服务器,在响应完成后,关闭连接
Cache-Control:用于指定缓存指令,缓存指令是单向的(响应中出现的缓存指令在请求中未必会出现),且是独立的(一个消息的缓存指令不会影响另一个消息处理的缓存机制)
请求报头
请求报头通知服务器关于客户端求求的信息,典型的请求头有:
Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机
User-Agent:发送请求的浏览器类型、操作系统等信息
Accept:客户端可识别的内容类型列表,用于指定客户端接收那些类型的信息
Accept-Encoding:客户端可识别的数据编码
Accept-Language:表示浏览器所支持的语言类型
Connection:允许客户端和服务器指定与请求/响应连接有关的选项,例如这是为Keep-Alive则表示保持连接。
Transfer-Encoding:告知接收端为了保证报文的可靠传输,对报文采用了什么编码方式。
响应报头
用于服务器传递自身信息的响应,常见的响应报头:
Location:用于重定向接受者到一个新的位置,常用在更换域名的时候
Server:包含可服务器用来处理请求的系统信息,与User-Agent请求报头是相对应的
实体报头
实体报头用来定于被传送资源的信息,既可以用于请求也可用于响应。请求和响应消息都可以传送一个实体,常见的实体报头为:
Content-Type:发送给接收者的实体正文的媒体类型
Content-Lenght:实体正文的长度
Content-Language:描述资源所用的自然语言,没有设置则该选项则认为实体内容将提供给所有的语言阅读
Content-Encoding:实体报头被用作媒体类型的修饰符,它的值指示了已经被应用到实体正文的附加内容的编码,因而要获得Content-Type报头域中所引用的媒体类型,必须采用相应的解码机制。
Last-Modified:实体报头用于指示资源的最后修改日期和时间
Expires:实体报头给出响应过期的日期和时间
空行
http协议规定的格式,一般采用\r\n
消息主体
一般用于http的post method。通过实体报头规定消息主体的格式内容、
例如 Content-Type=text/plain
该实体报头规定了消息主体的数据是纯文本格式
常见的还有
Content-Type=application/x-www-form-urlencoded,定义为Key=value格式
Content-Type=application/json,定义为序列化为的json字符串
Content-Type= multipart/form-data,定义为表单数据提交,该格式比较复杂,详细解释一下。
multipart/form-data
-
该格式是post的常见提交方式,也就是说是由post方法来组合实现的
-
使用该提交方法需要规定一个内容分割符用于分割请求体中的多个post的内容,如文件内容和文本内容自然需要分割开来,不然接收方就无法正常解析和还原这个文件了。具体的头信息如下:
Content-Type: multipart/form-data; boundary=${bound}
其中${bound}是自定义的分隔符,一般情况用一长串不会和业务数据重复的字符串表示 ,例如9431149156168
-
分割符前面需要加上--
-
最后的分割符后面也需要加上—
-
所有的数据请求头和数据之间都用\r\n\r\n分开,两个数据间用 --${bound}\r\n分开


前端事件流
事件流程如下:
捕获阶段:事件从根元素开始向触发事件的目标元素进行传递,传递过程中,如果中间有元素注册了事件处理函数,并且 useCapture 参数值为 true ,那么此事件处理函数就会执行,IE9+和其他标准浏览器支持。
目标阶段:触发目标元素对应事件,并执行注册的事件处理函数。
冒泡阶段:从目标元素开始向根元素传递,传递过程中,如果中间有元素注册了事件处理函数,且 useCapture 值为 false,此事件处理函数就会执行。
什么是闭包?这就是闭包!
有权访问另一个函数作用域内变量的函数都是闭包。
HTTP缓存机制和原理
强制缓存
(1) Expires
Expires 的值为服务端返回的到期时间,即下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。
不过 Expires 是HTTP 1.0的东西,现在默认浏览器均默认使用 HTTP 1.1,所以它的作用基本忽略。
另一个问题是,到期时间是由服务端生成的,但是客户端时间可能跟服务端时间有误差,这就会导致缓存命中的误差。
所以HTTP 1.1 的版本,使用Cache-Control替代。
(2) Cache-Control
Cache-Control 是最重要的规则。常见的取值有 private、public、no-cache、max-age,no-store,默认为 private。
对比缓存
(1) Last-Modified / If-Modified-Since
服务器在响应请求时,告诉浏览器资源的最后修改时间。
再次请求服务器时,通过此字段通知服务器上次请求时,服务器返回的资源最后修改时间。 服务器收到请求后发现有头 If-Modified-Since 则与被请求资源的最后修改时间进行比对。 若资源的最后修改时间大于 If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码 200;
若资源的最后修改时间小于或等于 If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。
(2) Etag / If-None-Match (优先级高于Last-Modified / If-Modified-Since)
服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。
再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。
服务器收到请求后发现有头 If-None-Match 则与被请求资源的唯一标识进行比对, 不同,说明资源又被改动过,则响应整片资源内容,返回状态码 200;
相同,说明资源无新修改,则响应 HTTP 304,告知浏览器继续使用所保存的 cache。
defer 和 async
1、defer
如果 script 标签设置了该属性,则浏览器会异步的下载该文件并且不会影响到后续 DOM 的渲染;
如果有多个设置了 defer 的 script 标签存在,则会按照顺序执行所有的 script;
defer 脚本会在文档渲染完毕后,DOMContentLoaded 事件调用前执行。
2、async
async 的设置,会使得 script 脚本异步的加载并在允许的情况下执行; async 的执行,并不会按着 script 在页面中的顺序来执行,而是谁先加载完谁执行。
使用 js 的 FileReader对象实现上传图片时的图片预览功能
废话不多说线上代码
HTTPS 验证原理
https 在真正请求数据前,先会与服务有几次握手验证,以证明相互的身份,以下图为例
性能优化
CSS的回流与重绘
说到页面为什么会慢?那是因为浏览器要花时间、花精力去渲染,尤其是当它发现某个部分发生了点变化影响了布局,需要倒回去重新渲染, 该过程称为reflow(回流)。
reflow 几乎是无法避免的。现在界面上流行的一些效果,比如树状目录的折叠、展开(实质上是元素的显 示与隐藏)等,都将引起浏览器的 reflow。鼠标滑过、点击……只要这些行为引起了页面上某些元素的占位面积、定位方式、边距等属性的变化,都会引起它内部、周围甚至整个页面的重新渲 染。通常我们都无法预估浏览器到底会 reflow 哪一部分的代码,它们都彼此相互影响着。
如果只是改变某个元素的背景色、文 字颜色、边框颜色等等不影响它周围或内部布局的属性,将只会引起浏览器 repaint(重绘)。
repaint 的速度明显快于 reflow(在IE下需要换一下说法,reflow 要比 repaint 更缓慢)。
对称加密及非对称加密
发送方和接收方需要持有同一把密钥,发送消息和接收消息均使用该密钥。
相对于非对称加密,对称加密具有更高的加解密速度,但双方都需要事先知道密钥,密钥在传输过程中可能会被窃取,因此安全性没有非对称加密高。
接收方在发送消息前需要事先生成公钥和私钥,然后将公钥发送给发送方。发送放收到公钥后,将待发送数据用公钥加密,发送给接收方。接收到收到数据后,用私钥解密。 在这个过程中,公钥负责加密,私钥负责解密,数据在传输过程中即使被截获,攻击者由于没有私钥,因此也无法破解。
非对称加密算法的加解密速度低于对称加密算法,但是安全性更高。
---- 以下更新于 2018-12-11 ----
link 和 @import 区别
@import是 CSS 提供的语法规则,只有导入样式表的作用;link是HTML提供的标签,不仅可以加载 CSS 文件,还可以定义 RSS、rel 连接属性等。
加载页面时,link标签引入的 CSS 被同时加载;@import引入的 CSS 将在页面加载完毕后被加载。
@import是 CSS2.1 才有的语法,故只可在 IE5+ 才能识别;link标签作为 HTML 元素,不存在兼容性问题。
可以通过 JS 操作 DOM ,插入link标签来改变样式;由于 DOM 方法是基于文档的,无法使用@import的方式插入样式。
CSS 权重优先级顺序
!important > 行内样式 > ID > 类、伪类、属性 > 标签名 > 继承 > 通配符
观察者模式
两大数相加
设备像素比
物理像素(physical pixel)
一个物理像素是显示器(手机屏幕)上最小的物理显示单元,在操作系统的调度下,每一个设备像素都有自己的颜色值和亮度值。
设备独立像素(density-independent pixel)
设备独立像素(也叫密度无关像素),可以认为是计算机坐标系统中得一个点,这个点代表一个可以由程序使用的虚拟像素(比如: css像素),然后由相关系统转换为物理像素。 所以说,物理像素和设备独立像素之间存在着一定的对应关系,这就是接下来要说的设备像素比。
设备像素比(device pixel ratio )
设备像素比(简称dpr)定义了物理像素和设备独立像素的对应关系,它的值可以按如下的公式的得到:
---- 以下更新于 2018-12-13 ----
双向绑定原理(简单思路)
实现一个监听器Observer,用来劫持并监听所有属性,如果有变动的,就通知订阅者。
实现一个订阅者Watcher,每一个Watcher都绑定一个更新函数,watcher可以收到属性的变化通知并执行相应的函数,从而更新视图。
实现一个解析器Compile,可以扫描和解析每个节点的相关指令(v-model,v-on等指令),如果节点存在v-model,v-on等指令,则解析器Compile初始化这类节点的模板数据,使之可以显示在视图上,然后初始化相应的订阅者(Watcher)。
---- 以下更新于 2019-2-12 ----
面向对象的三个基本特征
---- 以下更新于 2019-2-24 ----
JS继承 · 类
ES5 和 ES6 子类
this生成顺序不同。ES5 的继承先生成了子类实例,再调用父类的构造函数修饰子类实例,ES6 的继承先生成父类实例,再调用子类的构造函数修饰父类实例。这个差别使得 ES6 可以继承内置对象。ES5/ES6 的继承除了写法以外还有什么区别?
1、
class声明会提升,但不会初始化赋值。Foo进入暂时性死区,类似于let、const声明变量。2、
class声明内部会启用严格模式。3、
class的所有方法(包括静态方法和实例方法)都是不可枚举的。4、
class的所有方法(包括静态方法和实例方法)都没有原型对象 prototype,所以也没有[[construct]],不能使用new来调用。5、必须使用
new调用class。6、
class内部无法重写类名。Vue 组件的 data 必须是一个函数
一个组件的
data选项必须是一个函数,因此每个实例可以维护一份被返回对象的独立的拷贝。如果 Vue 没有这条规则,点击某个按钮组件就可能影响到其它实例。
防抖及节流
防抖
节流