 FedeDP
commented
7 years ago
FedeDP
commented
7 years ago @ctrlcctrlv Can you please try now? For both #15 and #16.
Open ctrlcctrlv opened 7 years ago
FedeDP
commented
7 years ago @ctrlcctrlv Can you please try now? For both #15 and #16.
 ctrlcctrlv
commented
7 years ago
ctrlcctrlv
commented
7 years ago Unfortunately - this issue is still alive and well. Now that #14 is fixed and I can scroll further back in my chat history, I can find even worse-looking examples of it.

This text should look like
You just summoned a Ruthless Angel. あなたは残酷な天使を召喚しました。
Your IP address is
I am a Ruthless Angel.
私は、残酷な天使。
ERROR! Your post is too excessive.
エラー! あなたの投稿は過剰すぎます。
I am regulated you.
私はあなたを規制しました。
So you will not be able to write for a while.
なので(従って)、あなたはしばらく書き込めません。If you want to reproduce this, simply go to ja.wikipedia.org, copy some text and post it into a Slack room. Then look at it in slack++.
At my company, half of my coworkers are Japanese and we manage 2channel - so bad Unicode support is readily apparent in every channel. :(
ctrlcctrlv
commented
7 years ago We need to change the session interface to accept std::wstring instead of std::string, and use std::wstring everywhere until the very last step of inserting into the ncurses window. We will then convert it from wchar_t (std::wstring) to char* for ncurses....
ctrlcctrlv
commented
7 years ago ctrlcctrlv
commented
7 years ago Is it OK for us to use iconv? It's a new dependency, but it's a very common one - most Linux/BSD distros should have it, if not as a header than at least as a shared object.
If we can use iconv I can probably fix this easily...but trying to do it with the standard libraries only is a pain and every solution I can find will break compilation on Windows.
ctrlcctrlv
commented
7 years ago Or how about this library? https://github.com/nemtrif/utfcpp
This would make it so we don't have to use a lot of C stuff which could give us more memory problems.
ctrlcctrlv
commented
7 years ago I have a patch for you that requires no external libraries other than C++14, but it has one problem I'm waiting for advice from SO on before opening a PR.
FedeDP
commented
7 years ago You can use iconv if you wish; utfcpp seems too hard to find for some distro (i am on archlinux and it does not exist in both repo and aur).
By the way yeah std::wstring is surely the answer here. I was sure that std::string already handled wide chars and i did not even check on doc... I don't understand your SO question: are you looking for a function that tells you how many chars is wide? There is already a handy function: https://linux.die.net/man/3/wcsnlen . You can use this function when splitting new messages/history messages, and bound them to number of cols available :)
ctrlcctrlv
commented
7 years ago If you're planning on a more thorough fix to also allow resizing the window (i.e. deprecating the SlackUI::add_message and SlackUI::add_history functions) I won't continue working on my commit which would just fix those functions.
My SO question was about how we can know how many columns a character takes. A CJK character always (to my knowledge) takes two columns, which means that even if we avoid the problem we have right now where we're splitting UTF-8 strings at the wrong place, we can still end up with strings that don't fit in the window because the characters are physically too "wide' to fit in one column.
This project right here is great and would be simple to translate into C++ : https://github.com/jquast/wcwidth/blob/master/wcwidth/wcwidth.py
The reason we don't want to use the system wcwidth is because it is often incorrect, either because it doesn't know about the latest Unicode standard or because of the user's locale.
FedeDP
commented
7 years ago I'll try later with wcsnlen (maybe on a new branch), then i'll wait for your verdict :) If wcsnlen is enough to fix the issue, for now i'll merge it. Then I/we (if you are still willing to help it is much appreciated!) will try to fix the root issue with a new Chat messages structure.
ctrlcctrlv
commented
7 years ago Alright 👍 I agree that we should have a new Chat messages structure, but I need more time to think about what that should look like :)
FedeDP
commented
7 years ago For any suggestion/question feel free to ask me! I will have more time next week (from 30th october) probably as i'll be on leave, so i hope to sort that out during that period!
FedeDP
commented
7 years ago If you prepared a PR with std::wstring instead of std::string, i think that alone can be a solution, isn't it? I mean, std::wstring methods (eg length or substring) should be aware of multibytes chars. I followed your SO question; if you went on with your wchar implementation for the PR, did it fixed the issue for you?
ctrlcctrlv
commented
7 years ago No, it won't be enough because some "wide" characters (in terms of bytes) are not also "wide" (in terms of their actual graphical representation). I already converted back and forth between std::u32string in an unreleased patch and it only solved the visual glitches in the weak case (all wide chars are physically narrow) but did not help the strong case (some wide chars require two or more columns).
ctrlcctrlv
commented
7 years ago We're dealing with a monospaced grid here so if some multibyte characters require 2 columns and others 1, if our program is not aware of this we still get overflows into the UI. Wait, I'll boot up the machine I'm using to develop this and show you.
ctrlcctrlv
commented
7 years ago OK. Here's my patch which solves the weak case.
index 9aace87..3198be4 100644
--- a/src/SlackUI.cpp
+++ b/src/SlackUI.cpp
@@ -1,5 +1,7 @@
#include "SlackUI.hpp"
+std::wstring_convert<std::codecvt_utf8<char32_t>, char32_t> u32conv;
+
static bool quit = false;
void SlackUI::set_client(SlackClient* client) {
@@ -235,9 +237,12 @@ void SlackUI::add_message(const RosterItem& item,
const std::string &channel) {
int j = 0;
bool check = false;
+ std::u32string c = u32conv.from_bytes(content);
do {
- sessions[channel].add_message(item, content.substr(j, chat->get_real_cols()), sender);
+ std::u32string substr = c.substr(j, chat->get_real_cols());
+ std::string substr8 = u32conv.to_bytes(substr);
+ sessions[channel].add_message(item, substr8, sender);
j += chat->get_real_cols();
if (sessions[channel].messages.size() > chat->get_real_rows()) {
sessions[channel].delta++;
@@ -247,7 +252,7 @@ void SlackUI::add_message(const RosterItem& item,
chat->draw_next(sessions[channel]);
check = true;
}
- } while (j < content.length());
+ } while (j < c.length());
if (!check) {
/* Whether we are printing new sender (no libnotify notification needed) */
@@ -271,10 +276,13 @@ void SlackUI::add_history(const RosterItem& item,
const std::string& content,
bool sender,
const std::string &channel) {
- int j = content.length();
+ std::u32string c = u32conv.from_bytes(content);
+ int j = c.length();
int length = j % chat->get_real_cols();
do {
- sessions[channel].add_history(item, content.substr(j - length, length), sender);
+ std::u32string substr = c.substr(j - length, length);
+ std::string substr8 = u32conv.to_bytes(substr);
+ sessions[channel].add_history(item, substr8, sender);
if (sessions[channel].messages.size() > chat->get_real_rows()) {
sessions[channel].delta++;
}The character U+2014 is physically narrow (takes 1 grid column to display correctly), so my original example now displays correctly.

However, the Japanese characters are physically wide, so each character requires two grid spaces. This is still broken because a correct UTF-32 length does not take into account their physical widths as displayed on the screen.

That's why we must use wcwidth, wcswidth, or an alternative to them such as using a temporary window.
ctrlcctrlv
commented
7 years ago WeeChat uses wcswidth: https://github.com/weechat/weechat/blob/master/src/core/wee-utf8.c#L521
ctrlcctrlv
commented
7 years ago I've discovered that there is an alternative, but it requires changing the way that the UI works. We could make #13 mandatory - no more borders - and either permanently hide the list of channels, move the list of channels into its own full screen window (on pressing tab), or put the list of channels on the top or bottom. Then we could allow the terminal to flow the text when it meets the edge of the window instead of us having to flow it. But if we want to have UI elements on the sides, this is impossible, and we must use wcswidth (measured against std::u32strings so we can support Emoji) or the temporary unseen window hack.
FedeDP
commented
7 years ago Yes I already thought about this solution and it would be the best in terms of delivering correct results AND needing really small work for us. But these borders are required unfortunately. Moreover, how can we know when we need to scroll our Window? We should add some sort of "hack" (eg: checking first column of each line to understand when we need to scroll) or printing every time full content starting from the bottom (again, when should we stop though? And where to start printing?) Finally, how can we know how to scroll up exactly one line in the history?
The best solution is to use wcswidth i guess, or to come up with a solution for these problems(we can use single line windows as borders, so we have a fake borderless Window; still a solution for other issues has to be found).
FedeDP
commented
7 years ago By the way gnu libc 2.26 has unicode 10.0.0 support as stated in release note, with changes specifically to wcwidth. Again, this seems to be the best choice, in my opinion at least.
ctrlcctrlv
commented
7 years ago Yeah the guy on SO was all like "you shouldn't use wcwidth because it can be out of date" or "wrong" on certain dead platforms. (Solaris? who cares? :joy: )
If we don't have to reinvent the wheel and include our own wcwidth...that's for the better.
FedeDP
commented
7 years ago Yeah :grinning: Obviously we should still improve message structure to accomplish #13. But that can be surely done later. I'm routing for a fix for this + emoji support, then maybe advertise slack++ a little bit on reddit/hackernews hoping to find new people interested (with new ideas and new PR). This way this can grow faster and cover more Slack features. What do you think?
ctrlcctrlv
commented
7 years ago I think it's a good idea to get this issue fixed first because surely other people will notice it...I for one did not find this project due to any publicity, I just was searching the web for a terminal client because I found Slack's IRC integration lacking...my ultimate goal with this project is to run the terminal client alongside WeeChat in tmux so I don't have to use the bloated web interface which kills my CPU on weaker hardware ...
FedeDP
commented
7 years ago Obviously that was the goal of this project. But when i changed job i stopped using Slack, so this project freezed :)
FedeDP
commented
7 years ago @ctrlcctrlv i could not find the time to get around this unfortunately, and i won't find it anytime soon. Just to let you know that i'm still willing to fix this as soon as i got some spare time(or i can merge any PR too ) but i cannot give any timing.
ctrlcctrlv
commented
6 years ago Hey:
Sorry I hadn't been able to get back to you until now. I wrote a library in Rust at my job that would easily solve this problem as part of a proprietary console application at my work:
https://github.com/ctrlcctrlv/justify
It is pretty easy to use Rust libraries in C++, so wonder what you think about this...I could potentially write the needed code to integrate it if you would approve using it.
FedeDP
commented
6 years ago Hi! I'm all for it! I'd give you write access to the repo too but i am not owner/admin. I will probably not working much on slack on the immediate future so i think it can be a good idea; are you willing to step up? :)
Not all substrings of a valid UTF-8 string are themselves valid UTF-8 substrings, but
slack++treats them as such, leading to visual glitches and (possibly) #15.Bug discovered in the course of debugging #14 - more information available there, as well as possible solutions.
Example: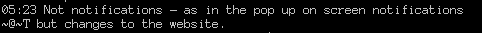
(U+2014 displayed as
~@~T)